


The Great Compute Re-Architecture: Why Branching & Sparsity Will Define the Next Decade of Silicon [Breakdowns]
A Deep Dive into Why the Current AI-Focused Hardware is Failing at Critical Problems and What the US Government is Doing About It.

It takes time to create work that’s clear, independent, and genuinely useful. If you’ve found value in this newsletter, consider becoming a paid subscriber. It helps me dive deeper into research, reach more people, stay free from ads/hidden agendas, and supports my crippling chocolate milk addiction. We run on a “pay what you can” model—so if you believe in the mission, there’s likely a plan that fits (over here).
Every subscription helps me stay independent, avoid clickbait, and focus on depth over noise, and I deeply appreciate everyone who chooses to support our cult.
PS – Supporting this work doesn’t have to come out of your pocket. If you read this as part of your professional development, you can use this email template to request reimbursement for your subscription.
Every month, the Chocolate Milk Cult reaches over a million Builders, Investors, Policy Makers, Leaders, and more. If you’d like to meet other members of our community, please fill out this contact form here (I will never sell your data nor will I make intros w/o your explicit permission)- https://forms.gle/Pi1pGLuS1FmzXoLr6
A special thank you to Gary Grider, Deputy Division Leader of the HPC Division, Los Alamos National Laboratory, for introducing me to this topic. Yes, THAT Los Alamos. Disclaimer- Gary is not responsible for any opinions, analysis, or any subsequent mistakes in this post. All opinions here expressed are mine.
A month and a half ago, I got my hands on some fascinating documents that discussed the limitations of the current computing paradigm for important sectors like Climate Science, Nuclear Fusion, and many other aspects of High Performance Computing and Simulations.
The strategic, financial, and technical implications of these documents were massive, so I spent the last month understanding the domain in more detail.
In this article, we will discuss many important ideas like-
Why the Current Focus on GPUs and Scaling is Fundamentally Misguided for a very important class of AI and Machine Learning problems.
How Structure remains an untapped problem in High Performance Computing, Computing Infrastructure, and AI.
How our current understanding of Sparsity is incomplete.
The design flaws in current chips and what can be done to fix them.
The Market-Making potential of investing in this technology.

Based on some quick, back-of-the-hand math, here is my assessment of these technologies (more details on the investment opportunity, challenges, market sizing etc in the appendix. Appendix is at the end of the article, after the Reach out to Me section)-
Short-Term (1–3 Years): Niche Acceleration & Efficiency Gains. Early adopters who develop or integrate solutions for structural complexity will see significant performance-per-dollar and performance-per-watt improvements in specialized domains. This translates to reduced operational costs for existing complex simulations and the ability to tackle slightly larger problems. The initial value unlocked is in cost savings and incremental capability, potentially a $5–10 billion niche market for specialized accelerators and software.
Mid-Term (3–7 Years): New Product & Service Categories. As these technologies mature, they will enable entirely new classes of simulation and analysis currently deemed impossible. Think hyper-personalized medicine based on complex biological system modeling, novel materials discovery accelerated by orders of magnitude, or truly predictive infrastructure maintenance. This phase unlocks value through new market creation, potentially a $50–150 billion opportunity across various verticals.
Long-Term (7+ Years): Paradigm Shift & Platform Dominance. The architectures and software ecosystems that master structural computation could become the new de facto standard for all complex, data-intensive, non-uniform problems, displacing current leaders in scientific computing and even specialized AI. The long-term value unlocked is platform leadership in a future computing paradigm, a potential multi-trillion-dollar realignment of the entire high-performance and specialized computing market. Please note that this will be a separate market to the existing hardware focuses, and thus chances of cannibalization are low, making this ideal for existing investors in Cloud, Chips, and Compute Infrastructure to open up new revenue streams and improve portfolio diversification.
For a high-level overview of the impact of this research across dimensions, please refer to our trusty table of impacts below.

Fix your hair, slip into something comfy, because we’re going to get VERY intimate with this space.

Executive Highlights (TL;DR of the Article)
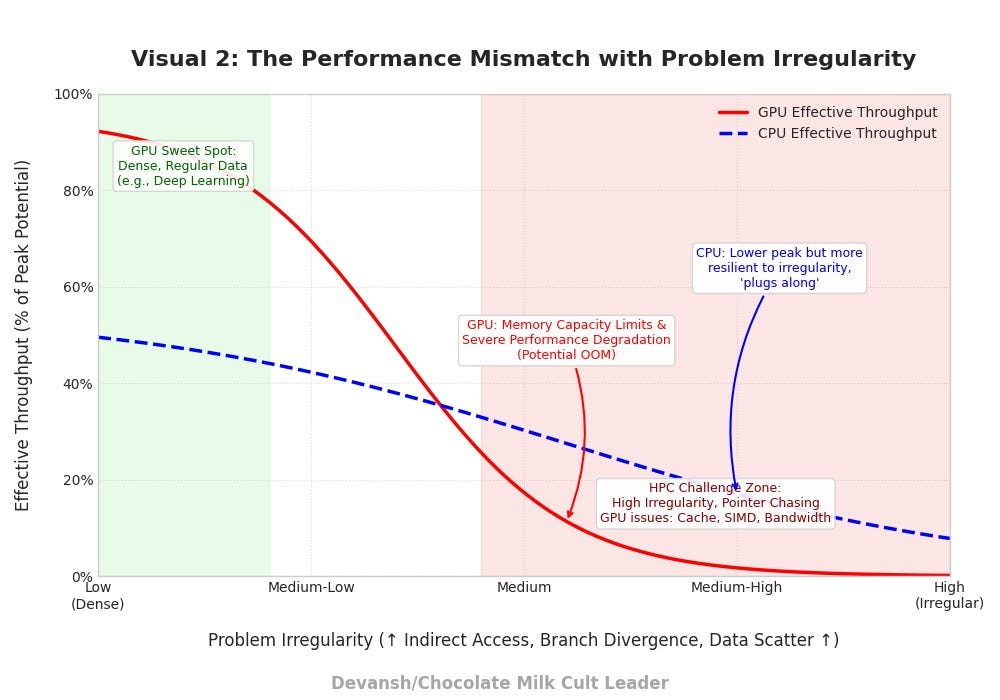
GPUs Aren’t Universal Saviors: Current high-performance computing, heavily reliant on GPUs, excels at tasks defined by dense, regular data and predictable operations (think mainstream AI training). However, for a vast and critical class of problems — spanning national security simulations (LANL), climate modeling, fusion energy, advanced materials science, and next-generation AI — this paradigm is fundamentally breaking down. These chips are not “general-purpose” problem solvers; they are specialized engines for a particular type of math.

The Real Bottlenecks — Structure, Not Speed: The true computational limits for these complex problems aren’t insufficient FLOPs (raw calculation speed). They are:
True Sparsity & Indirect Addressing: This isn’t the neat “pruning” seen in AI. It’s chaotic, pointer-chasing data access where the location of needed data is only revealed at runtime, step-by-step. This makes up a huge chunk of operations in some critical LANL workloads, crippling processors that expect orderly data flow.
Data Locality Catastrophe: The constant jumping around in memory due to indirection renders processor caches largely ineffective and squanders high-bandwidth memory, which is optimized for fetching large, contiguous data blocks.
Branch-Heavy Compute: Real-world physics and complex algorithms are rife with conditional logic (“if-then-else”). On massively parallel architectures like GPUs, where thousands of cores try to execute the same instruction (SIMD/SIMT), branch divergence forces many cores to idle, shattering parallelism. This can account for ~25% of operations.
The Multi-Trillion-Dollar Strategic Blind Spot: The incumbent silicon industry, focused on the immediate rewards of the dense AI market, is largely underinvesting in architectures tailored for this structural complexity. This creates a significant mispricing of capability and opportunity for specialized hardware, software, and integrated solutions. They are optimizing for a subset of problems, leaving a strategic void for those who can tackle the “messy middle.”
The Path Forward — Deep Codesign is Non-Negotiable: Incremental improvements to existing architectures won’t suffice. The solution lies in deep codesign:
Hardware Reimagined: Developing architectures like Processing-in-Memory (PIM) to bring compute to data (e.g., UPMEM), custom RISC-V accelerators with instructions tailored for sparse operations and branch handling (as explored by LANL), intelligent memory controllers, and advanced non-volatile memories (e.g., Numem’s MRAM). Heterogeneous systems combining these elements with general-purpose cores will be key.
Software as the Linchpin: Novel hardware needs a new software stack — sparse-aware compilers (extending LLVM/MLIR), advanced runtime systems, high-level programming models (DSLs), and robust debugging/profiling tools for these heterogeneous, structurally-aware systems.
The Investment & Innovation Frontier:
Key Theses: Arbitraging the “sparsity tax” (performance/energy gains from specialized hardware), enabling new verticals (computational biology, generative materials by solving previously intractable problems), and investing in the crucial “picks-and-shovels” (advanced packaging, software ecosystem tools).
Market Readiness: Commercial PIM is available, RISC-V custom silicon is gaining traction (evidenced by LANL’s prototyping), and the need for solutions is acute in strategic sectors, de-risking early investment.
The Broader Implications — Reshaping Technology & Geopolitics: Mastering structural compute will not only drive scientific breakthroughs but also redefine AI model architectures (enabling more complex, dynamic, and potentially more efficient models like next-gen Diffusion), reshape the semiconductor industry, and become a cornerstone of national technological sovereignty.
In Essence: The current computational paradigm is hitting a wall defined by structural complexity. The future belongs to architectures and ecosystems co-designed to embrace sparsity, indirection, and branching. This isn’t just an academic pursuit; it’s a fundamental shift with profound implications for investors, technologists, and global power dynamics. This article deconstructs the problem from first principles and outlines the emerging solutions and opportunities.
I put a lot of work into writing this newsletter. To do so, I rely on you for support. If a few more people choose to become paid subscribers, the Chocolate Milk Cult can continue to provide high-quality and accessible education and opportunities to anyone who needs it. If you think this mission is worth contributing to, please consider a premium subscription. You can do so for less than the cost of a Netflix Subscription (pay what you want here).
I provide various consulting and advisory services. If you‘d like to explore how we can work together, reach out to me through any of my socials over here or reply to this email.
Section 2: What Modern Computing Gets Wrong about High Performance Computing- GPUs and Sparsity
Let’s start with a myth: that today’s chips — particularly GPUs — are “general-purpose” compute powerhouses.
They’re not. They’re matrix multiplication engines, built to push dense, regular tensors through repeatable operations as fast as possible. That’s what modern AI models need, and they’ve been astonishingly effective at it.
But outside deep learning, the world is a mess. A giant, Manchester United Class, mess. It’s sparse. It’s conditional. (We will talk about both terms in more detail). It branches, jumps, skips, and re-enters. It has wild mood swings, gets mad at you for not texting every day (I don’t need to hear about your day, EVERY. SINGLE. DAY), yo-yos in and out of your life like it was Bivol’s pendulum step…

And when you try to run those kinds of problems—problems rooted in physical systems, chaotic data flows, unstructured geometry on today’s dominant architectures, the entire abstraction collapses.
This is our core delulu: we’ve mistaken computational intensity for computational suitability.

