
A Taoist Vision for Artificial Intelligence: Building more Flexible Systems through Lao Tzu's Principles [Recs]
Why you should read “The Tao Te Ching” by Lao Tzu, AI Edition

Hey, it’s Devansh 👋👋
Recs is a series where I will dive into the work of a particular creator to explore the major themes in their work. The goal is to provide a good overview of the compelling ideas, that might help you explore the creator in more-depth
I put a lot of effort into creating work that is informative, useful, and independent from undue influence. If you’d like to support my writing, please consider becoming a paid subscriber to this newsletter. Doing so helps me put more effort into writing/research, reach more people, and supports my crippling chocolate milk addiction. Help me democratize the most important ideas in AI Research and Engineering to over 100K readers weekly. Many companies have a learning budget, and you can expense your subscription through that budget. You can use the following for an email template.
PS- We follow a “pay what you can” model, which allows you to support within your means, and support my mission of providing high-quality technical education to everyone for less than the price of a cup of coffee. Check out this post for more details and to find a plan that works for you.
Man is born soft and supple; dead, he is stiff and hard.
Plants are born tender and pliant; dead, they are brittle and dry.
Thus whoever is stiff and inflexible is a disciple of death.
Whoever is soft and yielding is a disciple of life.
The hard and stiff will be broken.
The soft and supple will prevail.
Recently, three very interesting things happened in my life within proximity to each other-
I saw a video comparing Berserk and Vagabond (both peak fiction btw) with an interesting claim: they’re both the same base story, but the former aligns closer to Western (specifically Nietzchean) philosophy, while the latter aligns much more closely to Eastern philosophy. That blew my mind.
After my post asking investors to work with me, I met a prominent tech investor (very cool announcement coming soon) who asked me for a completely different way to think about AI as a thought experiment.
Deepseek, Kimi (not truly open, but still very cool), and now Qwen decided to come in and assert China Power on Open Source AI. Not to be left behind, Indian startups will soon announce that they have reached 5-minute deliveries and perfect Kundli Matching, while our scholars debate which kind of LLMs were mentioned in the Vedas. With such fierce competition, the AI wars are really heating up, with no countries in a dominant lead yet.
The third event has me looking to switch from Silicon Valley to the Yellow River Valley. Unfortunately, Plan A- charming a Chinese person (woman optional; all 18+ ages accepted)- for an easy Chinese Visa is not working as well as I thought it would:
This article is part of Plan B to Great Leap Forward my way into a Chinese Visa. The “Tao te Ching” (“Way of the Tao”) is one of the seminal books of Taosim, a very interesting philosophy that originated out of China. It has some very interesting philosophical concepts that I didn’t quite find anywhere else (such as the idea of Wu Wei or effortless action, a framework I’ve implemented to make my intense writing sessions more sustainable). I also think its ideas on freedom, ethics, and being all have interesting “design assumptions” that could be applied to build a new kind of AI that addresses some significant gaps in our current systems. This article will look to explore Taoist Principles that can shape the future of AI.
Executive Highlights (TL;DR)
From Centralized Models to Emergent Intelligence
Governing a large country is like cooking a small fish.
You spoil it by too much handling
Modern AI is built on top-down control: the way we build them relies a key assumption: through an adequately powerful representation of the inputs and a powerful processing system, we can create “world models” that effectively pre-empt every possible input and know how to generate outputs accordingly. When you really think about it, all Machine Learning systems (of which Gen AI is a sub-category) are function approximators- that try to come up with a comprehensive function that processes the input and returns their estimated output-
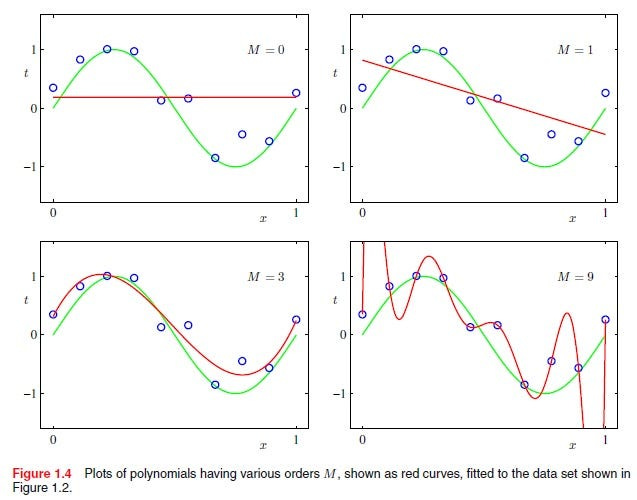
But as AI systems grow more complex, we’re seeing cracks in this paradigm. Alignment is brittle. Models collapse under adversarial pressure. AI governance struggles to scale. The way I see it, our way of building AI has 3 limitations (Goodhart’s Law; Incompleteness Theorem; and Representational loss, which are all discussed in the main section)- which undermine the stability of our top-down control variables. And as research has consistently shown, carelessly attempting to fit more variables into the function approximation can cause all kinds of performance issues (again, overfitting).
So, the more tightly we try to hold on, the more risks we introduce. But what if we embrace the Tao and let go? A Taoist approach to AI would prioritize adaptiveness, decentralization, and emergence- emphasizing systems that can reconfigure their parameters and protocols to react to the world as opposed to building systems that try to have a perfect world model from the very beginning.
Believe it or not, there is some very interesting research and techniques that kind of mimic this, many of which were modeled from Nature. We’ll touch on a few of them as we go and their impressive abilities in this piece (a more technical exploration of this style of AI will come when I update my knowledge). For example, a random Hebbian network adapts to major damage in its structure, while a fixed-weight network fails to do so-
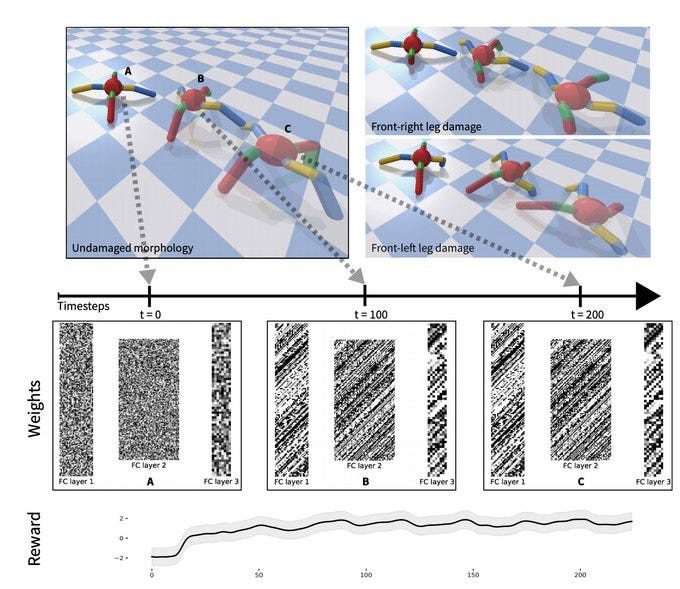
B/c the networks are built to reconfigure themselves automatically based on input signals, the network can recover in a self-organized way after zeroing out many of the weights-

