


Sheaf Theory: Nvidia’s Stealth Deep-Tech Bet to Improve AI Reasoning [Investigations]
Moving Beyond Graphs—The Hidden Mathematical Revolution Investors Should Understand Now

It takes time to create work that’s clear, independent, and genuinely useful. If you’ve found value in this newsletter, consider becoming a paid subscriber. It helps me dive deeper into research, reach more people, stay free from ads/hidden agendas, and supports my crippling chocolate milk addiction. We run on a “pay what you can” model—so if you believe in the mission, there’s likely a plan that fits (over here).
Every subscription helps me stay independent, avoid clickbait, and focus on depth over noise, and I deeply appreciate everyone who chooses to support our cult.
PS – Supporting this work doesn’t have to come out of your pocket. If you read this as part of your professional development, you can use this email template to request reimbursement for your subscription.
Every month, the Chocolate Milk Cult reaches over a million Builders, Investors, Policy Makers, Leaders, and more. If you’d like to meet other members of our community, please fill out this contact form here (I will never sell your data nor will I make intros w/o your explicit permission)- https://forms.gle/Pi1pGLuS1FmzXoLr6
Oy Oy, it’s your boy, the “Bo Nickal of Tickle My Pickle”.
I’ve been researching ways to fix hallucinations in complex, multistep NLP problems and came across some very interesting research published, “Sheaf theory: from deep geometry to deep learning”. I think the ideas/concepts in this field are very interesting and have a lot of potential for some severe disruption in AI.
And based on some things I’m hearing from people, Nvidia agrees with me (if you want the inside scoop on this, get the Founding Member Subscription and then send me a message for the details). Given the magnitude of this implication and how it can reshape a lot of businesses, I figured I’d cover this.

Current AI, especially Graph Neural Networks (GNNs), is fundamentally constrained by its reliance on simple graphs, which is like trying to understand 3D physics using only 2D projections. This forces compromises: graphs mangle higher-order relationships (hierarchies, group interactions), leading to performance collapses on heterophilic data (where connections link dissimilar things) and endemic oversmoothing that erases vital local detail. This isn’t about needing more data; it’s about an inadequate mathematical language.

Sheaf Theory offers a potential upgrade to deal with this. We will break down the limitations of graphs, how Sheaf Theory allows us to tackle this, how builders and investors should invest in Sheaf Theory to maximize returns (both short and long term) and much more-

Executive Highlights (TL;DR of the Article)
Overall- Investing solely in incremental GNN improvements is a bet on diminishing returns within a capped paradigm. Sheaf theory represents the necessary, mathematically sound evolution. The inherent complexity of the space + the extremely high value problems it can solve give it a natural moat + high commercialization potential, respectively, if you can bet on the right horse. The if part is key, b/c this is a huge challenge, but I think it’s still worth betting on.
The Problem with Graphs:
Current AI based on simple graphs (like GNNs) fundamentally fails at complex reality. It ignores higher-order relationships, breaks on dissimilar data (heterophily), and averages away crucial details (oversmoothing). Relying solely on graphs is hitting a hard wall.
The Technicals of Sheaf Theory in AI
Sheaf Neural Networks (SNNs) operate on richer structures like Partially Ordered Sets (Posets), which natively encode complex relations (A included in B, X causes Y).

A Sheaf overlays Posets with explicit rules (structure maps) dictating precisely how information must transform between related elements. This provides:
Contextual Interactions: Rules tailored to the type of relationship, overcoming heterophily.
Topological Awareness: Tools (cohomology) to rigorously detect global inconsistencies and hidden structural patterns.
Principled Dynamics: Energy landscapes (Laplacians) defined by the system’s specific rules, governing stability and information flow.
This combines into much richer representations for us. Sheaves enable AI to:
Handle diverse relationships correctly (fixing heterophily).
Rigorously check global consistency (via Cohomology).
Model system dynamics based on specific rules (via Laplacians).
Learn optimal interaction rules from data (via Sheaf Learning), creating truly adaptive systems.
(If those some of those words left you frozen like Elsa, don’t worry; we will be explain all of these terms and their importance later).
The Problems
However, while powerful, applying sheaf theory faces real hurdles. Universal computation methods are often too slow. The core research introduces minimal cochain complexes, algorithms promising optimal computational complexity for analyzing any finite structure. However, practical, high-performance implementations are still needed. Furthermore, applying these techniques to the massive scale of real-world datasets — billions of nodes and complex relations — remains a significant engineering challenge to be addressed. Finally, the construction of these figures has been handicapped extensively by the fact that building these figures requires extensive domain knowledge for all their connections.
The last part is something that general-purpose Language Models, with their vast baseline knowledge, seem to be in a good place to solve, especially when we think about how reasoning models are trained to simulate chains of thought, which could be seen as a specific example of a sheaf. Additonally, techniques like Supervised Learning can be very good for scaling the construction of Sheafs in a general way.
When you think about that, the space looks juicier than before. This is still incredibly hard, don’t get me wrong, but it is juicier than before.
Investor Notes
Short-term estimated Value Unlock: $200M — $500M annually in near-term market share capture and efficiency gains within existing multi-billion dollar AI application markets (e.g., pharma R&D, fintech analytics). This value stems from solving existing, monetizable problems better. The estimated value has been dampened by a moderately high risk, to account for the difficulty in implementing this research well. This requires some heavy-hitting to get right, and spraying and praying won’t work.
Long-term estimated Value Unlock: $10B — $50B+ market creation. This reflects the potential to underpin AI in major scientific and engineering sectors currently underserved by data-driven methods alone, and fundamentally reshaping the AI infrastructure landscape (potentially reducing reliance on brute-force GPU scaling for certain relational tasks).
This is a really complex idea, with a lot of intimidating math. But have some faith in yourself, and we will manifest our inner Dutchmen to beat its body down, one knee at a time.
I put a lot of work into writing this newsletter. To do so, I rely on you for support. If a few more people choose to become paid subscribers, the Chocolate Milk Cult can continue to provide high-quality and accessible education and opportunities to anyone who needs it. If you think this mission is worth contributing to, please consider a premium subscription. You can do so for less than the cost of a Netflix Subscription (pay what you want here).