This is reflected in how most AI (myself included) have defined Sparsity in a very narrow, and not particularly useful, way. Let’s discuss that next.
Section 3.1 The Menace that is Sparse Computing
A Look at Sparsity
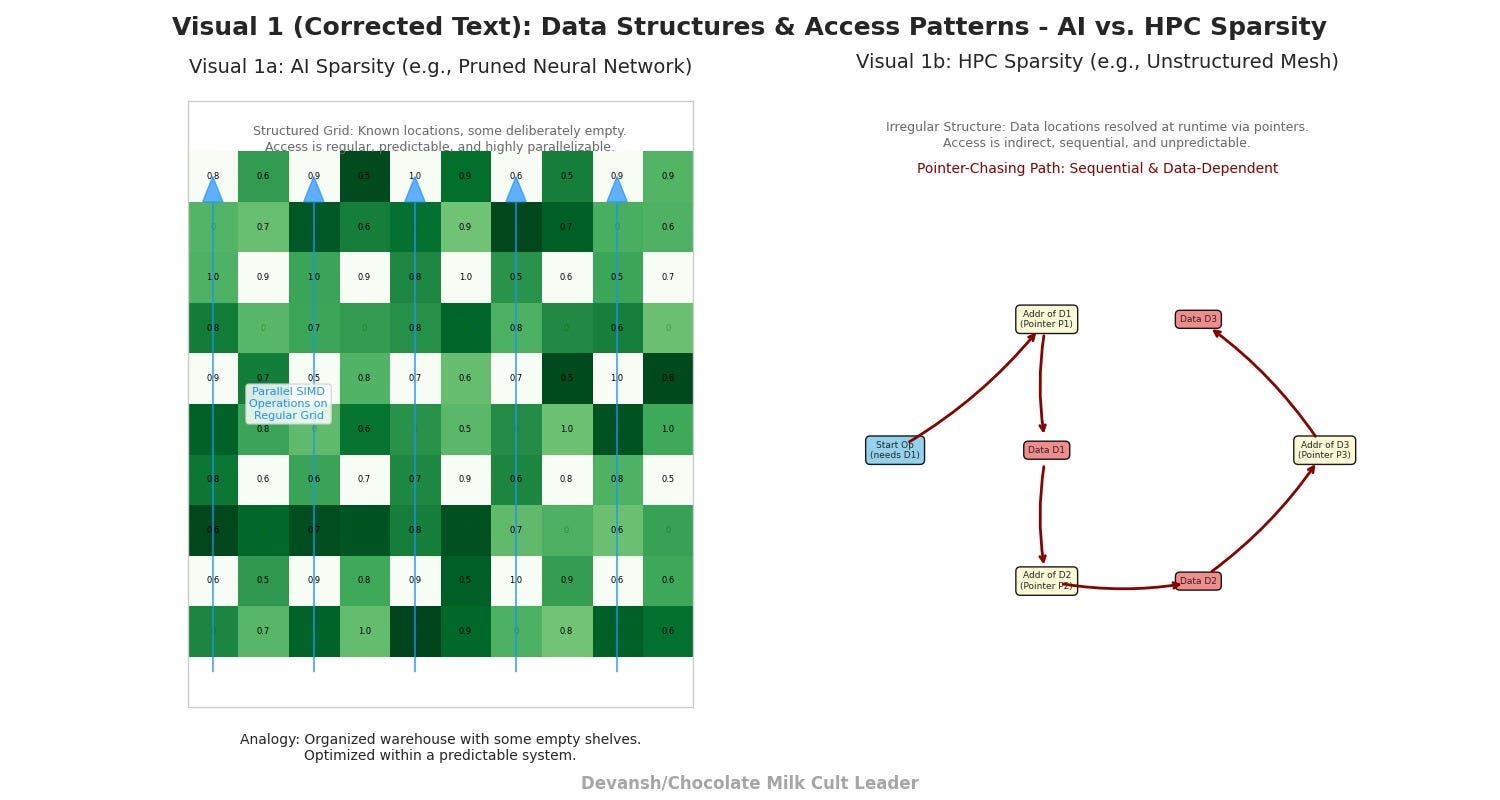
AI “sparsity,” in its common usage, is largely about reducing the number of active calculations within an otherwise regular and predictable data structure. Imagine a vast spreadsheet where many cells are zero.
The Structure is Known: You still have a grid. You know where every cell could be.
Access is (Relatively) Orderly: Even if you’re skipping cells, you’re often moving through this grid in a somewhat orderly fashion.
Work is Parallelizable: If you have many such spreadsheets (a “batch” in AI terms), and you need to perform the same operation on all the non-zero cells, you can assign many workers (processor cores) to the task simultaneously, each working on their own spreadsheet or a section of it. This is highly compatible with SIMD (Single Instruction, Multiple Data) processing — the architectural heart of a GPU. SIMD means one instruction (“add these two numbers”) is applied to many different pieces of data at the exact same moment. Think of it as a coach telling your entire team to run the same drill simultaneously.
AI “sparsity” is like having a meticulously organized warehouse where some shelves are deliberately left empty. It saves storage and some effort, but navigating the warehouse itself is still straightforward. It’s an optimization within a predictable system.
Now, let’s contrast this with the foundational structural challenges that arise in simulating the universe’s most complex, dynamic systems — the kind of problems tackled by institutions like Los Alamos National Laboratory for national security, or by researchers modeling climate change or seeking to unlock fusion energy. Here, we encounter something far more fundamental than just “many zeros in a known grid.” We encounter true structural complexity, primarily manifesting in three ways:
Pointer-chasing sparsity: You don’t know what data you need until runtime.
Multi-level indirection: Arrays of arrays of arrays, with conditionals between them.
Branch-heavy compute: Every thread might take a different path.
We will now take a second to understand the problems this creates.
Principle 1: The Tyranny of Indirect Data Access
Imagine you’re trying to assemble a complex machine, but the instruction manual is written strangely. Step 1 tells you to find “Part A.” Inside the box for Part A, instead of the next assembly step, you find a note telling you the location of “Part B.” Inside Part B’s box, there’s a note for Part C’s location, and so on. You spend most of your time finding the next part rather than actually assembling anything.
This is indirect addressing. The data you need for a calculation (say, the properties of a specific point in a simulated explosion) isn’t stored directly. Instead, you have a pointer — an address — that tells you where to find another pointer, which might lead to yet another pointer, before you finally arrive at the actual data.
Why does this happen?
Unstructured Meshes: Many simulations don’t use neat, regular grids. They use “meshes” where points and connections are arranged irregularly to better conform to complex shapes (like a turbine blade or a deforming object). To find data related to a neighbor of a point, you might have to look up that neighbor’s ID in a list, then use that ID to find its data in another list.
Sparse Matrices (Real-World): When modeling interactions in vast systems (like atoms in a material or nodes in a network), most elements don’t directly interact with most other elements. This results in “sparse matrices” where useful data is scattered. Finding interacting pairs involves navigating these sparse structures.
Adaptive Mesh Refinement (AMR): In many simulations, like a shockwave moving through a medium, you need high detail in some areas and less in others. The computational grid itself adapts during the simulation — regions “refine” (become denser) or “coarsen.” Data for a point might move, or its neighbors might change, necessitating these indirect lookups to keep track of the evolving structure.
The Consequence? Your processor spends an enormous amount of time chasing these pointers through memory before it can do any actual “useful” computation (the FLOPs). As LANL’s data reveals, for their critical simulations, a staggering 60% of all instructions are memory and integer operations, predominantly these indirect load/store operations. This isn’t a small overhead; it’s the dominant activity. The actual floating-point calculations are a minority.

Principle 2: The Challenge of Data Locality. AKA Why Your Cache is Often Useless
Modern processors are incredibly fast. Main memory (RAM), while large, is relatively slow. To bridge this gap, processors use small, ultra-fast memory caches. The idea is simple: if you access a piece of data, you’ll probably need it again soon, or you’ll need data located nearby. So, the processor pulls that data and its neighbors into the cache.
When Caches Work: For problems with good spatial locality (accessing nearby data) and temporal locality (reusing the same data), caches are miracle workers. This is common in dense matrix math, where you sweep through arrays. One of the best techniques (that most people still don’t use) in LLMs is to use caching — which gets you very good rates and latency.
When Caches Fail (Real Sparsity): With extreme indirect addressing, the data you need next could be anywhere in memory. The piece of data pointed to by Pointer A might be megabytes away from the data pointed to by Pointer B (which you only discover after fetching Pointer A). There’s no spatial locality. And you might only use each piece of indirectly accessed data once before moving on, so temporal locality is also poor.
The Result: The cache is constantly being “thrashed.” Data is pulled in, not used effectively, and then evicted to make room for other data that will also likely be poorly utilized. LANL’s analysis of their workloads shows “very poor utilization for floating point load/stores” in cache, precisely because these FP operations often depend on prior, scattered, indirect memory accesses to determine which FP data to load.
Both of these mean that GPUs are well…. inadequate.
The GPU Misconception for Structurally Complex Problems
Now, let’s bring in the Graphics Processing Unit (GPU). GPUs are marvels of parallel computation, designed with thousands of relatively simple cores.

Their architecture is built on a few key principles that make them phenomenally successful for tasks like graphics rendering and mainstream AI (which, as we discussed, often involves operations on dense, regular data, even if “pruned”):
Massive Parallelism (SIMD/SIMT): GPUs excel when they can give the same instruction (or a very similar set of instructions, SIMT — Single Instruction, Multiple Threads) to thousands of cores to execute simultaneously on different pieces of data.
High Bandwidth Memory (HBM): GPUs are connected to extremely fast, wide memory. This is crucial for feeding their thousands of hungry cores. However, this bandwidth is most effective when data is accessed in large, contiguous, predictable chunks — like streaming pixels for a screen or rows/columns of a dense matrix.
Throughput Orientation: GPUs are designed to maximize overall throughput — the total amount of work done per unit of time — rather than minimizing the latency (delay) of any single operation.
This is great, but it leads to a mismatch with Real Sparsity & Branching:
Indirect Addressing Kills SIMD Efficiency: If each of your thousands of “threads” on a GPU needs to chase a different chain of pointers to find its data, they can’t all execute the same memory access instruction in lockstep. Many threads will stall, waiting for their unique memory fetches. The massive parallelism is underutilized.
Scattered Accesses Cripple Memory Bandwidth: Fetching thousands of tiny, non-contiguous pieces of data from random memory locations is the least efficient way to use high-bandwidth memory. It’s like trying to fill a swimming pool with thousands of individual eyedroppers instead of a firehose. The effective bandwidth plummets. One of the most interesting tidbits I picked up was that for certain kinds of high-memory sparse compute tasks, GPUs collapse while CPUs eventually get something-

Data Dependencies Create Sequential Bottlenecks (Amdahl’s Law): The “result of A is needed for B, result of B for C” nature of pointer chasing and conditional branching (which we’ll explore more deeply in the next section on branching) creates inherently sequential parts of the code. Amdahl’s Law dictates that no matter how many parallel processors you throw at a problem, the speedup is ultimately limited by these serial portions. GPUs, with their emphasis on extreme parallelism, hit this limit hard and fast with structurally complex codes.
When LANL scaled their simulations on GPU-heavy systems, the observed performance collapse (e.g., the PartiSN code’s diminishing returns) and memory issues (OOM on sparse tasks) weren’t due to a lack of raw FLOPs on the GPUs. They were direct consequences of these fundamental mismatches: the GPU architecture, optimized for dense, predictable parallelism, struggles profoundly when faced with the chaotic data access patterns and inherent sequential dependencies of truly sparse, structurally complex problems.
In other words, you haven’t hit a “hardware power” limit. You’ve encountered a deep, first-principles architectural incompatibility. The tool is simply not designed for the nature of the task at hand when that task is defined by navigating an uncharted, ever-changing labyrinth of data.
Sorry bros: sometimes they didn’t leave you b/c you weren’t tall/rich/attractive enough. Sometimes, they leave b/c you’re a deeply inadequate and unlovable person. Doubling down on more of you and what you have won’t fix anything. You need a complete rebuild, inside out.