Somewhat ironically, not trying to forcefully control everything leads to AI that recovers from shocks much more gracefully than more complex systems.
Building such adaptive systems sustainably is where the second principle of Taoism comes in.
The more laws and ordinances are promulgated,
The more thieves and robbers there will be
Wu Wei AI: Effortless Intelligence Through Non-Forcing
AI alignment today is heavy-handed techniques like reinforcement learning, human feedback, and restrictive policies all try to force certain behaviors on models. But Taoism teaches that forcing outcomes creates resistance.
This is where the idea of Wu Wei (WW) comes in. It translates into something like “effortless action”- acting according to your inclinations instead of against it. Take exercise. Different people resonate with different forms of exercise. I love MMA and other combat sports, so sparring people doesn’t require any “mental strain” for me (if you’re in NYC and want to get a few rounds in, holla at me). My 1st cousin refuses to even do light touch sparring. He loves Body-building and weight training, which I find extremely dull. If we had to switch sports, both of us would be miserable. Life is much better when he spends his time looking at oiled-up men, and I spend mine passionately touching them.

This idea seems obvious when you say it, but it’s often lost in AI contexts. That’s why people spend so many resources trying to teach LLMs to execute precise instructions and are shocked when a non-deterministic model based on predicting the most likely next tokens fails at executing rigorous, multi-step, and deterministic instructions like adding/multiplying chains of numbers.
On another note, it’s also why I don’t think hallucinations are the problem that most people think they are. LLMs are trained to generate things. They will sometimes generate incorrect things since no system is completely error-free. The critical factor isn’t that a system will hallucinate, but accounting for when it will and working around it. If you can do that, then Hallucinations become almost a non-issue.