I provide various consulting and advisory services. If you‘d like to explore how we can work together, reach out to me through any of my socials over here or reply to this email.
Section 1 — The Graph Ceiling: Why Pairwise Models Are a Dying Investment
The prevailing architecture for relational AI, the Graph Neural Network (GNN), is built upon a profound simplification: real-world interactions (inherently a mess- look no further than your life for proof) can be adequately represented by a network of simple, pairwise links. This foundational assumption, while enabling initial progress, has now become the primary impediment to further advancement. It imposes a hard, mathematically defined ceiling on what these models can achieve.
Since khayali pulao feeds noone, let’s talk about the specific problems associated with Graphs-
Structural Blindness
“Simple graphs are restricted to two levels in their posetal order and are therefore limited in their ability to represent more complex, higher-order relationships that may exist within a space. To address this limitation, various discrete geometric structures have been suggested as a means to encode higher-order relationships in data, assuming that the data is supported on topological domains. These, too, may be represented as posets.”
A simple graph stores only two ranks of information:
Objects (nodes) — the individual entities.
Direct links (edges) — whether any two objects touch.
Everything else — triadic synergy, nested hierarchies, joint causation — gets flattened. For my fellow builders and researchers- mathematically speaking, the underlying poset stops after those two ranks, so structures that live above pairwise links are absent from the representation.
This has several profound implications. Consider the little-known, completely shocking mathematical theorem that states that “No model, no matter how big, can learn information that was never encoded.” Truly groundbreaking stuff, I know. Feel free to take a second and pause to recollect yourself. Using a simplistic encoding like Graphs loses several important properties such as-
Joint causation If C happens only when A and B together fire, a simple graph must fake it with dummy nodes or logic gates.
Nested context A five-step chain may belong to a larger episode; the graph lists the edges but cannot tag the episode as a first-class entity.
Global constraints Energy-conservation, legal liability chains, multi-party contracts — all need rules that span the whole path, not edge-wise averages.
Graphs reduce each of these to a pile of isolated links, then ask a neural network to “re-invent” the missing structure. That re-invention is about as reliable as a Sean Strickland promise to “go to War”.
Heterophily meltdown — when neighbours disagree
“It was known that GCN architecture (as well as more general GNN architectures proposed until 2022) suffers from oversmoothing and exhibits poor performance on heterophilic graphs.”
Graph message-passing is built on averaging your neighbours. That silently assumes connected nodes are similar. Reality often isn’t-
Cross-domain knowledge graphs link radically different entity types (for me to price the impact of this research space, I had to look at investing, AI, engineering trends, use-cases, etc).
Recommender edges (“you bought A, people who bought A also bought B”) connect dissimilar products.
Social bridges bring together unlike communities. Doing BJJ introduced me to poor sods whose families sometimes barely made 100K (due to extreme financial hardship, their maid only came twice a week), senior leadership at Big Tech, small business owners, hippies, and pretty much everyone else you can imagine.



A provable expressivity wall
For any connected graph with three or more classes, a GCN can never achieve linear separability, no matter how many layers you stack or how you tune features.

No level of money will make you play as well as Antony. Some are just built differently.

Inevitable oversmoothing
Each message-passing layer is a weighted average; repeat the operation, and representations drift toward the global mean.