Our worries don’t end here. Let’s meet the second member of this dynamic duo; the Nan Hao, to our Shang Feng.
Section 3.2 The Terror Known as Branching
Branching is simple to understand but deceptively difficult to master. At its core, branching is about decision-making. If your code looks like this:
if (condition)
do A;
else
do B;You have branching (insert joke about how all AI is if-else loops to bait likes from unoriginal hacks that have nothing creative to say).
These “if-then-else” or “while-do” constructs are the bread and butter of simulating complex, dynamic systems. The physics itself is conditional. Particle paths diverge based on interactions. Material properties change. Adaptive algorithms make decisions at runtime.
But why does something so basic cause such catastrophic failures for modern hardware — particularly GPUs?
Because branching represents fundamentally unpredictable, non-uniform computation paths. In other words, your neatly arranged, parallel-processing wonderland quickly devolves into computational chaos.
Let’s break this down clearly from first principles:
Why Branching Cripples Massively Parallel Architectures (like GPUs):
Recall that GPUs derive their immense power from SIMD (Single Instruction, Multiple Data) or its close cousin SIMT (Single Instruction, Multiple Threads). Thousands of cores are designed to execute the same instruction at the same time, just on different pieces of data.
Now, introduce a conditional branch that many of these threads encounter simultaneously:
Divergence: Some threads will satisfy the “IF” condition (e.g., their particle’s energy is above threshold X) and need to execute the “THEN” block of code. Other threads will not satisfy the condition and need to execute the “ELSE” block (or skip to whatever comes after the IF-THEN-ELSE).
Serialization within a Warp/Wavefront: GPUs group threads into small units (often called “warps” or “wavefronts,” typically 32 or 64 threads). If threads within the same warp diverge (some go THEN, some go ELSE), the GPU hardware often has to handle this by serializing their execution.
First, all threads that need to execute the “THEN” path do so, while the “ELSE” threads in that warp wait (are masked off, effectively idle).
Then, all threads that need to execute the “ELSE” path do so, while the “THEN” threads (which have already finished their part) wait.
Lost Parallelism: The fundamental benefit of SIMD — everyone doing the same useful work simultaneously — is lost for those diverging branches. A significant fraction of your cores within that warp are sitting idle for a portion of the time. If the “THEN” and “ELSE” paths are very different in length or complexity, the inefficiency is even worse.
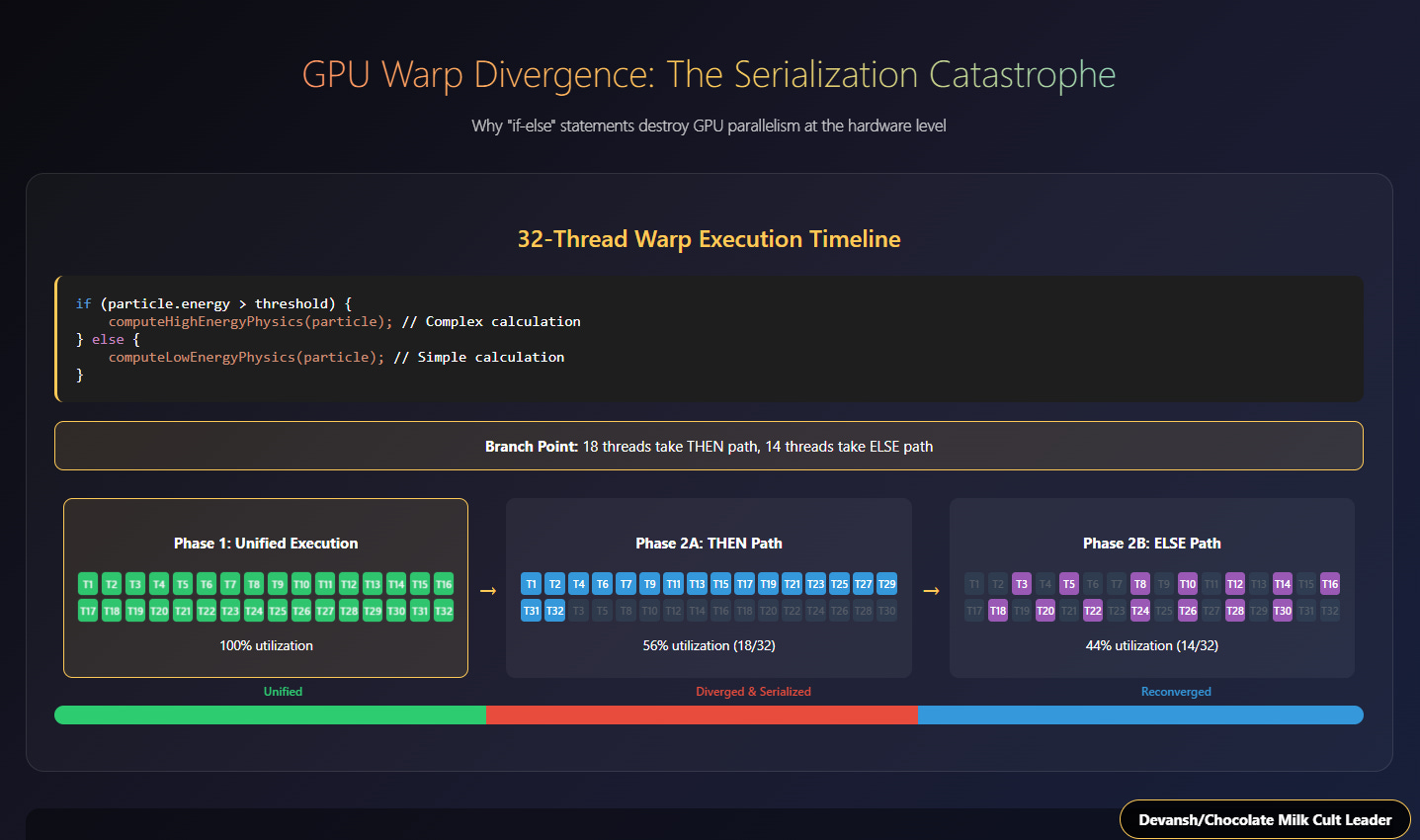
Control Flow Overhead: Managing this divergence, masking threads, and reconverging them after the conditional block adds extra control logic and overhead, further eating into performance.
The Scale of the Problem in Real Simulations:
This isn’t a minor, occasional inconvenience. In the complex simulations run at places like LANL, conditional instructions can account for a very significant portion of all operations. Their data shows branching instructions alone making up 16% of operations, with another 9% being explicit conditional operations, totaling 25%. One quarter of all computational effort involves navigating these decision points.

When you combine this high frequency of branching with:
The fine-grained nature of the parallelism on a GPU (thousands of tiny threads).
The desire to keep all those threads busy with useful work.
You get a recipe for performance degradation. Each conditional branch encountered by a warp becomes a potential point of serialization and lost efficiency. Multiply this by thousands of warps and billions of operations, and the cumulative impact is enormous.

CPUs vs. GPUs in Handling Branches:

Traditional CPUs, while having far fewer cores, are architecturally much better equipped to handle branching:
Sophisticated Branch Prediction: CPUs invest a lot of silicon in predicting which way a branch will go (e.g., will the “IF” be true or false?) before the condition is actually evaluated. If they predict correctly, they can start executing instructions down that path speculatively, avoiding stalls.
Out-of-Order Execution: CPUs can reorder instructions dynamically to find useful work to do even if some instructions are waiting on the results of a branch or a slow memory access.
Fewer, More Powerful Cores: With fewer, more independent, and more complex cores, the penalty for one core taking a different path is less impactful on overall system throughput compared to idling a significant fraction of a GPU’s thousands of simpler cores.
This doesn’t mean CPUs are immune to branching penalties, but their design philosophy has always prioritized handling complex control flow more gracefully. GPUs, born from the highly regular world of graphics rendering, prioritized massive data parallelism, accepting a trade-off in complex control flow efficiency.
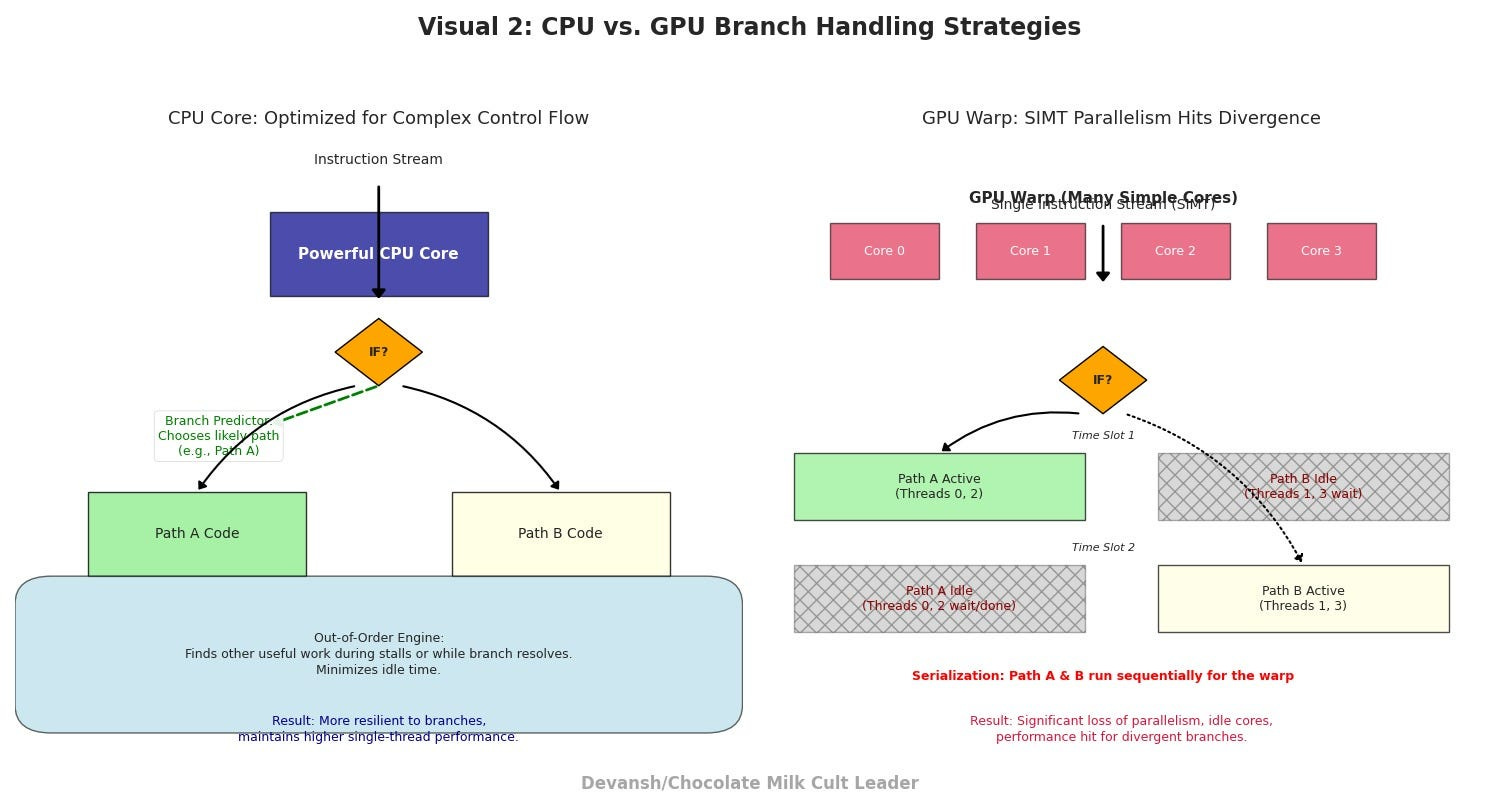
A Sneak Peek: What a Branch-Aware Future Looks Like
Addressing branching isn’t a matter of tweaking GPUs. It’s a fundamental, architectural pivot:
Heterogeneous Architectures: A mix of general-purpose CPUs for branching-heavy logic and custom accelerators for well-defined compute tasks.
Branch-Prediction Innovations: Hardware-level optimizations specifically targeting conditional logic efficiency — improved prediction and speculation methods tailored for structurally complex workloads.
Control-Flow Optimization Compilers: Software toolchains that proactively manage branching complexity — compilers that aggressively optimize branch-heavy code into structures suitable for modern silicon.
Co-Designed Silicon & Software: Chips designed hand-in-hand with software toolchains, allowing deep integration and radically reduced branching overhead.
Branching isn’t just another “feature” to optimize. It’s the central architectural constraint for tomorrow’s critical workloads.
Let’s end this section by reiterating the most important ideas we’ve discussed so far-
Strategic Reality Check:
We aren’t running out of FLOPs — we’re hitting fundamental architectural limits imposed by branching.
Investment focused solely on GPU-centric data centers for structurally complex workloads is a strategic mistake — a multi-billion-dollar misallocation.
The winner in the next wave of computing won’t simply have bigger clusters — they’ll have architectures fundamentally optimized for branching and decision-rich computation.
If your workload is branch-heavy, more GPUs won’t save you — they’ll drown you. Throwing more GPUs at structurally complex workloads is equivalent to buying a faster car to escape rush-hour gridlock. Your fundamental constraint isn’t horsepower — it’s the traffic jam itself.
The next era in computing dominance won’t be defined by more FLOPs — it will belong to those who fundamentally restructure silicon and software to embrace branching complexity head-on. This is why we’ve earmarked Diffusion Models as the Model for the future Language/Multimodal Models — since they can incorporate ideas like branching and complex evaluations natively in their generation steps.