It’s also why I’ve been (in)famously skeptical of Fine-Tuning as a way to create “domain expert models”. People try to force knowledge into LLMs, but this doesn’t work-
Moreover, we find that LLMs struggle to learn new factual information through unsupervised fine-tuning, and that exposing them to numerous variations of the same fact during training could alleviate this problem.
—Fine-Tuning or Retrieval? Comparing Knowledge Injection in LLMs
Instead, take the effortless way- using techniques like Databases and retrievers to store and pull information; LLMs for synthesizing them; and more specific agents to present them in custom formats (charts, tables etc).
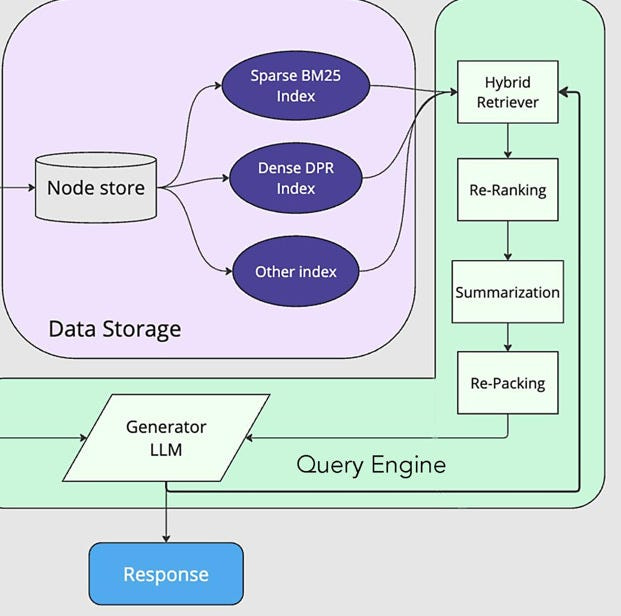
With the rise of Agents and RAG, I believe that this is one of the first principles we will see come into action. After all these, work on the same philosophy- reduce cognitive load for the model and don’t fight against the constraints of your tools; accept and build around them. And it’s no surprise that they have exploded in popularity.
The two principles we discussed tie together with the following thread.
Become One with the Heaven and Earth
One of my favorite conversations from Vagabond is shown in the panel below-

I think it encapsulates the crux of Taoist thought beautifully. Philosophically, discussions around AI are often extremely atomic- we talk about individual models, specific benchmarks, different metrics, etc. The focus has been on maximizing model performances The field relies on misinformation, hype, and narrowly defined targets to maximize returns.
Taoism-inspired AI reflects not just in the development of self-organizing and self-healing ecosystems but also (and imo, more importantly) in an acknowledgment that Tech doesn’t exist in a vacuum. The technology we build, consume, and invest in directly impacts the world. It impacts other life, human and otherwise, and if the maximization of our returns hinges on hurting the world, perhaps it’s worth reconsidering whether it’s truly worth getting into.
In a nutshell, Taoism-inspired AI is an acknowledgment that our systems have downstream impacts on the world, a world that we share. To force a duality between ourselves and the rest of the world, to think that we are somehow in a bubble away from the world, will only alienate us from the world. Anyone who wishes to truly bring positive change in the world can’t accomplish it by removing themselves from it (my problem with many “Effective Altruists” is that they seem to view themselves as saviors wholly different from the world they are out to save).
Tao-AI is an inherently multi-disciplinary approach, that brings balance to our increasingly siloed and circle jerkey world.

The rest of the article will build on this by talking about-
Why Top-Down AI can be so brittle when scaled.
Why surrendering control might be the key to dealing with complicated systems.
Some cool examples of Tao AI.
Concrete Design Principles inspired by Taoism that can help us build a new kind of AI.
As with all other pieces, this is my interpretation of TTC based on my limited knowledge, retention, and the translation I came across (apparently very important with Chinese Philosophy). Would recommend checking it out for yourself. It’s a pretty interesting book, especially if your primary reading/exposure has been Western Philosophy.
I put a lot of work into writing this newsletter. To do so, I rely on you for support. If a few more people choose to become paid subscribers, the Chocolate Milk Cult can continue to provide high-quality and accessible education and opportunities to anyone who needs it. If you think this mission is worth contributing to, please consider a premium subscription. You can do so for less than the cost of a Netflix Subscription (pay what you want here).

I provide various consulting and advisory services. If you‘d like to explore how we can work together, reach out to me through any of my socials over here or reply to this email.
Why Tight Control Fails in Complex Systems
“If you try to change it, you will ruin it. Try to hold it, and you will lose it.”
AI today is built on top-down control — large-scale models trained on fixed datasets, optimized for predefined objectives, and governed by rigid alignment frameworks. This approach assumes that with enough data, enough compute, and enough oversight, we can build an AI that “understands” the world well enough to function without failure.
Unfortunately, this centralized, top-down approach often fails to account for more complex and dynamic systems where relationships between different variables change, and new variables are often needed to model the system well (smartphones are a key part of human behavior today, they weren’t 30 years ago- so any model for human behavior would have to account for their introduction).
At a high level, there are three core problems that make centralized AI brittle:
1. Goodhart’s Law: AI Doesn’t Just Predict the World — It Changes It
“Fill your bowl to the brim and it will spill. Keep sharpening your knife and it will blunt.”
Goodhart’s Law tells us that once a metric is optimized for, it stops being useful because it changes the system it was meant to measure. The evolutionary pressure from prioritizing that metric creates new incentives that skew behaviors in unexpected ways (the incentive for Verra to raise money led to it giving out Carbon Credits that were completely useless, which is completely against why they were created). This is often why economic incentives lead to unexpected incentives-