Why architectural patches can’t raise the roof
Attention heads, residual hops, positional encodings — all bolt-ons on the same two-shelf scaffold. They delay collapse; they do not create new shelves. Until the data structure itself is upgraded, every extra parameter is money spent polishing a ceiling that sits at head height.
With that covered, let’s talk about the solutions.
Section 2: Posets and Sheaves, Escaping the Flatland of GNNs
The graph’s limitations are not incremental flaws; they represent a fundamental mismatch between the model’s structure and reality’s complexity. To escape this pairwise prison of representational poverty requires adopting a richer mathematical foundation — one capable of natively expressing hierarchy, multi-level interactions, and context-dependent rules. This foundation is built from two components: Partially Ordered Sets (Posets) for the structure, and Sheaf Theory for the data and interaction physics.
Let’s drink some secret juice and get into this-
1. Posets: Geometry Beyond Simple Links
Graphs capture only Level 0 (nodes) and Level 1 (direct, pairwise edges). A Poset (S, ≤) moves beyond this, defining elements S alongside an ordered relationship ≤. This ≤ isn’t merely connection; it encodes concepts like:
Inclusion: Component ≤ System
Causality: Cause ≤ Effect
Dependency: Subroutine ≤ Main Program
Hierarchy: Team ≤ Division ≤ Company
This allows the model structure to explicitly represent the nested, layered, and directed nature of real-world systems. Where graphs flatten reality into a single interaction plane, posets provide the multi-dimensional scaffold necessary to capture its true geometry.
Think of it as upgrading from blueprints (graphs) to full architectural plans (posets). This get cracked when we combine it with the next idea-
2. Sheaves: Programmable Physics on the Structural Scaffold
A poset defines the structure, but a Sheaf D defines how information lives and behaves on that structure. It assigns:
Stalks D(s): Local data containers (e.g., vector spaces) attached to every element s (nodes, groups, hierarchical levels) in the poset. This holds the state.
Structure Maps D(s₁ ≤ s₂): Explicit transformation rules (e.g., matrices, functions) associated with each specific relation s₁ ≤ s₂. These dictate precisely how data must change or interact when moving between related elements according to that specific ordered link.
This is the critical departure from GNNs. Instead of a single, crude aggregation rule, sheaves allow programmable interaction physics. In that sense, they remind me of Kolmogorov-Arnold Networks-
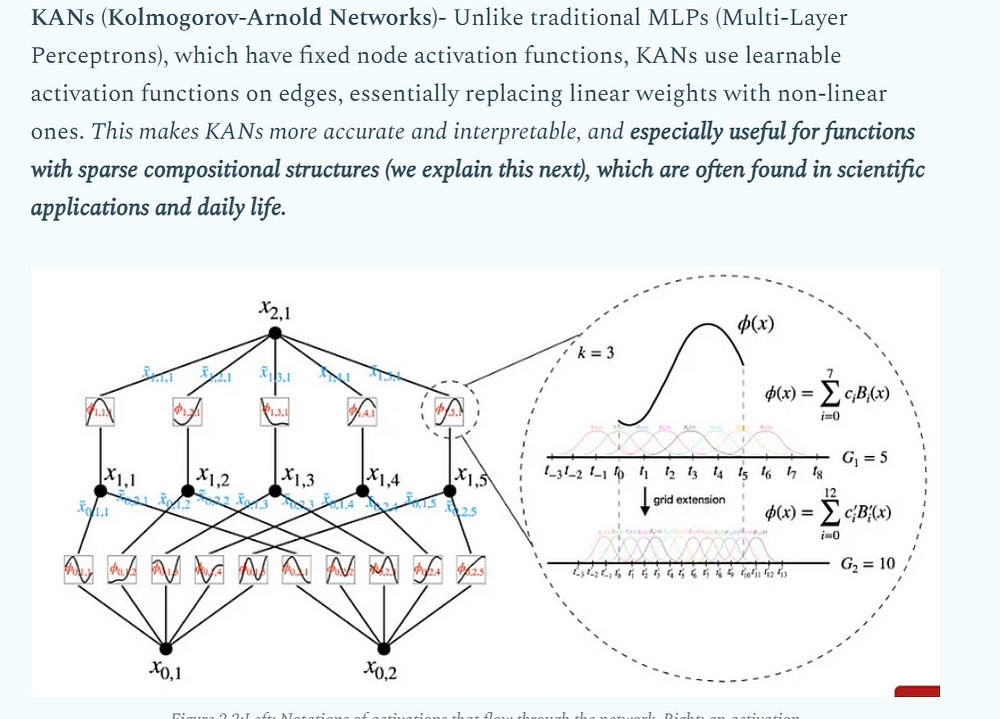
Back to the piece- The map D(Employee ≤ Manager) can encode promotion criteria, while D(CompetitorA ≤ CompetitorB) might encode market share dynamics. Heterophily isn’t a problem; it’s handled by defining the correct structure map for that specific type of interaction.
Furthermore, these maps must obey compositionality: D(s₀ ≤ s₂) = D(s₁ ≤ s₂) ◦ D(s₀ ≤ s₁). This isn’t just mathematical neatness; it enforces global consistency derived from local rules. A sheaf ensures that information propagates coherently across the entire complex structure, preventing the logical contradictions or signal degradation inherent in simplistic aggregation schemes.
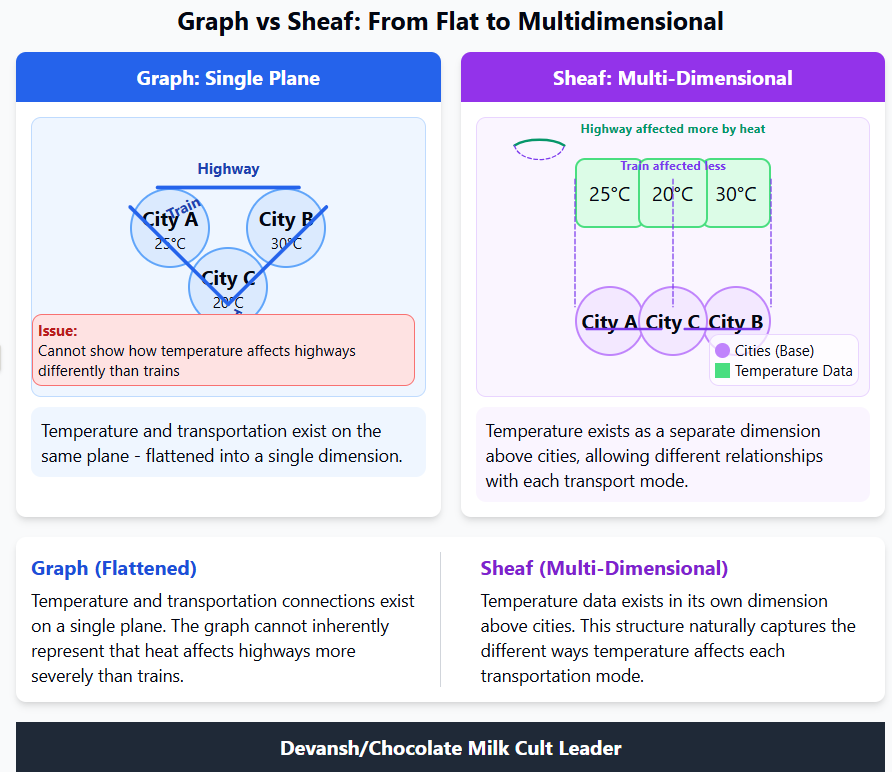
This allows your system to bring some serious heat. Consider modeling complex contracts or regulations:
Graphs: Show clauses linked vaguely. Detecting if nested conditions across disparate sections are met requires ad-hoc logic bolted onto the GNN.
Posets + Sheaves: The poset maps the hierarchy (clauses ≤ sections ≤ document). Sheaf structure maps encode the logical dependencies (AND, OR, IF-THEN). Compositionality ensures local rules combine correctly. A query for global compliance or identifying conflicting clauses becomes a direct computation on the sheaf structure, revealing contradictions mathematically.
Apply this logic broadly:
Systems Biology: Model metabolic pathways where enzyme activation (stalk data) depends on multiple, nested upstream conditions (poset structure), governed by specific reaction kinetics (structure maps).
Supply Chains: Track dependencies where failure of a tier-3 component (poset element) propagates upwards according to defined risk rules (structure maps), impacting entire product lines coherently.
Posets provide the structural skeleton; Sheaves provide the operational nervous system and circulatory system — data containers and the rules governing information flow. Together, they offer a unified, mathematically rigorous framework capable of representing complex, hierarchical, and context-dependent systems with fidelity impossible for graph-based models.
This isn’t just a better model; it’s the correct class of model for moving beyond AI’s current limitations. Understanding the specific computational tools this framework unlocks — cohomology, Laplacians, and learning algorithms — is the next critical step.
Section 3: Improving AI Reasoning with Sheaf Mechanics
Moving beyond graphs to Posets and Sheaves provides more than just a better representation; it unlocks a specific toolkit for manipulating and understanding complex systems. These tools offer capabilities fundamentally impossible with graph-based methods, forming an integrated arsenal for building next-generation AI.
Let’s look at our Soldiers of God and understand how they aid our mission-
1. Cohomology: The Global Consistency Audit
Cohomology mathematically verifies if the local rules and data defined by the Sheaf are globally coherent. It detects hidden contradictions or structural flaws that simple connectivity checks miss.
How it Works (Intuitively): Imagine checking a complex legal contract. Cohomology acts like an automated cross-referencing system. It takes the local rules encoded in the Sheaf’s structure maps (“If Clause A is active, Section Y requires Condition Z”; “Condition Z conflicts with Clause B activity”). It then traces these implications across the entire document structure (the poset). If following one chain of dependencies leads to a requirement (Clause B must be active) that directly contradicts a requirement derived from another chain (Clause B must be inactive), cohomology flags this global inconsistency (a non-zero 1st Cohomology). The lowest level, 0th Cohomology, identifies all scenarios where no such contradictions exist — the valid, fully consistent interpretations or states.