Section 4: Structurally-Aware Computing as the Next Investment Frontier
The chip industry has spent decades optimizing around a single, dominant axis: dense computation. Whether it’s GPUs powering deep neural networks or CPUs handling enterprise software, silicon innovation has almost exclusively targeted predictable workloads.
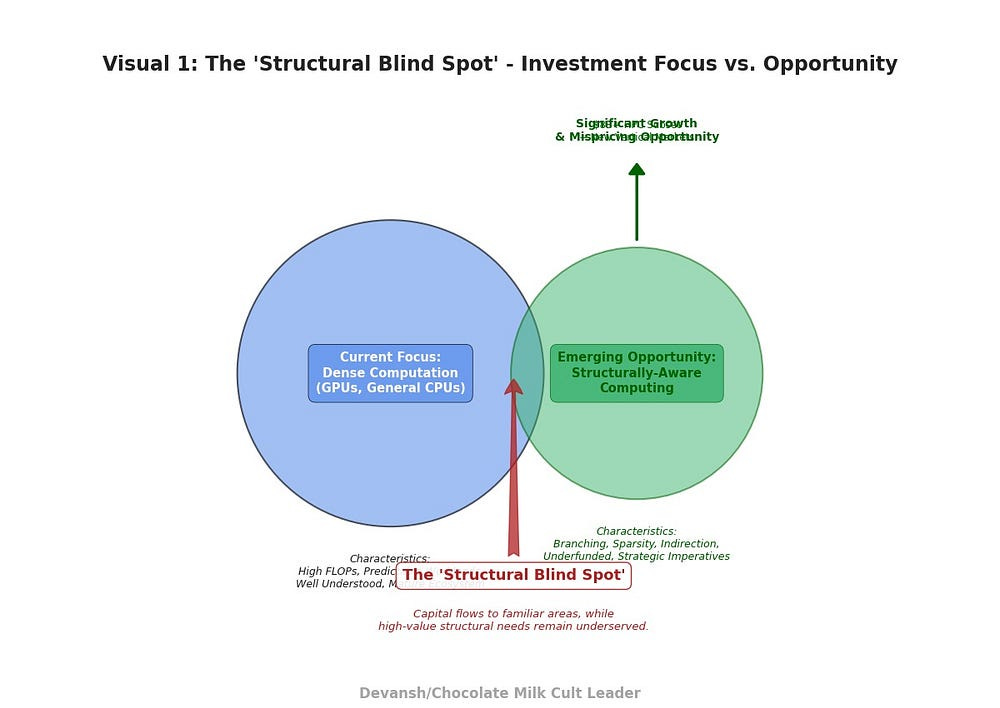
But predictability is no longer guaranteed. The world’s most critical upcoming computational tasks — real-time climate models, hyper-personalized medicine, advanced engineering simulations, predictive infrastructure management — demand silicon optimized explicitly for structural complexity.
Let’s explicitly unpack this strategic blind spot in today’s silicon landscape — and outline the immense investment and competitive opportunities hiding in plain sight.
Real Money Left on the Table: The Mispricing Opportunity (Refer to Appendix for numbers and calculations)
Markets operate on what they can measure and understand. The current computational paradigm — dense linear algebra, batch-friendly parallelism — fits neatly into investors’ comfort zones.
But here’s the reality check:
Specialized HPC alone (just the structurally complex subset) will soon approach an $8 billion+ annual spend, growing at double-digit rates through 2034.
Vertical-specific computational breakthroughs (drug discovery, generative materials, digital twins) are forecasted to become multi-billion-dollar markets within five to ten years.
Strategic national imperatives (fusion energy, nuclear security, critical infrastructure resilience) ensure guaranteed early adoption, de-risking long-term capital-intensive bets.
Yet, investor capital still disproportionately flows toward GPU-heavy data centers or general-purpose CPUs. The structurally complex domain remains shockingly underfunded — an asymmetry waiting to be exploited by early movers.

How to Exploit Silicon’s Structural Blind Spot:
Explicitly, here’s how investors can position themselves to capture this massive, mispriced opportunity:
Thesis 1: Invest in Structural Silicon Pioneers
Companies developing processing-in-memory (PIM): Commercial hardware from UPMEM, Numem, and similar ventures is already outperforming GPUs/CPUs by substantial margins on pointer-heavy workloads.
Emerging RISC-V accelerators: RISC-V-based co-designed chips, particularly from national labs and specialized startups, offer customizable hardware specifically tuned to branching and memory-indirection patterns.
Thesis 2: Strategic Picks-and-Shovels Opportunities
Advanced packaging and integration specialists: Investments in heterogeneous integration (chiplets, 3D stacking, interposers) will thrive. Companies providing critical IP (like TSMC’s CoWoS, Intel’s EMIB, and Foveros), tooling, or test & verification capabilities stand to disproportionately benefit.
Thesis 3: Software and Ecosystem Enablers
Compiler innovation firms: Companies developing sparse-aware compilers (LLVM, MLIR extensions), branch-prediction software optimizations, and advanced runtime environments that handle sparse, branch-intensive code efficiently will capture outsized value as integrators.
Domain-specific software platforms: Computational biology platforms, generative materials design tools, or predictive infrastructure software — built explicitly to leverage structurally-optimized silicon — will become category-defining.
Strategic Barriers to Competitors (Why Now Matters)
Competitors can’t simply pivot overnight:
Incumbent inertia: Dominant GPU providers have deeply embedded ecosystems optimized for dense workloads, making rapid pivot difficult and costly.
Complex co-design requirements: Structural complexity isn’t solved by hardware alone. It requires deeply integrated silicon-software-algorithm co-design — creating natural barriers to late entrants.
Long lead times: Genuine structural silicon innovation requires sustained investment, deep technical expertise, and iterative refinement cycles. Latecomers won’t easily catch up.
Early strategic positioning, therefore, doesn’t just provide first-mover advantage; it creates robust defensive moats — exactly what investors seek for durable, long-term returns.
How Non-Technical Decision Makers Should Capitalize on Structurally-Aware Computing
The structurally-aware computing era isn’t a question of if, but when — and how quickly smart capital moves.
Investors: Move early, build positions explicitly in structural-compute hardware, software, and advanced packaging pioneers.
Policymakers: Prioritize funding and incentives explicitly around structurally complex computing as strategic national infrastructure.
Silicon industry leaders: Begin immediate diversification toward structure-aware architectures and ecosystems or risk disruption from startups explicitly optimized for these emerging workloads.
The current GPU-driven compute landscape isn’t incorrect — it’s incomplete. Correctly positioned investments made explicitly in structurally aware computing today will define market leadership in tomorrow’s dominant computational paradigm.
Simply raising negatives isn’t particularly useful to anyone. So let’s explore the solutions that we can develop to take a proactive role in building the future.

Section 5: Codesign or Collapse — Building the Next Compute Paradigm
“In this article, we have presented the two root challenges of sparsity and branching exhibited by nuclear security applications. Broader market forces are pushing technologies away from a solution space to these challenges. Addressing this divergence could take a number of paths. Relying upon advances in general purpose processing alone will result in continued diminishing improvements in simulation capabilities, effectively freezing our capabilities in this decade. Moving our applications to technologies that are driven by the broader market has thus far shown only marginal improvements at the scale at which our most complex applications must run. Developing entirely new methods that better map to technology driven by the broader market can take a decade or longer to make their way into production multiphysics codes and it is unclear if new methods will yield significant improvements at scale. Future advances in computational capabilities for nuclear security and the U.S. will therefore require a deeper level of co-design that focuses on tailoring and specialization of computing hardware alongside algorithmic advances. Forward progress in this regard will be governed by our ability to do this in an agile and coordinated way spanning national laboratories, academia, and industry.”
-From a Report I got my hands on
We’ve established clearly that the future of computing isn’t about brute-force scale; it’s about intelligently managing structural complexity. But recognizing this blind spot isn’t enough — investors, policymakers, and technologists must explicitly understand how structure-aware computing architectures will emerge and evolve.
To seize this strategic opportunity, silicon, software, and algorithms must be co-designed explicitly around branching and sparsity from the ground up.
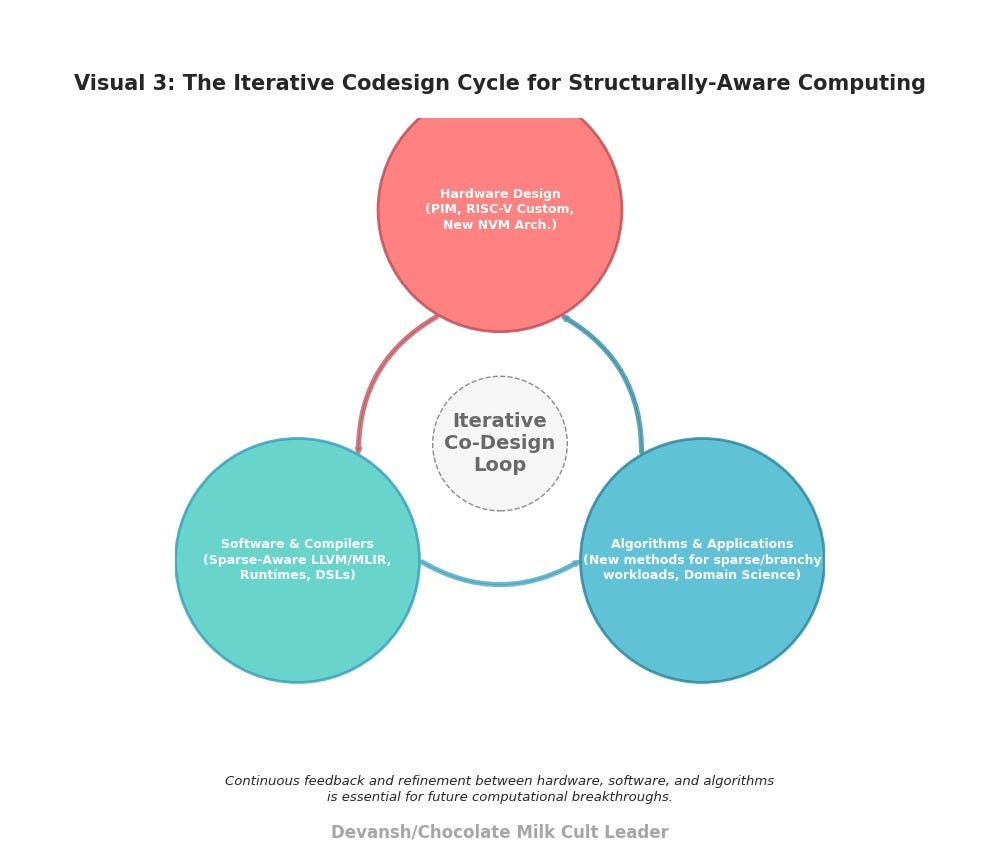
Here’s exactly how it unfolds.
Emerging Architectures:
Several architectural trends are coalescing to address these specific pain points (indirect data access, poor locality, and branch divergence):
Processing-in-Memory (PIM) — Bringing Compute to the Data:
The Principle: For decades, the von Neumann architecture has dictated a separation: processing units (CPUs, GPUs) here, memory over there, with a relatively narrow bus in between. For structurally complex problems where data movement dominates, this is a recipe for disaster (as highlighted by the “memory wall” and energy consumption figures in our Appendix).
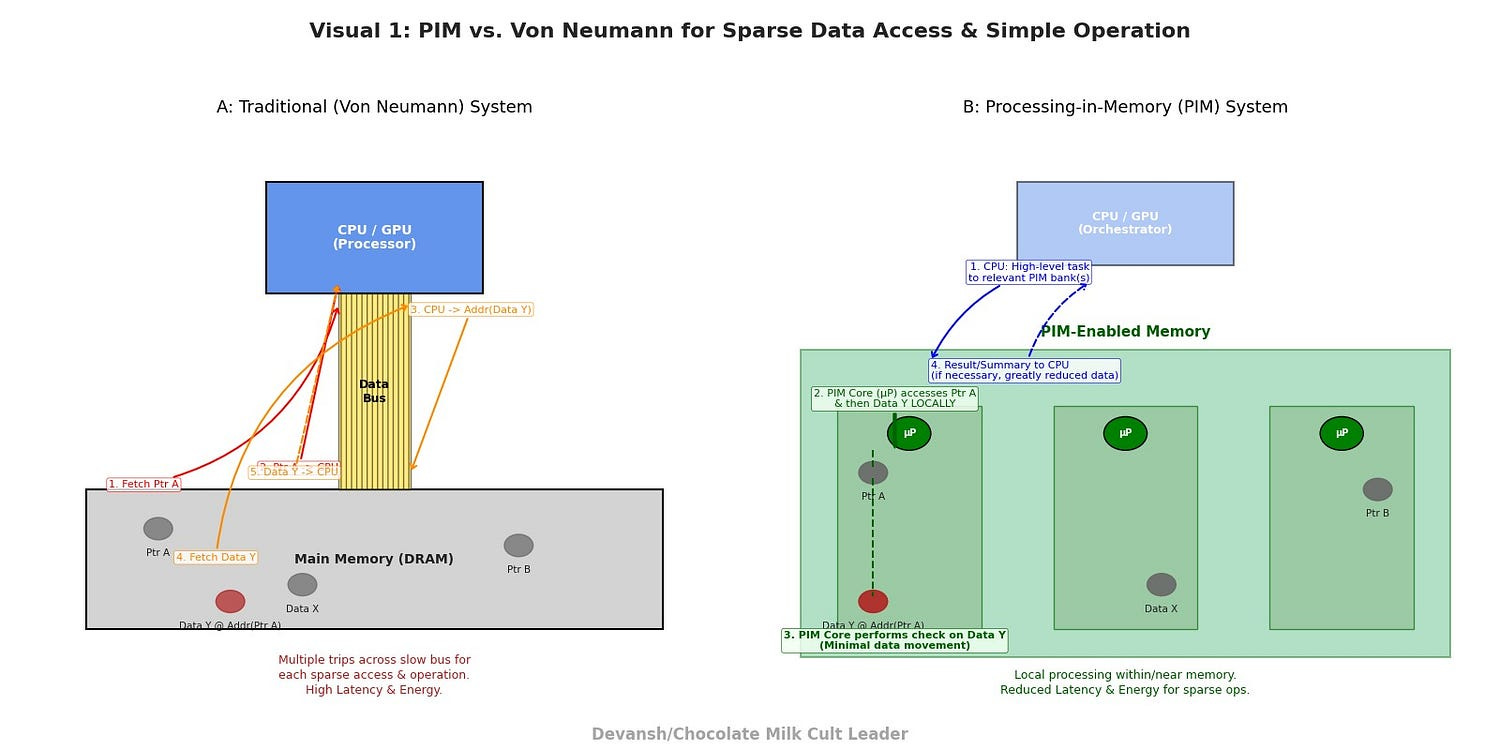
PIM flips this on its head by integrating computational logic directly within or very near memory cells.
How it Addresses Sparsity/Branching:
Reduced Data Movement: By performing simple operations (e.g., comparisons, bitwise logic, simple arithmetic, even pointer dereferencing for certain PIM types) directly where data resides, the costly journey to and from a central processor is minimized or eliminated for many fine-grained, scattered accesses. This directly attacks the latency of indirect addressing and the energy cost of data movement.
Massive Parallelism for Local Operations: PIM can enable thousands or even millions of simple processing elements to operate in parallel on data locally within memory banks. This can be highly effective for tasks like searching sparse data structures or performing simple conditional updates across many disparate data points.
Technological & Market Readiness: This isn’t science fiction.
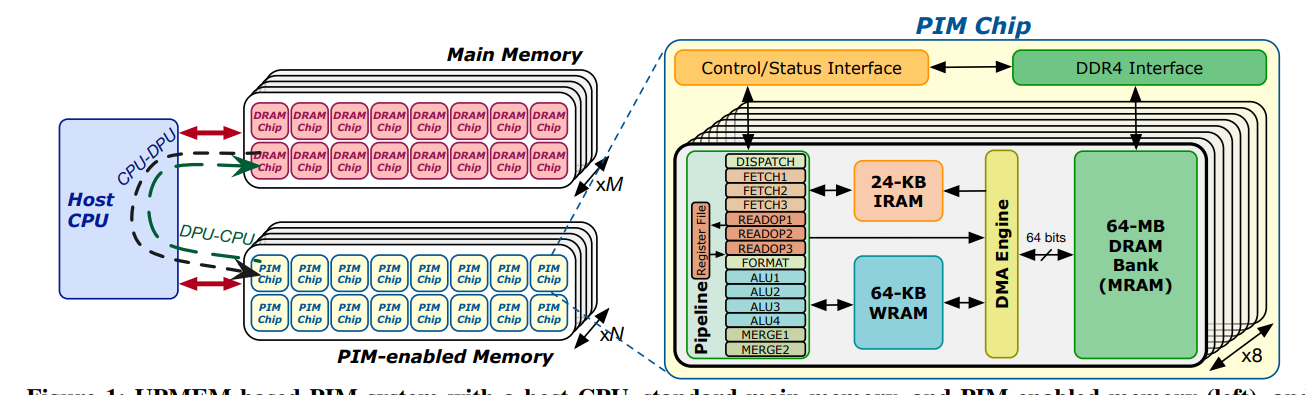
UPMEM (taken over by Qualcomm): This French company has commercially available PIM modules that integrate general-purpose RISC-V cores (DPUs — DRAM Processing Units) onto standard DDR4/DDR5 DIMMs. They’ve demonstrated significant speedups (orders of magnitude in some cases) and energy reductions for workloads like sparse graph analytics, bioinformatics sequence alignment, and database indexing — all problems rich in indirect access and conditional logic. Their success provides tangible proof of PIM’s viability for specific classes of structurally complex tasks.