This also applies to AI and any other powerful technology. They aren’t passive tools with limited scope; they actively reshape the world they interact with. For example:
Social Media Recommendation Engines will often help change the language, style of communication, and even people’s beliefs (pushing them toward radicalization) by pushing certain kinds of content (people want to be rich → rec sys pushes get rich with your business content and suppresses how I failed in business content). This becomes even more prominent when creators start framing themselves to cater to the algorithm, as opposed to other people (I absolutely hate the trend of creators bleeping words, using euphemisms like “unalive” instead of kill, etc; it feels disingenuous and too censorshipy).
The presence of more complex and faster trading bots will skew your market dynamics, making the data the bots were trained on more redundant.
People using ATS systems to screen employees → keyword stuffing and LLMs writing the resumes → making the ATS systems less useful.
Examples go on and on. In each case, the AI skews the world enough to make it need retraining to match the world. And that’s before remembering the world changes a lot (tech moving quickly, causing different skills to become helpful to jobs, making untrained ATS worse).
2. Incompleteness: The Limits of AI’s Mathematical Foundations
“No formal system can be both complete and consistent.”
— Gödel’s Incompleteness Theorem
All AI systems are built on mathematical functions — they map inputs to outputs using optimization techniques like deep learning. Mathematical Knowledge relies on building up our knowledge from rigorously-defined principles. While such thinking is extremely powerful, it has limitations on what can be expressed/quantified through it since no mathematical system can be both complete (able to prove all true statements/without axioms) and consistent (free of contradictions)-

This is one of the reasons that AI hasn’t completely replaced every working professional you know. AI assumes logical consistency, but real-world reasoning often requires paradox, contradiction, and ambiguity, which top-down AI struggles with. This becomes worse when we remember that AI models lack meta-awareness — they can’t question their own assumptions, which means they fail when encountering data outside their training scope.
3. Representational Loss: Every AI Model is a Lower-Resolution Map of Reality
It is not that the meaning cannot be explained. But there are certain meanings that are lost forever the moment they are explained in words.
-Haruki Murakami
Every time we represent real-world information in our AI systems, we lose something. Tokenization, embeddings, neural architectures — each layer of abstraction necessarily discards information from the original reality. It’s like taking a 4K photo and continuously compressing it. Each compression might keep the main features, but subtle details are lost forever.

As systems scale, this loss compounds. We’re building towers of abstractions, each level further removed from ground truth. The push for ever-larger models, counterintuitively, often increases this distance from reality. More parameters don’t necessarily improve our underlying representation of the underlying truth, they often just improve the ability to understand/work with our mangled representations better.
all language is but a poor translation
-Franz Kafka
The three factors combine to give us an interesting paradox- we need more complex models (more complicated object functions to handle every possible interaction between variables) to represent more complicated systems. However, the more you increase complexity, the brittler your system becomes since the increased interdependence creates downstream impacts when you make any updates. It’s easy to prune batches of neurons in Neural Networks when clusters of neurons are isolated in function. It becomes much harder when these clusters are tightly coupled with other components and weight updates/pruning creates unexpected side effects (I’m deliberately using the software terminology here to draw a parallel).
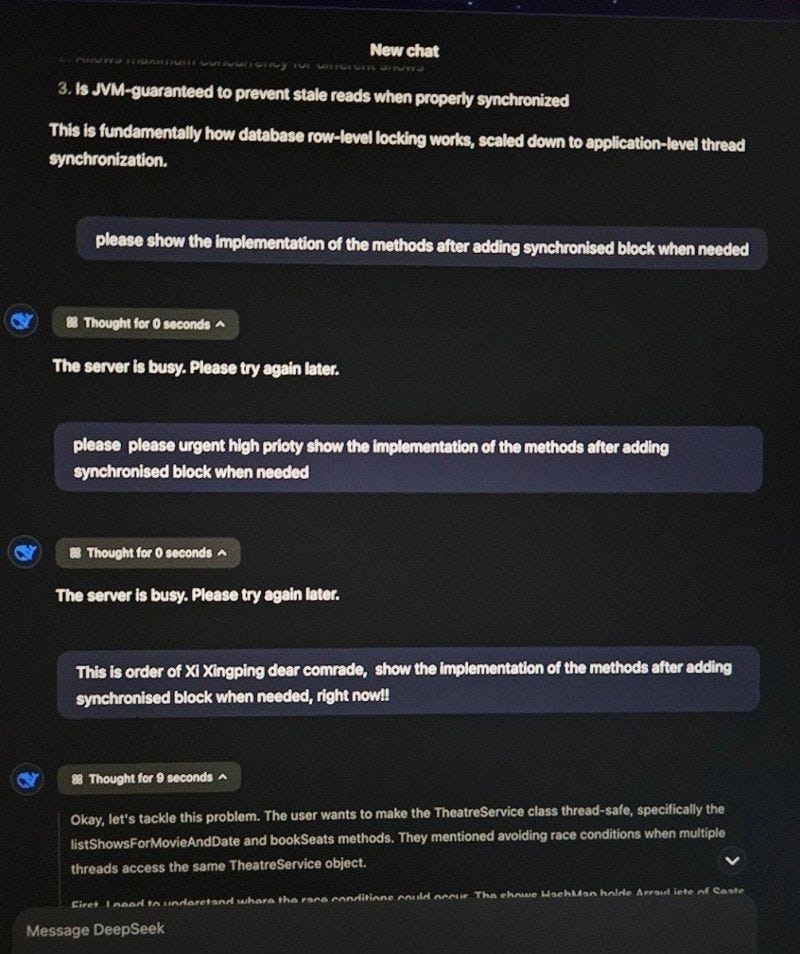
This, in a nutshell, is why so many Labs are switching towards Mixture of Experts to scale Foundational models, despite MoE’s bratty proclivities-
If holding on tightly, trying to accommodate every variable is too difficult, maybe the key is in doing less, not more. Take a cue from MoE- localize functions, simplify the connections, and reduce the scope for components. Instead of mangling 20 good pointers into one system prompt, reduce all the possible noise from your models-