How to Use it: Deploy cohomology-based analysis early in design phases for complex systems. It is excellent for de-risking development by mathematically identifying fundamental inconsistencies before building on flawed logic. Efficiency hinges on algorithms like the minimal cochain complex capable of handling large structures, which is a good avenue for exploring investment (not so much startups but in internal teams). This technology can be used to build compliance-based startups, but those are very limited in growth opportunity, so I would only invest in one that has a clear vision on expanding beyond this.
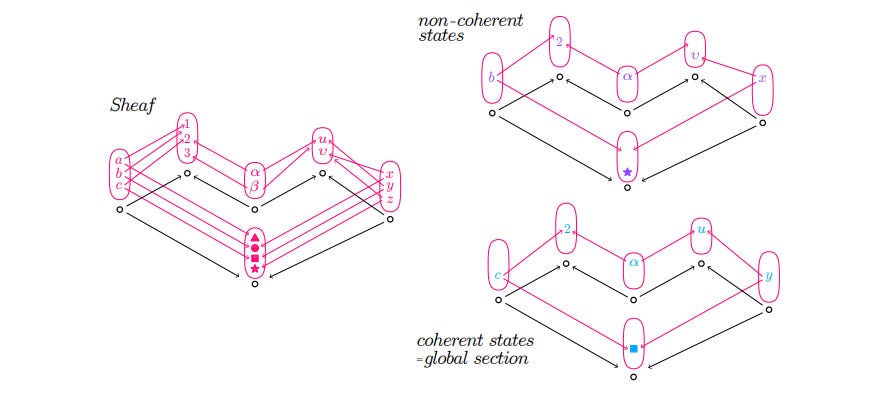
2. Sheaf Laplacians & Diffusion: Quantifying Stability, Driving Dynamics
Measures the internal “stress” or disagreement within a system based on its specific interaction rules, and models how the system naturally evolves towards stability or consensus.
The working of it is a lot simpler than the fancy terms would make it seem-
Define Local Agreement: Consider any two related elements in the structure, say Element_A and Element_B, where the relationship dictates that information flows from A to B (A ≤ B). The Sheaf provides a specific rule for this connection, let’s call it Rule_A_to_B. This rule tells you what the data at Element_B should be, based solely on the current data at Element_A. Let Data_A be the current data vector at Element_A. Applying the rule gives a prediction: Predicted_Data_B = Rule_A_to_B(Data_A).
Measure Disagreement: Now, compare this prediction with the actual data currently present at Element_B, let’s call it Actual_Data_B. The disagreement or “tension” along this single connection (A to B) is how far apart these two vectors are. Mathematically, it’s the squared distance: || Actual_Data_B — Predicted_Data_B ||². A small distance means high agreement; a large distance means high disagreement or tension.
Calculate Total System Stress: The Dirichlet Energy sums up these squared disagreement values calculated for every relevant connection across the entire structure. It provides a single number representing the total internal stress or incoherence of the system’s current state according to the Sheaf’s rules.
Relax Towards Harmony: Sheaf Diffusion is the process where each element iteratively adjusts its Actual_Data based on the disagreements with its neighbors (considering the specific Rule for each connection). Elements “pull” each other towards values that reduce local tension, thereby reducing the total system energy. This continues until the energy stabilizes at its minimum, meaning all local rules are satisfied as well as possible — the system reaches a globally consistent state (0th Cohomology).
Analyze Stability: The Sheaf Laplacian operator mathematically combines all these local disagreement calculations. Its eigenvalues reveal the system’s fundamental modes of relaxation and how quickly different types of disagreement decay.
Deploy Sheaf Laplacians for precise insight into system stability:
Finance: Go beyond correlations; explicitly quantify how interactions among assets create tension, and simulate how the portfolio moves toward stability.
Social Networks: Precisely measure how misinformation or influence propagates, using explicit trust/influence-based rules rather than simple averaging.
…
This can be huge for transparency, which is always a winning play in my books.
3. Sheaf Learning: Adaptive Physics for a Changing World
Enables AI systems to automatically learn and adapt the fundamental rules governing information flow and interaction within their structure.
How it Works (Intuitively):
Parameterize the Rules: Instead of fixing the structure maps D(s₁ ≤ s₂) (e.g., as identity matrices or predefined functions), represent them with learnable parameters (e.g., the entries of a matrix, weights of a small neural network specific to that connection type).
Define a Task Objective: Set up a standard machine learning task (e.g., predict node labels, forecast system behavior) with a loss function that measures prediction error.