Other research and commercial efforts are exploring different PIM paradigms, from near-memory accelerators to logic embedded deeper within memory arrays.
RISC-V Based Custom Accelerators & Heterogeneous SoCs — The Power of Open, Agile Specialization:
The Principle: The open-source RISC-V instruction set architecture (ISA) has democratized silicon design. It allows teams to create highly specialized processor cores and accelerators tailored to specific workloads without the heavy licensing fees and black-box nature of proprietary ISAs. This enables targeted solutions for structural complexity.

How it Addresses Sparsity/Branching:
Custom Instructions for Indirection/Control Flow: Designers can add custom instructions to a RISC-V core specifically to accelerate common sparse operations (e.g., efficient gather/scatter, address generation for AMR) or to handle complex branch patterns more effectively.
Tailored Memory Hierarchies: Custom RISC-V SoCs (Systems-on-Chip) can implement unique cache designs, scratchpad memories, or direct memory access (DMA) engines optimized for the specific memory access patterns of their target sparse/branching workloads, rather than relying on generic cache coherency protocols.
Heterogeneous Integration: RISC-V cores are ideal for integration into larger SoCs as specialized co-processors alongside general-purpose CPUs or even GPUs. The CPU handles complex control flow and serial code sections, while the RISC-V accelerator tackles the structurally complex kernels it was designed for.
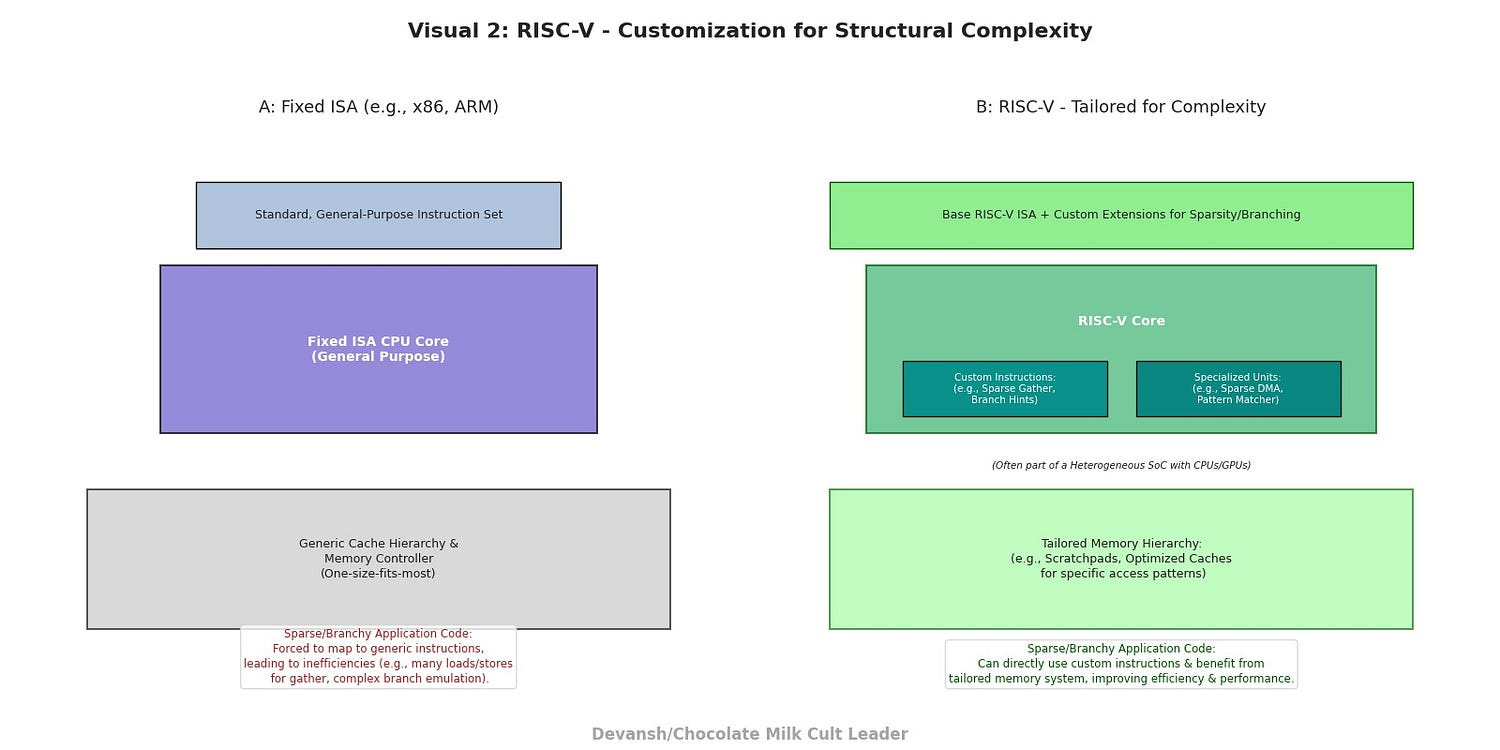
Technological & Market Readiness: Los Alamos is actively using RISC-V (Chipyard, BOOM, RoCC extensions) to prototype “Sparse Memory Accelerators” and “Gather Engines.” This demonstrates that leading-edge research institutions see RISC-V as a viable path for creating bespoke hardware for their most demanding, structurally complex national security workloads. Their projected “2031 system” heavily implies the maturation of such custom silicon.