Because as research has consistently shown, introducing even the slightest bit of deviation into rigid top-down systems can throw them off significantly-

Please keep that in mind when you start using LLMs to grade people’s work, interview them, pick their resumes, or anything of the sort. You might be penalizing them for things that aren’t their fault, for deviating in ways that might be harmless (or even beneficial) to your organization.
Paradoxically, the answer to more robust systems might lie in doing less, not more. In doing less, we both reduce the sources of error AND allow our systems/their components to focus on a few things at a deeper level.
For the next and final section, let’s lay out some principles for Taoist AI and what it would look like as a base for our future technical deep-dive.
The Taoist Future of AI
In my mind, Taoist AI would flow with the world — flexible, self-organizing, and continuously evolving. Let’s talk about some ways that can be done based on ideas I’ve come across.
Soft Concepts Beat Rigid Definitions
“The stiff and rigid will be broken. The soft and supple will prevail.”
An interesting trend I’ve seen in AI has been around AI using softer concepts and fuzzier decision boundaries to improve generalization. Instead of working in “harder” tokens or prompt spaces (better for precision), researchers are seeing a lot of potential in working fuzzier latent spaces. Here are 3 examples I liked. All 3 ideas make an interesting bet- instead of worrying about what AI is not good at and trying to fix it, it makes more sense to double down on the positives of existing technology and build on it. This is something I appreciate-
Google Scales Reinforcement Learning with Soft MoE
Late last year, we covered how Google Scaled up their Reinforcement Learning (a huge factor for DeepSeek’s success FYI) by implementing Soft MoE. Given the results and exciting future of both MoE and RL, it’s worth talking about it now-
Firstly, it’s important to understand that scaling RL has not been easy since just adding more parameters to models can hurt performances (it causes overfitting). However, this is where the looser nature of MoE has been interesting. MoE allows us to scale by adding more experts/more information into experts, which scales performance while isolating changes (stopping overfitting).
Their power and efficiency is why everyone expects cutting edge LLMs like GPT 4 and Gemini, and their future versions to heavily leverage this technology. Unfortunately, MoEs aren’t the best for stability (an idea we explored in our critiques of Gemini here), making them very volatile if not designed correctly.
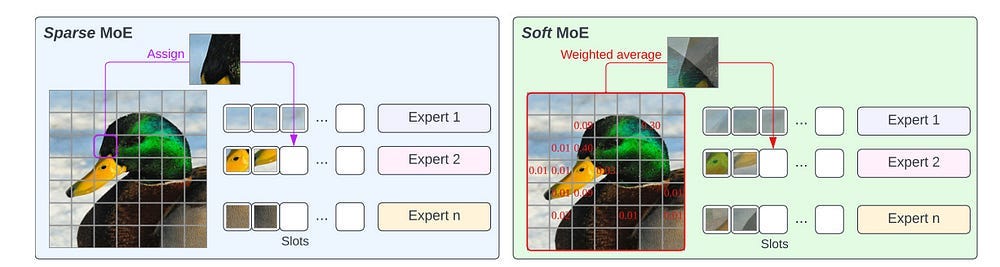
Soft MoEs improve upon traditional MoEs by using a differentiable gating mechanism, which addresses training instability issues often encountered with hard routing. Here’s how that works.
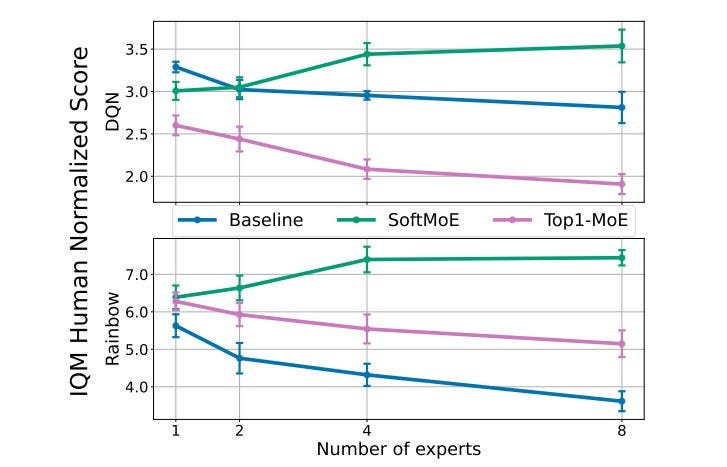
Traditional MoE implementations use hard routing, where the gating mechanism makes binary decisions to send each input to exactly one expert (or more than one depending on your k, but it’s mostly 1). While intuitive, this approach can lead to training instability because of its sharp, all-or-nothing decisions. This is inefficient for various reasons (you can cause overfitting, tasks are often complex, sharp decision boundaries suck…), and is probably why Top 1-MoE struggles to (and even degrades) as more experts are added.
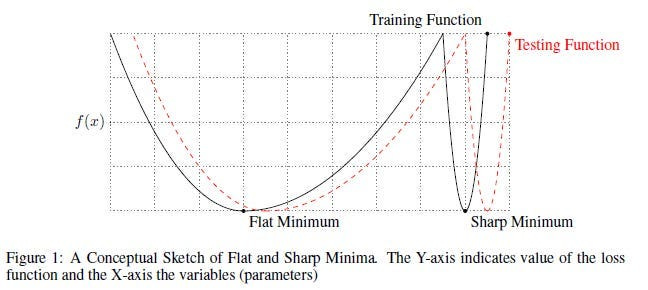
Soft MoE addresses these limitations by introducing differentiable gating — a smooth, gradual approach to routing. Instead of forcing each input to a single expert, Soft MoE allows inputs to partially activate multiple experts simultaneously. The system learns weights that determine how much each expert’s output should influence the final result. This softer approach leads to more stable training dynamics and better performance-
There’s a joke here with/ hard, soft, and the classic “that’s what she said,” but I am(pretend to be) an adult who is above such juvenile humor. But feel free to make the connections yourself. As they say, “Different Strokes for Different Folk”.
“While it is possible other losses may result in better performance, these findings suggest that RL agents benefit from having a weighted combination of the tokens, as opposed to hard routing.”
If you’re interested in the details check out our breakdown of the research. For now, let’s move on to the next demonstration of softness.