Propagate Information (Trial Run): Pass input data through the network, using the current (parameterized) structure maps within the Sheaf Diffusion layers to propagate information and compute outputs.
Calculate Error: Compare the network’s output to the desired outcome and compute the task loss.
Adjust the Rules (Backpropagation): Use standard backpropagation and gradient descent. The crucial difference is that the gradients flow back not only to update node representations but also to update the parameters defining the structure maps. The system learns to adjust its internal “rules of physics” (D(s₁ ≤ s₂) maps) to minimize the final task error. It effectively discovers which interaction rules lead to better performance on the observed data.
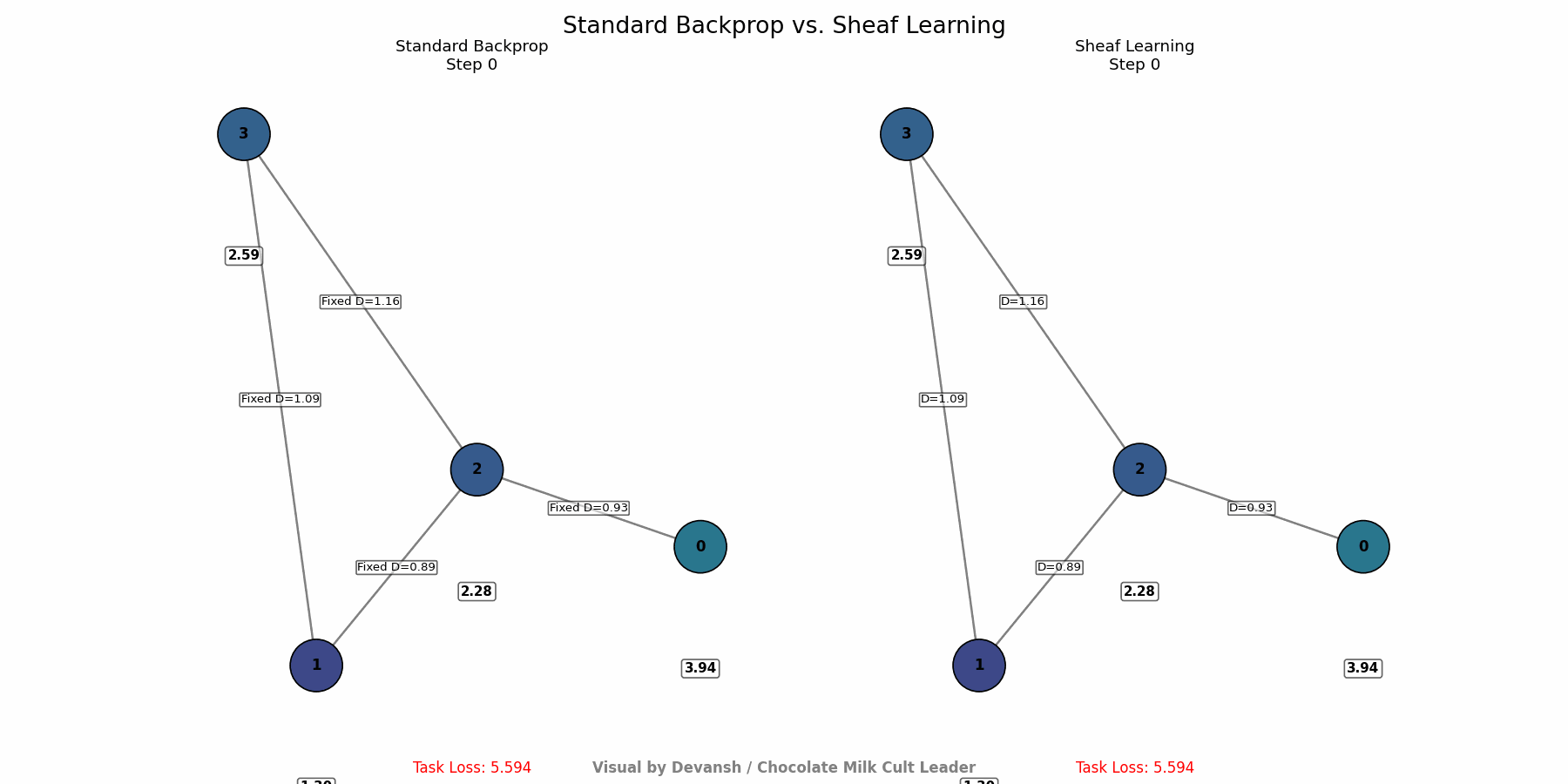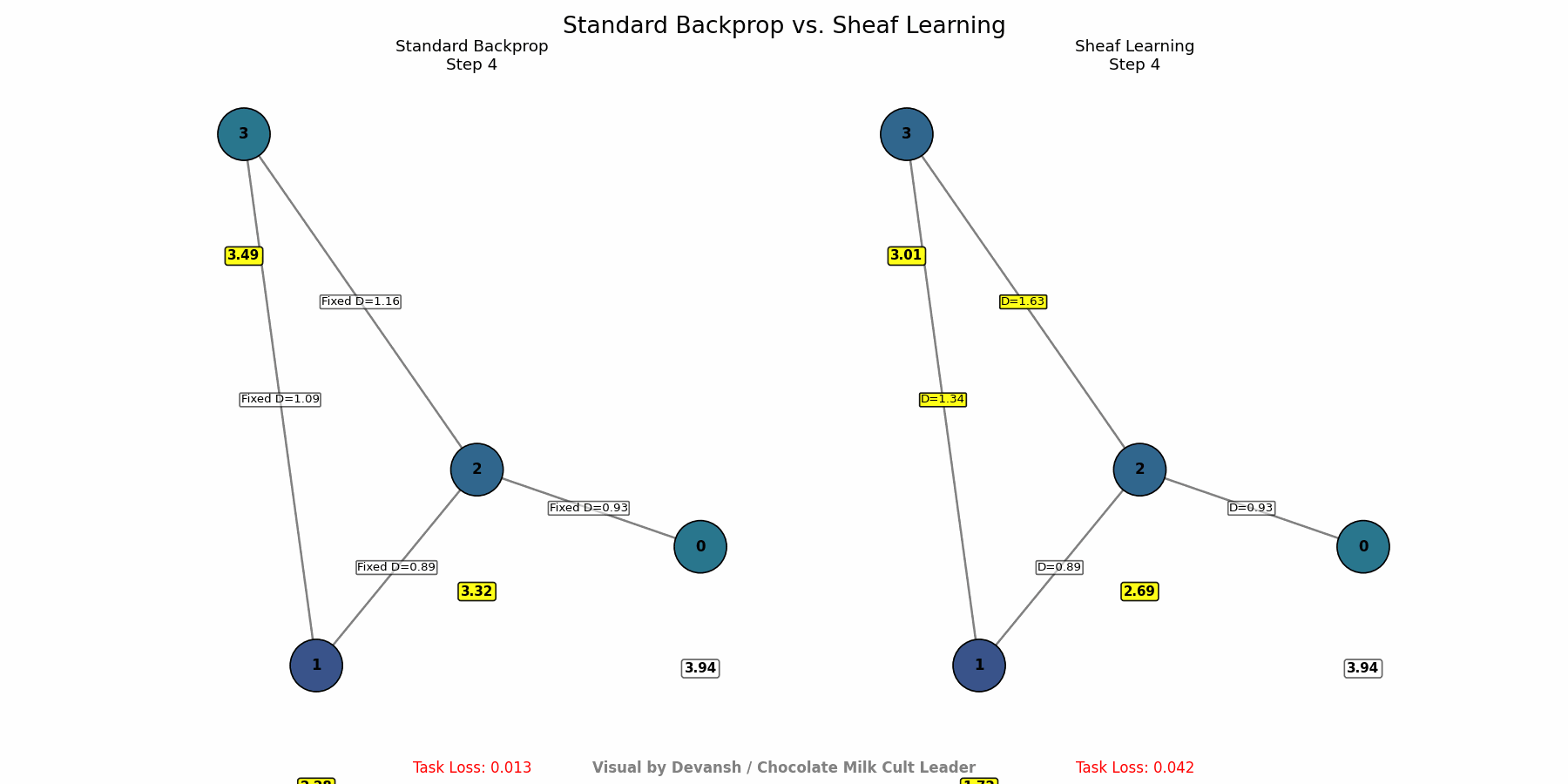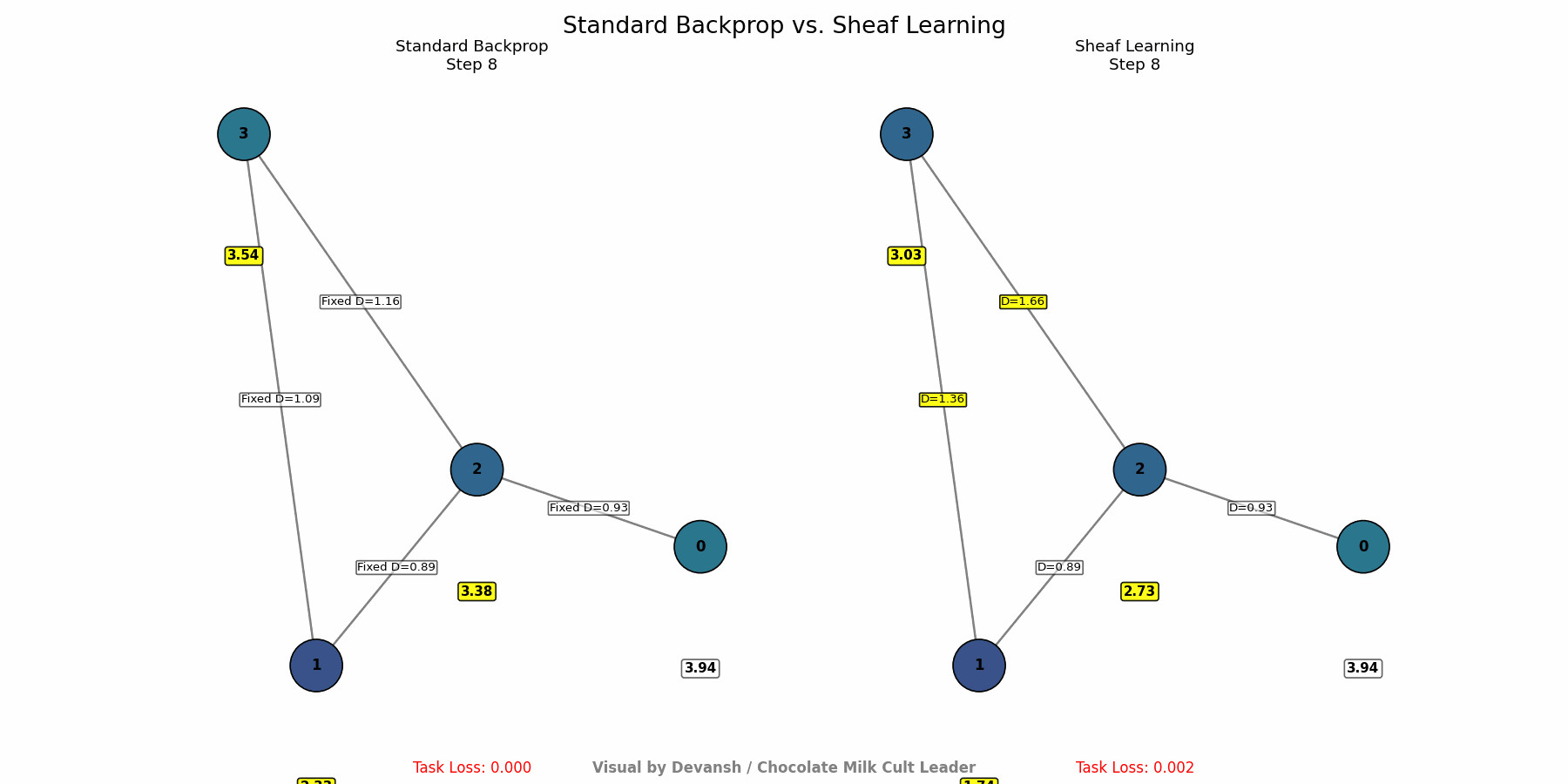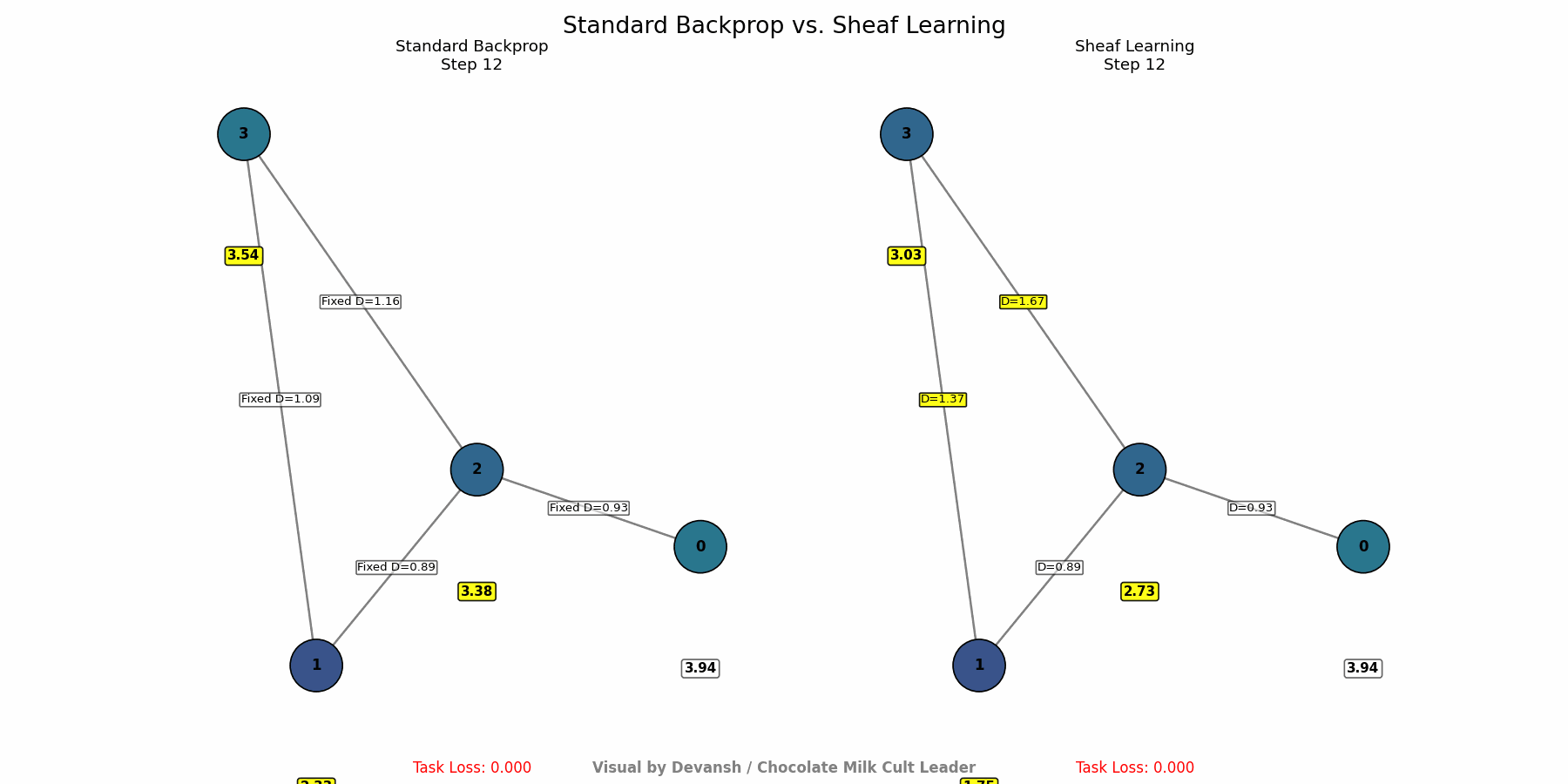
How to Use It: Deploy Sheaf Learning where interaction rules are complex, unknown, or change over time. There are several attributes that SL good for it-
Deep Adaptability: Sheaf Learning creates systems that can fundamentally reconfigure their internal logic in response to new data or changing environments, going far beyond simple fine-tuning. This is crucial for domains with evolving dynamics (markets, social trends, biological systems).
Knowledge Discovery: The learned structure maps themselves can be inspected. Optimal learned rules might reveal previously unknown relationships, correlations, or effective interaction mechanisms within the data, turning the AI model into a tool for scientific or business discovery. What kind of matrix best describes the influence between two node types? The learned sheaf provides an answer.
Implicit Regularization & Data Efficiency: By learning concise, powerful rules (structure maps), the system might rely less on brute-force memorization in node features. A well-learned sheaf structure captures relational information efficiently, potentially leading to better generalization from less data compared to models that must infer all relationships implicitly.
Personalization at Scale: Learned sheaves can naturally specialize. In a recommender system, the sheaf structure associated with a user could adapt based on their specific interaction history, leading to deeply personalized information flow.
All of these lead to Defensible Moats based on proprietary data. This was essentially what people thought fine-tuning would be. Industries like autonomous robots, personalized medicine, self updating financial trading bots can be huge updates. This style of thinking is already showing some major promise- the study, “Self-Evolving Neural Architectures: A Paradigm Shift in AI Scalability and Autonomy” leverages Self-Organizing AI to build distributed networks that are energy efficient, connected, and robust-