A growing ecosystem of RISC-V IP providers, design tool vendors, and startups are making custom silicon development more accessible.
Advanced Non-Volatile Memories (NVMs) with Compute Potential (e.g., MRAM):
“Based on upon standard MRAM production processes, Numem’s patented NuRAM memory enables best in class power, performance and reliability with 2.5x smaller area and 85x-2000x lower leakage power than traditional SRAM. Combined with SmartMem SOC subsystem, it enables SRAM like performance and/or ease-of-use by enabling significant performance and endurance improvement, a comprehensive adaptive memory management along with optional and customizable SOC Compute in Memory.”
The Principle: Emerging memory technologies like Magnetoresistive RAM (MRAM) offer a compelling combination of non-volatility (data persists without power), high density, and, crucially, the potential for certain types of in-situ or near-memory computation.
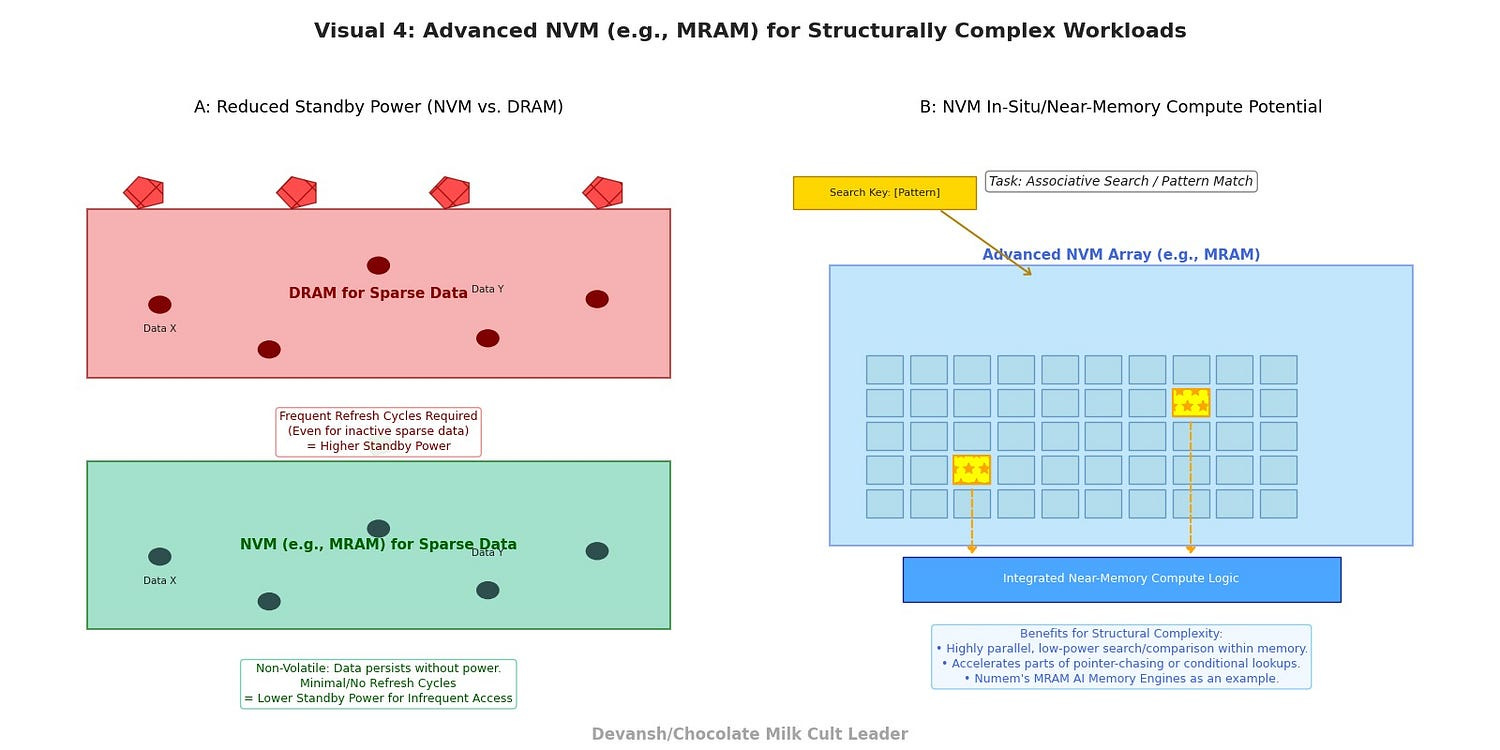
How it Addresses Sparsity/Branching:
Reduced Standby Power: For problems with very sparse, infrequently accessed data, NVMs can reduce power consumption compared to constantly refreshing DRAM.
Potential for Analog/Stochastic Compute for Search/Comparison: Some NVMs have physical properties that lend themselves to highly parallel, low-power analog computations useful for tasks like associative search or pattern matching within sparse datasets, which can accelerate parts of pointer-chasing or conditional lookups.
Technological & Market Readiness:
Numem: This company is developing MRAM-based AI Memory Engines, explicitly targeting the memory bottleneck with significantly lower power. While initially focused on AI, the underlying benefits for data-intensive, low-power operation have implications for broader structurally complex workloads where memory access dominates. Their claim of being “foundry-ready” indicates approaching commercial viability for their specific MRAM technology.
The MRAM market is projected for significant growth, indicating increasing manufacturing maturity and adoption.
The Linchpin: Software, Compilers, and the Ecosystem
Novel hardware, no matter how brilliant, is useless without a software ecosystem that can effectively harness its power. This is arguably the most critical and often underestimated component of realizing the potential of structurally-aware computing.
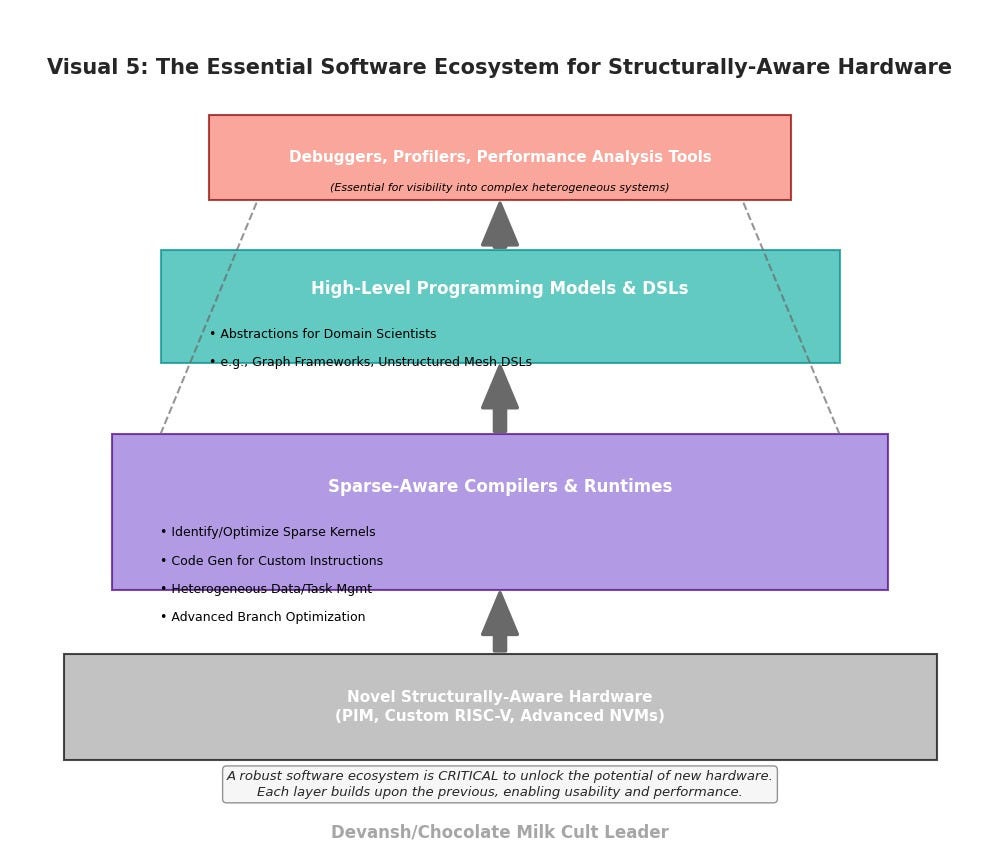
Sparse-Aware Compilers & Runtimes:
The Challenge: Existing compilers (LLVM, GCC) are highly optimized for general-purpose CPUs and, to some extent, GPUs. They often lack sophisticated understanding of sparse data structures, indirect addressing patterns, or how to optimally schedule code for heterogeneous systems with PIM or custom accelerators.
The Need: We require compilers that can:
Automatically identify and optimize sparse computation kernels.
Generate efficient code for custom instructions on RISC-V accelerators.
Manage data movement and task scheduling across heterogeneous memory systems (DRAM, HBM, PIM, NVM).
Aggressively optimize branch-heavy code, perhaps through advanced predication, speculative execution tailored for these architectures, or code transformations.
LANL’s Focus: Their work with “Application and frameworks codesign (FleCSI, Kokkos, LLVM, MLIR)” underscores their recognition of this critical software layer. Efforts to extend LLVM/MLIR for sparse tensor algebra and custom hardware targets are vital.

High-Level Programming Models & DSLs (Domain-Specific Languages):
The Challenge: Asking domain scientists to write low-level code for PIM or custom RISC-V instructions is not scalable.
The Need: Abstractions are needed — libraries, frameworks, or DSLs — that allow programmers to express structurally complex algorithms in a natural way, while the underlying compiler and runtime system handle the mapping to specialized hardware. Examples include graph programming frameworks that can target PIM, or DSLs for unstructured mesh computations that can leverage custom memory access accelerators.
Debuggers, Profilers, and Performance Analysis Tools:
The Challenge: Understanding performance bottlenecks and debugging code on novel, heterogeneous architectures is significantly harder than on traditional systems.
The Need: A new generation of tools is required that can provide visibility into data movement, memory access patterns, branch divergence, and accelerator utilization across these complex systems.
Codesign is Not Optional; It’s Existential:
The path forward isn’t about hardware or software; it’s about their deep, iterative codesign.
Hardware architects must understand the target workloads and software challenges.
Software developers must understand the capabilities and limitations of the emerging hardware.
Algorithm designers must explore new approaches that can best leverage these co-designed systems.
Organizations like LANL are leading this charge not because it’s easy, but because, for their mission-critical, structurally nightmarish problems, there is no other way. The “collapse” isn’t hyperbole; it’s the inevitable outcome of trying to solve tomorrow’s problems with yesterday’s architectural assumptions. The “codesign” approach, while demanding, is the only viable path to architecting a future where computational limits are set by our ingenuity, not by our tools.
Section 6: Conclusion — The Future is Structured
We’ve seen the writing on the wall: the brute-force scaling of today’s dense-compute architectures is a dead end for the world’s many critical and complex problems. The real bottlenecks — sparsity, indirection, branching — aren’t solved by more FLOPs; they demand a fundamental architectural reckoning.
The Strategic Imperative is Clear: Shift investment and innovation from chasing diminishing returns in dense computation to mastering Structurally-Aware Compute. This is where the next trillion-dollar markets lie, where true scientific breakthroughs will be unlocked, and where national technological supremacy will be forged.
The current mispricing of this opportunity — the “sparsity tax” paid by ill-suited hardware — is an open invitation for astute investors, visionary technologists, and strategic policymakers. The path involves deep codesign: PIM, specialized RISC-V accelerators, intelligent memory systems, and the software ecosystems to harness them.
What Lies Ahead:
The Rise of Heterogeneous Specialization: Expect a Cambrian explosion of silicon tailored for structural complexity, augmenting (and in some critical niches, displacing) today’s general-purpose giants. The focus will be on effective throughput for complex operations, not just raw transactional speed.
Software as the Ultimate Differentiator: The platforms and compilers that can elegantly map structural challenges onto this new diverse hardware landscape will become kingmakers, capturing immense value.
This isn’t just about faster machines; it’s about a new philosophy of computation. The Chocolate Milk Cult will continue to track the key players and inflection points in this shift, particularly how these architectural truths will reshape AI model development (think Diffusion and beyond) and the geopolitical landscape of tech.
Thank you for being here, and I hope you have a wonderful day.
Math Supremacist,
Dev <3
If you liked this article and wish to share it, please refer to the following guidelines.
That is it for this piece. I appreciate your time. As always, if you’re interested in working with me or checking out my other work, my links will be at the end of this email/post. And if you found value in this write-up, I would appreciate you sharing it with more people. It is word-of-mouth referrals like yours that help me grow. The best way to share testimonials is to share articles and tag me in your post so I can see/share it.

Reach out to me
Use the links below to check out my other content, learn more about tutoring, reach out to me about projects, or just to say hi.
Small Snippets about Tech, AI and Machine Learning over here
AI Newsletter- https://artificialintelligencemadesimple.substack.com/
My grandma’s favorite Tech Newsletter- https://codinginterviewsmadesimple.substack.com/
My (imaginary) sister’s favorite MLOps Podcast-
Check out my other articles on Medium. : https://rb.gy/zn1aiu
My YouTube: https://rb.gy/88iwdd
Reach out to me on LinkedIn. Let’s connect: https://rb.gy/m5ok2y
My Instagram: https://rb.gy/gmvuy9
My Twitter: https://twitter.com/Machine01776819
Appendix: Strategic Financial & Investment Analysis — The Emerging Paradigm of Structurally-Aware Computation
(Detailed math available to founding subscribers on request. Once you get a founding subscription, email me devansh@svam.com. We also provide individual reports to our clients.)