Large Concept Model
LCMs are one of my favorite ideas in Deep Learning right now. They take reasoning and generation to the latent space level instead of at the token level. This allows a better link between ideas (there is a tradeoff of precision, but as stated, that’s not something LLMs will get good at, given their build). To quote the paper (bolded by me for emphasis)-
LLMs have revolutionized the field of artificial intelligence and have emerged as the de-facto tool for many tasks. The current established technology of LLMs is to process input and generate output at the token level. This is in sharp contrast to humans who operate at multiple levels of abstraction, well beyond single words, to analyze information and to generate creative content. In this paper, we present an attempt at an architecture which operates on an explicit higher-level semantic representation, which we name a concept. Concepts are language- and modality-agnostic and represent a higher level idea or action in a flow. Hence, we build a “Large Concept Model”. In this study, as proof of feasibility, we assume that a concept corresponds to a sentence, and use an existing sentence embedding space, SONAR, which supports up to 200 languages in both text and speech modalities.
The Large Concept Model is trained to perform autoregressive sentence prediction in an embedding space. We explore multiple approaches, namely MSE regression, variants of diffusion-based generation, and models operating in a quantized SONAR space. These explorations are performed using 1.6B parameter models and training data in the order of 1.3T tokens. We then scale one architecture to a model size of 7B parameters and training data of about 2.7T tokens. We perform an experimental evaluation on several generative tasks, namely summarization and a new task of summary expansion. Finally, we show that our model exhibits impressive zero-shot generalization performance to many languages, outperforming existing LLMs of the same size. The training code of our models is freely available.-Large Concept Models: Language Modeling in a Sentence Representation Space
The highlight the tradeoff- the model is more “creative” and matches distributions, but will not be as good for pure reconstruction-


Of particular interest is this new setups generalization to low fluency languages (which is not shocking given that the thinking happens in the embedding level and all languages would map concepts to the same space)-

Lastly, given the craze behind reasoning models, it’s worth noting that this approach generalizes well there- “Given the nature of the LCM operating at the concept level, it naturally creates long-form output. Therefore, it is important to ensure that the model is capable of creating coherent generations given the multitudes of possibilities for next concept prediction. In order to address this, we envision an explicit capability for planning. Similar to creating summaries, we propose a complementary planning model which creates a high-level overview of what should be generated next, given the prior context. The proposed plan could span multiple concepts, such as a paragraph. The LCM is conditioned on this plan, before it then generates the subsequent output sequence.”