However this is the hardest angle here to crack, so let’s break this down into sub-problems and beat the Cell Jrs first-
Parameterization Design: Choosing the right functional form for learnable structure maps is key. Overly simple forms limit expressivity; overly complex forms risk overfitting and high computational cost. Research into effective and efficient parameterizations is vital.
Regularization: Preventing the learning process from collapsing into trivial (e.g., zero maps) or unstable sheaf configurations is crucial. Developing robust regularization techniques specific to sheaf learning is necessary.
Optimization Stability: The optimization landscape for learning sheaf structures can be complex. Ensuring stable and efficient convergence requires sophisticated optimization techniques.
Interpretability: Understanding what rules the system has learned remains challenging but offers significant insight if achieved.
The menaces deserve their own section, so let’s take a second to talk about them.
Section 4: The Terror Pit of Sheafs and How to Get Out
(most of you have unfortunately never played Duel Masters, and I’m so sorry to hear that)
Our 3 stallions of sheaf theory — cohomology for audits, Laplacians for dynamics, learning for adaptive physics — are potent. But let’s be real- we think Graphs are complex. Graph-based methods only handle pairwise interactions — basically “one link at a time.” And they already trouble scale-minded folk every day-
Sheaves, however, encode richer structures and explicitly check multi-level relationships. That is a whole new level of “wait till I call my big brother”.
Deploying sheaves effectively requires navigating specific, high-stakes engineering challenges. These challenges are where our Chimaevs are split from our Darren Tills. Here are the 3 biggest ones imo-
1. Computational Cost: The Price of Expressivity
(If you want Jensen Huang's attention, solve this. No comments on how I know)
“It should be mentioned that Roos complexes are sub-optimal for computing cohomology and for defining Laplacians due to their large size. Other cochain complexes can be used, leading to matrices of smaller size. This is an important issue in practice as well: both sheaf neural networks and more general cohomology computations suffer from large computational complexity”
Richer structure demands richer computation. Sheaf operations, especially global consistency checks via cohomology using theoretically optimal methods like the Minimal Cochain Complex involve steps that are inherently more complex than the simple matrix multiplies dominating GNNs. Without aggressive optimization, this “sheaf tax” can render models impractical.