Preamble
The following analysis moves beyond surface-level market sizing to explore the underlying economic drivers, value inflection points, strategic challenges, and potential asymmetric opportunities presented by the shift towards computational architectures optimized for structural complexity (i.e., extreme sparsity and branching). This is predicated on the understanding that current mainstream HPC and AI hardware trends are increasingly divergent from the needs of a critical set of scientific, national security, and nascent commercial workloads.
Foundational Assumptions & Market Context
Diminishing Returns of Brute-Force Scaling for Complex Problems: While overall compute demand grows, the marginal utility of adding more general-purpose FLOPS/memory bandwidth to structurally complex problems (characterized by high indirection, low arithmetic intensity, frequent branching) is decreasing. This creates an “inefficiency arbitrage” opportunity. For critical workloads at institutions like Los Alamos National Laboratory (LANL), the majority of operations (60%) involve memory and integer operations, specifically indirect load/store, due to unstructured meshes, sparse matrices, and adaptive mesh refinement. This indicates that raw FLOPS are not the primary bottleneck; instead, inefficient handling of irregular data access patterns is the limiting factor. Quantitative analysis shows that over 50% of all instructions in nuclear security applications are sparse memory operations resulting from indirection, and that routines are “mostly or completely main-memory bound” (0.001–0.2 FLOP/byte). This exceptionally low FLOP/byte ratio confirms that performance is overwhelmingly limited by data movement and access, validating the “inefficiency arbitrage” as a fundamental, data-backed market opportunity.
“Problem-Driven” vs. “Hardware-Driven” Innovation Cycles: The current dominant paradigm is largely hardware-driven (newer, bigger GPUs/CPUs enable new software). The shift targets a problem-driven cycle, where the unique demands of intractable problems dictate novel hardware/software co-design. For the United States to continue benefiting from advances in computing, “investments in deeper co-design of hardware and software — addressing levels of branching and sparsity not found in machine learning or most other major market applications — will be needed”. This highlights a “gap in technologies” for complex workloads with high sparsity and significant branching, which are poorly served by commodity CPUs and GPUs. Current work at LANL, focusing on “Codesign for memory-intensive applications” and addressing sparsity through software and hardware prototypes, exemplifies this problem-driven approach.
Long Gestation, High Impact: Fundamental architectural shifts are capital-intensive and require 5–10+ year horizons. However, successful shifts can redefine market leadership and create multi-decade technological moats. Complex simulations, such as a 3D simulation on the Sierra supercomputer, have required “nearly a year and a half” to complete, and achieving higher fidelity simulations took “more than a decade”. While core architectural shifts remain long-term endeavors, the emergence of “rapid co-design cycles” through the “commoditization of processor design and fabrication” (e.g., RISC-V Chipyard and FPGA prototyping) is increasing development agility and potentially offering earlier validation points.
Sovereign & Strategic Imperatives as Initial Catalysts: National security, fundamental science (e.g., fusion, climate), and critical infrastructure resilience will likely be the initial, non-negotiable drivers for investment, de-risking early-stage R&D before broader commercial viability is proven. LANL’s work is a prime example, with advances in computational capabilities deemed “absolutely essential” for the U.S. nuclear deterrent, and sparsity and branching highlighted as “root challenges” for nuclear security applications. This strategic demand provides a de-risked “seed” market with guaranteed funding, independent of immediate commercial viability.
Data Movement as the True Bottleneck: Increasingly, the cost (time, energy) of moving data far exceeds the cost of computation itself for these workloads. Solutions that minimize or intelligently manage data movement will hold a premium. As noted, 60% of operations in relevant workloads are memory and integer operations, and over 50% are sparse memory operations, with routines being “mostly or completely main-memory bound”. Beyond these specific workloads, the memory system is responsible for “most of the energy consumption, performance bottlenecks, robustness problems, monetary cost, and hardware real estate of a modern computing system”. Main memory alone can be responsible for over 90% of system energy in commercial edge neural network models, and over 62% of total system energy is wasted on moving data in mobile workloads. This elevates the “data movement bottleneck” from a specific problem for sparse/branching workloads to a fundamental, escalating issue across all data-intensive applications, including mainstream AI, implying broader market applicability for solutions.
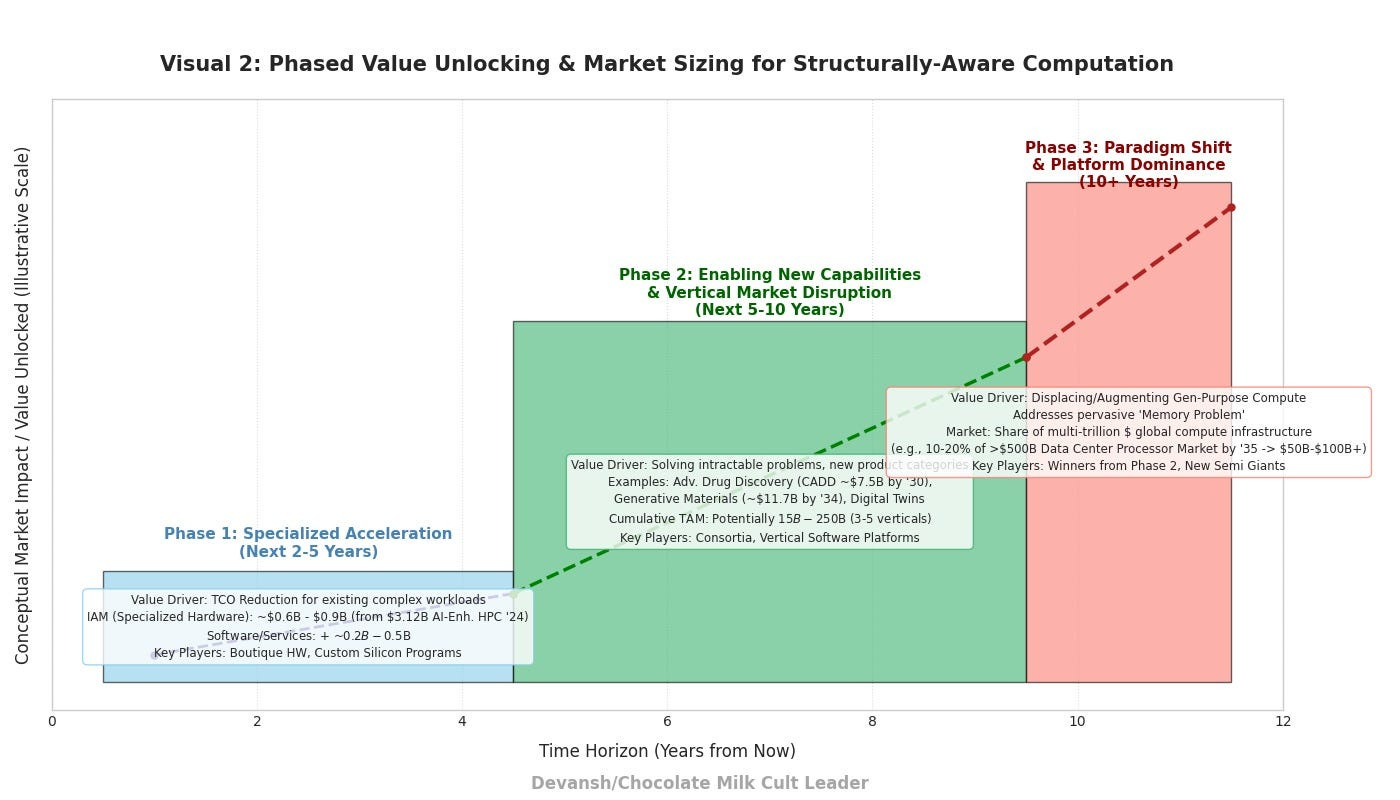
Value Unlocking Stages & Market Sizing
Phase 1: Specialized Acceleration & Efficiency Gains (Next 2–5 Years)
Value Driver: Significant TCO reduction (power, footprint, time-to-solution) for existing, well-defined, structurally complex workloads in government labs, research institutions, and highly specialized industries (e.g., advanced materials, niche drug discovery, high-frequency trading with complex order books).
Market Estimate:
Current Global HPC Market: The total HPC market, which provides context for this phase, was estimated at USD 57.00 billion in 2024 and is projected to reach USD 87.31 billion by 2030.

Initial Addressable Market (IAM): Annual global spend on HPC systems for these specific problem classes, closely aligned with the “AI Enhanced HPC Market,” was valued at USD 3.12 billion in 2024. This market is projected to grow to USD 7.5 billion by 2034
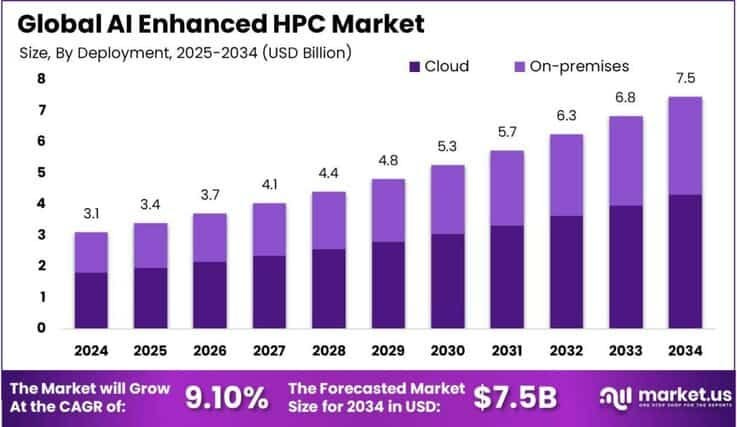
Potential Value Capture: Accelerators/co-processors offering 5–10x performance/dollar for these niches could capture 20–30% of this IAM. Applying this to the updated 2024 IAM of $3.12 billion, this leads to a $624M–$936M annual market for specialized hardware solutions. Empirical evidence from LANL demonstrates substantial performance improvements (e.g., 89% and 185% throughput increase) with specialized memory access accelerators.
Software and Integration Services: Could add another $200M–$500M. The strategic importance of software and the ecosystem is increasingly recognized, with value potentially accruing disproportionately to the software ecosystem integrator in the long term.
Key Players: Boutique hardware startups, semiconductor majors exploring custom silicon (ASICs/FPGAs via programs like Intel IFS or TSMC shuttle runs), academic spin-outs.
Many VCs will deem this initial market “too small.” However, this perception is rapidly shifting. The datacenter processor market, valued at $136.3 billion in 2024, shows ASICs as a fast-growing segment.
Hyperscalers are actively driving the growth of custom silicon, and there is significant merger and acquisition activity as established players seek to incorporate cutting-edge technologies in the HPC and AI accelerator market. The strategic play is for acquirers (large semiconductor firms, defense contractors, cloud providers with HPC offerings) seeking unique IP and early access to a paradigm shift.
Phase 2: Enabling New Capabilities & Vertical Market Disruption (Next 5–10 Years)
Value Driver: The ability to solve problems previously considered computationally intractable, leading to new product/service categories.
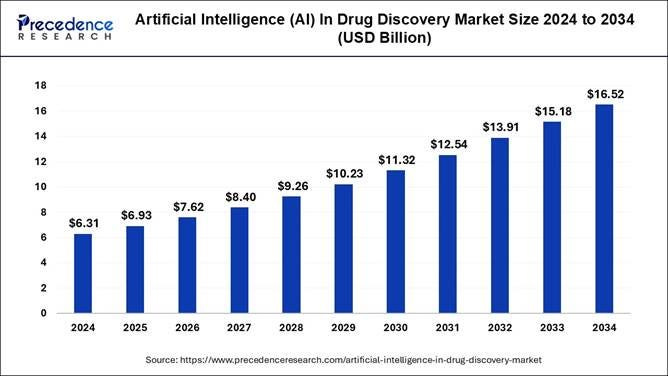
Example 1: Computational Drug Discovery Moving beyond QSAR/docking to full biophysical system simulation for predicting efficacy and toxicity, drastically reducing wet-lab costs. The global computer-aided drug discovery (CADD) market was $2.9 billion in 2021 and is projected to reach $7.5 billion by 2030. More specifically, the “AI in Drug Discovery Market” was already $6.31 billion in 2024 and is expected to reach $16.52 billion by 2034. The broader biosimulation market is forecast to reach $9.65 billion by 2029.
Example 2: Generative Engineering & Materials Science. Inverse design of materials/structures with specific properties based on first-principles simulation. The “Generative Artificial Intelligence (AI) in Material Science Market” was valued between $1.1 billion and $1.26 billion in 2024. This market is projected to reach $5.35 billion by 2029 or $11.7 billion by 2034.
Example 3: Hyper-Realistic Digital Twins for Critical Infrastructure Predictive maintenance, operational optimization, and resilience planning for energy grids, supply chains, urban systems. These applications inherently involve sparse, dynamic, and branching data structures, representing a significant latent opportunity for structurally-aware computation to enable higher fidelity and predictive power.
Market Estimate: This is harder to quantify as it’s new market creation. Each successful vertical could represent a $5B–$50B+ total addressable market (TAM) for the enabling computational platforms and associated software/services. Based on current market trajectories for computational drug discovery and generative materials science, these figures appear realistic, and potentially conservative on the lower end. Success in 3–5 such verticals implies a cumulative TAM of $15B–$250B.
Key Players: Consortia of domain experts, software companies building vertical-specific platforms, and the hardware providers from Phase 1 who achieve sufficient scale and programmability.
The “killer app” may not emerge from the initially targeted government/science domains but from an unexpected commercial application where structural complexity is a hidden but critical bottleneck (e.g., advanced financial modeling, logistical optimization at extreme scale, certain classes of AI inference for robotics/autonomous systems with highly dynamic environments). The rise of SLMs (Small Language Models), designed to reduce memory usage, computational operations, and energy consumption for AI models, particularly for edge devices, directly aligns with this potential.
One thing that both the release of ChatGPT and Open Source Gen AI have taught us is that making powerful technology more accessible allows completely new entrants to see things that traditional experts miss. Smart investors, founders, and decision makers should be proactive in identifying these blind spots and emergent solutions before anyone else.
Phase 3: Paradigm Shift & Horizontal Platform Dominance (10+ Years)
Value Driver: The underlying architectural principles and software ecosystems developed for structural computation become so effective and generalizable (for non-uniform workloads) that they begin to displace or significantly augment existing general-purpose compute paradigms in HPC, specialized AI, and large-scale data analytics. This is driven by the pervasive “memory problem” in computing, where the memory system is responsible for most of the energy consumption, performance bottlenecks, and monetary cost in modern systems. The widening “memory wall,” where processing performance has skyrocketed by 60,000x over two decades while DRAM bandwidth has only improved 100x, underscores the need for this fundamental shift.
Market Estimate: This is about capturing a share of the future multi-trillion-dollar global compute infrastructure market. “The global data center processor market neared $150 billion in 2024 and is projected to expand dramatically to >$370 billion by 2030, with continued growth expected to push the market well beyond $500 billion by 2035.” If these architectures can address even 10–20% of workloads poorly served by current von Neumann/GPU-centric designs, this represents a $200B–$1T+ annual revenue potential for hardware, software, and cloud services.
Key Players: The winners from Phase 2 who successfully built out a robust, programmable, and developer-friendly ecosystem. Potential for new semiconductor giants to emerge or for existing ones to pivot successfully. Innovative startups are already pioneering novel architectures, including dataflow-controlled processors, wafer-scale packaging, spatial AI accelerators, and processing-in-memory technologies.
Commercially available Processing-in-Memory (PIM) hardware, such as UPMEM’s PIM modules, is now integrating general-purpose processors directly onto DRAM chips, demonstrating the active development of memory-centric architectures. The ultimate “winner” might not be a single hardware architecture but a highly adaptable software/compiler stack that can efficiently map structurally complex problems onto heterogeneous systems incorporating both general-purpose cores and specialized structural accelerators. The value accrues disproportionately to the software ecosystem integrator.
Personal Bias — Quantum computing, if it matures for certain problem classes, could complement rather than replace these structurally-aware classical systems, handling exhaustivesub-problems. Treat this more as my speculation/intuition, as opposed to strongly backed research
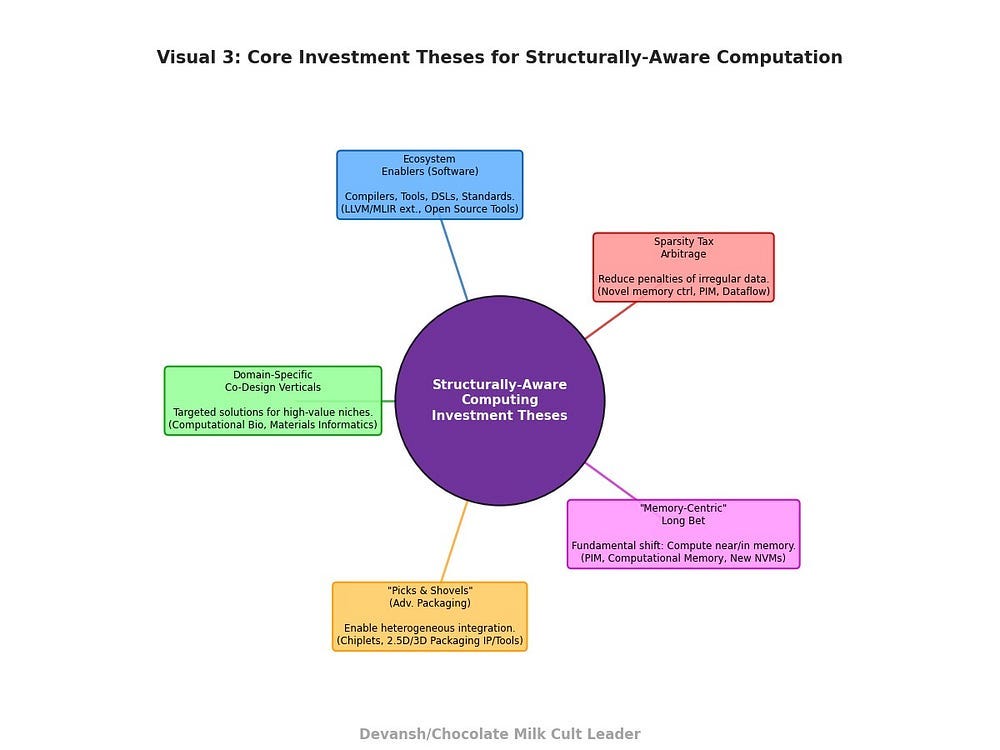
Key Investment Theses & Strategic Angles
The “Sparsity Tax” Arbitrage: Invest in technologies that explicitly reduce the “sparsity tax” — the performance penalty incurred by general-purpose hardware when dealing with irregular data. This includes novel memory controllers, in-memory compute, dataflow architectures, and compilers that can aggressively optimize for locality in sparse codes. Observed throughput improvements of 89% and 185% with specialized memory access accelerators demonstrate the potential for this arbitrage.