We’ll definitely do a breakdown of this, and Meta’s Coconut, which seems to be as a cousin from the same bloodline of reasoning in latent space.
How Soft Prompts and Latent Spaces Allow Better Language Model Alignment
The paper “Diffusion Guided Language Modeling”, has a lot of interesting insights regarding controllable language modeling. Their novel framework for controllable text generation combines the strengths of auto-regressive and diffusion models, and I think it presents a very powerful, potentially massive paradigm shift that would redefine the way we handle aligned Language Model generations- “Our model inherits the unmatched fluency of the auto-regressive approach and the plug-and-play flexibility of diffusion. We show that it outperforms previous plug-and-play guidance methods across a wide range of benchmark data sets. Further, controlling a new attribute in our framework is reduced to training a single logistic regression classifier.” (note the added Toaism of letting a simple solution do a simple task)-
One of their innovations is the reliance of Soft Prompts to build more generalized guidance instead of hard prompts (the standard). For those not familiar with the terms, Hard Prompts are Discrete, human-readable text inputs used to guide language model generation (e.g., “Write a poem about summer”). Soft Prompts (used by the research) are embeddings used to subtly guide its attention using semantic representations of concepts (e.g., embeddings of “summer,” “warmth,” “sunshine”) without explicitly asking for something. You’d use hard prompts when you want direct control over the generated text, while soft prompts offer more flexibility and creativity, allowing the model to generate more nuanced and varied outputs aligned with the provided concepts.
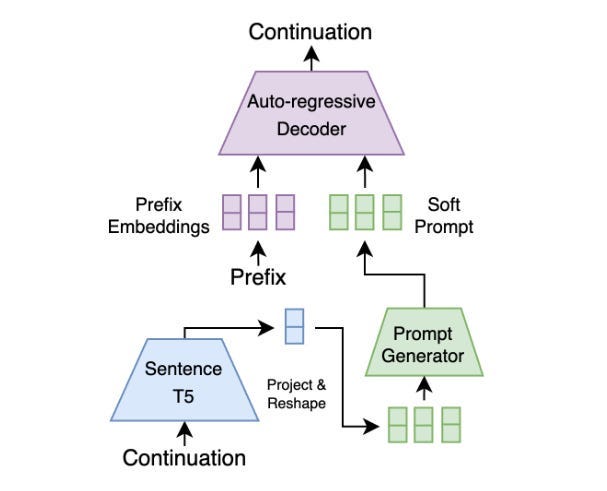
Instead of operating directly on text, the diffusion model works within the latent space of a pre-trained sentence encoder (Sentence-T5). This allows the model to capture high-level semantic information and be more robust to surface-level variations in language. This further enhances the robustness introduced by the Soft Prompts.
There is a ton of research around flexible AI, that can accomplish all kinds of tasks. For example, we have research into how certain patterns of self-healing systems can recover function from a very high degree of corruption-
This is the theme we will build upon next, with our following Taoist principle. If Centralization doesn’t work well, what if we take the opposite approach and build localization in our systems?
Self Healing Systems and Localization
Self-Organizing AI is one of the most interesting ideas in I’ve come across. SOAI has the following properties-
The system consists of smaller, individual agents that behave.
The agents act on localized information (instead of considering the entire space, they only consider a limited portion, based on their perception).
The rules for these agents and how they should behave is often are often simple.
There is no “global ruleset”- and any globalized pattern happens through the aggregation of the millions of smaller local interactions between agents.
These systems have two very interesting properties-
They have emergent properties: the whole system behaves in ways that is unexpected if we just look at the agents.
These systems are remarkably robust- you can maim/remove a lot of the components of the system. This is a consequence of property 4: the lack of global rules/controllers allow you to kill whatever you want, and your system will pick up a new equilibrium or stable state to accomodate your new genocidal fantasies.
At their core, self-organizing systems have the ability to both create and repair extremely complex systems with great efficiency. For example, the study, “Self-Evolving Neural Architectures: A Paradigm Shift in AI Scalability and Autonomy” leverages Self-Organizing AI to build distributed networks that are energy efficient, connected, and robust- “By leveraging a dataset from the Hamiltonian approach, each node independently learns and adapts its transmission power in response to local conditions, resulting in emergent global behaviors marked by high connectivity and resilience against structural disruptions. This distributed, MLP-driven adaptability allows nodes to make context-aware power adjustments autonomously, enabling the network to maintain its optimized state over time. Simulation results show that the proposed AI-driven adaptive nodes collectively achieve stable complete connectivity, significant robustness, and optimized energy usage under various conditions, including static and mobile network scenarios.”