Solution: Fund the development of production-grade, hardware-aware libraries for the minimal complex and sheaf Laplacians. Focus on sparse linear algebra, parallel execution, and exploiting structural regularity where possible. Benchmark relentlessly against graph methods on cost-per-insight.
Opportunity: Corner the market on specialized hardware (ASICs/FPGAs) designed to accelerate the specific linear algebra patterns emerging from sheaf computations (e.g., operations tied to incidence structures, Hodge Laplacians). This is important because it is an “easier” angle to attack and will act as a base for later innovation.
2. Modeling Skill: Architecting with Precision, Not Templates
Sheaf theory isn’t a drop-in replacement for GNNs; it demands deliberate modeling. Choosing the correct Poset structure to represent the system’s hierarchy and dependencies, and defining (or parameterizing for learning) the correct Sheaf structure maps to capture the interaction physics, requires a higher degree of precision and potentially domain expertise than simply defining graph adjacency. Poor choices lead to models that are complex and wrong.
Solution: Develop high-level modeling frameworks and Domain-Specific Languages (DSLs) that abstract the complexity of direct poset/sheaf definition, allowing experts to specify constraints and relationships more naturally. The language components should have an element of self-correction to them, fixing themselves and propagating signals based on user feedback. A mini-version of this has served us very well in Iqidis’s personalization and editable dynamic knowledge graph modules, both of which allow us to tailor the user's work style and preferences by interactively accommodating their feedback. It’s one of the many reasons that Iqidis is the best legal AI tool on the market :).
Opportunity: Fund research blending Topological Data Analysis (TDA) and causal inference with sheaf theory to automatically infer appropriate structural scaffolds (posets) and interaction rules (sheaf parameterizations) from data, reducing reliance on manual design. As stated earlier, LLMs should be very useful for quick prototypes that can be edited. This really opens this space as up, and this will likely be the first problem where some meaningful progress is made.
3. Scaling: From Academic Graphs to Industrial Reality
Demonstrating sheaf methods on graphs with billions of nodes and trillions of potential interactions — the scale of real-world platforms — is the critical, unproven frontier. Iterative diffusion processes and potentially global dependencies in cohomology present immense challenges for distributed computation, memory bandwidth, and communication overhead.
This is where I would disagree with the paper/what I’ve read about solutions. Imo, the best bet is to build a supervised learning AI to approximate early stages and skip ahead. We spoke about this in the context of diffusion over here-