Ecosystem Enablers: Beyond silicon, the value lies in software. Compilers, debuggers, performance analysis tools, high-level programming models (DSLs tailored for sparsity/branching), and standardized sparse data formats will be crucial. Investments here can have outsized leverage. LANL’s active “Application and frameworks codesign” efforts (e.g., FleCSI, Kokkos, LLVM, MLIR) reinforce the importance of this layer. RISC-V plays a role here by fostering open ISA experimentation.
Domain-Specific Co-Design Verticals: Instead of generic “sparse accelerators,” focus on companies co-designing solutions for specific high-value verticals (e.g., computational biology, materials informatics) where the problem structure is well-understood, and a clear ROI can be demonstrated. The rapid growth of the “AI in Drug Discovery Market” and “Generative AI in Material Science Market” validates this approach.
“Picks and Shovels” for Advanced Packaging: Solutions that tackle structural complexity will likely involve heterogeneous integration (chiplets). Companies providing critical IP, tools, or services for advanced 2.5D/3D packaging will benefit indirectly but significantly. GPUs are heavily relying on advanced packaging technologies like CoWoS, Foveros, and EMIB to exceed 2.5KW, and demand for high-end logic process chips and high-bandwidth memory (HBM3, HBM3e, HBM4) is increasing due to AI accelerators.
The “Memory-Centric Computing” Long Bet: The most radical (and potentially highest reward) thesis is that the von Neumann bottleneck is insurmountable for these problems, and a fundamental shift to architectures where computation happens much closer to, or within, memory is inevitable. This encompasses processing-in-memory (PIM), computational memory, and non-volatile memory technologies with compute capabilities.
Real PIM hardware has recently become commercially accessible, with companies like UPMEM offering PIM modules that integrate general-purpose processors directly onto DRAM chips. “According to a report by Polaris Market Research, the total addressable market (TAM) for MRAM is projected to grow to USD $25.1 billion by 2030, at a CAGR of 38.3%. Numem is poised to play a pivotal role in this growing market, sitting at the intersection of AI acceleration and memory modernization.”
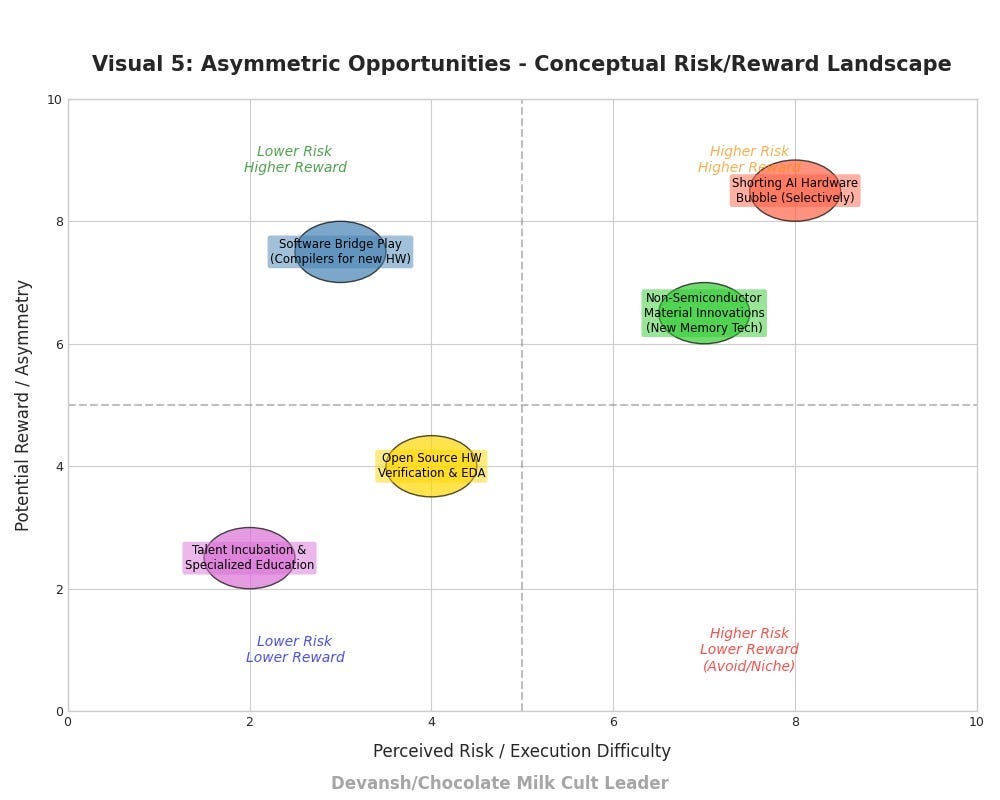
Asymmetric Opportunities
Shorting the “AI Hardware Bubble” (Selectively): While AI is transformative, the current valuation of some general-purpose AI hardware companies might not fully price in their limitations for other complex, non-AI workloads that will become increasingly important. Hyperscalers committed $200 billion in twelve-month trailing capital expenditures in 2024, with projections reaching $300 billion in 2025, raising questions about efficiency for all workloads. A nuanced strategy might involve identifying companies over-indexed on purely dense AI paradigms with limited adaptability (High risk, requires precise timing).
The “Software Bridge” Play: Invest in companies developing highly sophisticated compiler technology that can efficiently map existing sparse codes (Fortran, C++, MPI) onto emerging novel architectures. This reduces the adoption friction for new hardware and captures value as an intermediary.
Non-Semiconductor Material Innovations for Memory: Breakthroughs in memory materials (e.g., phase-change memory, MRAM, resistive RAM) that offer new trade-offs in density, latency, endurance, and potential for in-situ computation could disrupt the current DRAM/SRAM dominance and create openings for new architectures. Companies like Numem are developing foundry-ready, MRAM-based AI Memory Engines that address memory bottlenecks with significantly lower power consumption than traditional SRAM and DRAM.
Open Source Hardware Verification & EDA Tools: As more custom silicon (especially RISC-V based) is developed for these niches, there’s a growing need for robust, cost-effective open-source or source-available verification and Electronic Design Automation (EDA) tools. This is a critical infrastructure gap.
Talent Incubation & Specialized Education: The bottleneck for this entire field will eventually be human capital. Strategic investments in programs that cross-train computer architects, software engineers, and domain scientists for co-design will yield long-term dividends for nations or corporations that pursue this.
Geopolitical & Sovereign Implications Technological Sovereignty:
Nations that develop domestic capabilities in designing and fabricating these specialized computational systems will gain a strategic advantage, reducing reliance on potentially adversarial or supply-chain-constrained foreign entities, especially for defense and critical infrastructure. Global initiatives like the CHIPS Act and the push for localized, secure supply chains underscore this imperative.
“Computational Decoupling”: If mainstream hardware (largely optimized for consumer/enterprise AI) continues to diverge from strategic national needs, leading nations may accelerate investment in bespoke “sovereign compute” initiatives, creating a parallel, non-commercial innovation track. LANL’s focus on specialized hardware-software co-design for unique, high-priority workloads is a prime example of this divergence.
Export Controls & IP Protection: As these technologies demonstrate strategic value, they will inevitably become subject to intense scrutiny regarding intellectual property rights and export controls, similar to current advanced semiconductor and AI restrictions. Ongoing trade tensions and evidence of GPU transshipment highlight the real-world impact of these policies.
Conclusion for Appendix
The transition to structurally-aware computation is not a minor architectural tweak; it represents a potential paradigm shift with profound economic, strategic, and geopolitical consequences. While the path is long and fraught with technical and market challenges, the rewards for those who successfully navigate it — whether as innovators, investors, or national strategists — are commensurate with the difficulty of the problems being solved. The era of “one-size-fits-all” high-performance computing may be drawing to a close, ceding to a more specialized, problem-driven future.
👏👏
Excellent article, thanks for doing the deep dive.
One nit: Having seen a few computing architecture shifts in my life time, I suspect your time line is a bit optimistic. My experience has been that, while computing power follows Moore's law, the creation and adoption of new computing paradigms seems to always take about the same time to even take significant market share, let alone reach market dominance; I expect it will take at least a decade, probably more.