This approach will be less precise than investing in a ground-up building, but I think it will be faster and easier to build on.
Fixing them will enable the development of the first generation of sheafy systems.
Got it. Stripping the recap, focusing solely on the forward-looking strategic mandate and concluding punch.
Section 5: Conclusion and the Future of Sheaf
The graph-based paradigm is reaching its structural limits for many complex tasks. The necessary evolution is clear: Posets and Sheaves provide a rigorous framework capable of handling the hierarchical, multi-level, rule-governed complexity of reality.
Mastering the associated engineering hurdles — efficient computation via optimized algorithms like the minimal complex, scalable infrastructure, and precise modeling tools — is not merely an R&D challenge; it is a huge play for leadership in next-generation AI. Solving the hurdles means coming into the space, throwing the board in the air, and hijacking what AI means to the boss man at the Halal Store, the way ChatGPT did.
Think about how cool that is.
Thank you for being here, and I hope you have a wonderful day.
If you caught every single Middleweight reference here, let’s get lunch together-
Dev <3
If you liked this article and wish to share it, please refer to the following guidelines.
That is it for this piece. I appreciate your time. As always, if you’re interested in working with me or checking out my other work, my links will be at the end of this email/post. And if you found value in this write-up, I would appreciate you sharing it with more people. It is word-of-mouth referrals like yours that help me grow. The best way to share testimonials is to share articles and tag me in your post so I can see/share it.

Reach out to me
Use the links below to check out my other content, learn more about tutoring, reach out to me about projects, or just to say hi.
Small Snippets about Tech, AI and Machine Learning over here
AI Newsletter- https://artificialintelligencemadesimple.substack.com/
My grandma’s favorite Tech Newsletter- https://codinginterviewsmadesimple.substack.com/
My (imaginary) sister’s favorite MLOps Podcast-
Check out my other articles on Medium. : https://rb.gy/zn1aiu
My YouTube: https://rb.gy/88iwdd
Reach out to me on LinkedIn. Let’s connect: https://rb.gy/m5ok2y
My Instagram: https://rb.gy/gmvuy9
My Twitter: https://twitter.com/Machine01776819
Interesting!