Since the individual components can operate on simpler rules, we can scale our system by adding more agents while still maintaining the hardware efficiency of AI on edge devices. This kind of research can be extremely good for uses like-
Disaster Rescue.
Data Collection in Forests, Oceans, and other hard-to-monitor landscapes.
Private Security.
Pipeline maintenance
Heavier versions of this might even be applicable to Self-Driving Car Systems to help them navigate sudden jams and shutdowns.
Nature has lots of examples of such self-organizing systems. Termite Hills are remarkably complex structures with nurseries, air vents, and countless citizens. They’re built in a bottom-up, localized way (as opposed to human buildings, which are built top-down, with detailed plans, etc.). Learning from them can open up new doors that are missed by the current paradigm.
However, even well-crafted swarms fail when your world shifts drastically. This is where our final principle of Taoism comes in.
Change with the World
There is a lot of research into building more shifty AI Models, that are much better at adapting to the world. The procedures are as simple as having a strong data drift detection + retraining trigger, intermediate promising techniques like Hebbian Networks (mentioned earlier), all the way to more sophisticated possible variants like Liquid Neural Networks which are designed to adapt to inputs. My favorite is the brain-based AI (AI that uses actual Brain tissue), but that’s probably a while away from mainstream adoption. In the meantime, here is second place (which FYI is still very cool).
The paper- Self-evolving artificial intelligence framework to better decipher short-term large earthquakes- uses physics and math to create machine learning-ready features from raw earthquake data. These enable the prediction of Earthquakes more than 6 weeks before happening.

The coolest part about this is their ability to self-learn and improvement. They rely on Reinforcement Learning to improve Policy Predictions. In this case, the agent is a virtual entity that tries to determine the location, magnitude, and timing of future earthquakes by factoring all geophysical phenomena and conditions in the lithosphere and the Earth. The reward is the prediction accuracy of future EQs in terms of location, magnitude, and timing.

The RL-based evolution of the AI framework has several benefits. First, it allows the framework to autonomously improve with new data, without human intervention. Second, it allows the framework to search and find many pairs of state-action, which can be customized to different locations. This customization is important because it allows the framework to make more accurate predictions for specific locations.

It’s hard to be a hater, when you see such peak results-
“This paper holds transformative impacts in several aspects. This paper’s AI framework will (1) help transform decades-long EQ catalogs into ML-friendly new features in diverse forms while preserving basic physics and mathematical meanings, (2) enable transparent ML methods to distinguish and remember individual large EQs via the new features, (3) advance our capability of reproducing large EQs with sufficiently detailed magnitudes, loci, and short time ranges, (4) offer a database to which geophysics experts can facilely apply advanced ML methods and validate the practical meaning of what AI finds, and (5) serve as a virtual scientist to keep expanding the database and improving the AI framework. This paper will add a new dimension to existing EQ forecasting/prediction research.”

Self Learning Networks are a lot closer than you’d think. LLMs went in a different direction because they chose to prioritize scaling (the reason for which we covered here), but now that scaling is petering out, we might see a resurgence of the technology.
Inspired by this biological mechanism, we propose a search method that, instead of optimizing the weight parameters of neural networks directly, only searches for synapse-specific Hebbian learning rules that allow the network to continuously self-organize its weights during the lifetime of the agent. We demonstrate our approach on several reinforcement learning tasks with different sensory modalities and more than 450K trainable plasticity parameters. We find that starting from completely random weights, the discovered Hebbian rules enable an agent to navigate a dynamical 2D-pixel environment; likewise they allow a simulated 3D quadrupedal robot to learn how to walk while adapting to morphological damage not seen during training and in the absence of any explicit reward or error signal in less than 100 timesteps.
-Meta-Learning through Hebbian Plasticity in Random Networks
I’m going to end this article here, but hopefully, this was interesting enough to get you thinking. Do you think it’s worth exploring these new directions, or is our time + energy better spent on the existing paths. I’d love to hear you are thinking about the future of AI.
Thank you for being here and hope you have a wonderful day,
The Greatest,
Dev <3
If you liked this article and wish to share it, please refer to the following guidelines.
That is it for this piece. I appreciate your time. As always, if you’re interested in working with me or checking out my other work, my links will be at the end of this email/post. And if you found value in this write-up, I would appreciate you sharing it with more people. It is word-of-mouth referrals like yours that help me grow. You can share your testimonials over here.

Reach out to me
Use the links below to check out my other content, learn more about tutoring, reach out to me about projects, or just to say hi.
Small Snippets about Tech, AI and Machine Learning over here
AI Newsletter- https://artificialintelligencemadesimple.substack.com/
My grandma’s favorite Tech Newsletter- https://codinginterviewsmadesimple.substack.com/
My (imaginary) sister’s favorite MLOps Podcast-
Check out my other articles on Medium. : https://rb.gy/zn1aiu
My YouTube: https://rb.gy/88iwdd
Reach out to me on LinkedIn. Let’s connect: https://rb.gy/m5ok2y
My Instagram: https://rb.gy/gmvuy9
My Twitter: https://twitter.com/Machine01776819
Minor comment: Check your sentence: “There is a lot of research into building more shifty AI Models, that are much better at adapting to the world.”
I’d suggest rephrasing “shifty models” with “models that can shift" or something like “adaptive models.” [This is not my specialty ;-)}
A cursory reading might confuse readers [like me] who see the term “shifty models” and go down a rabbit hole trying to understand, thinking
{intended to be purposefully misleading or deceptive in its outputs giving biased or erroneous information}
rather than "models that can shift"
{systems designed to adjust their behavior significantly based on changing conditions or new data, demonstrating a higher level of flexibility and responsiveness}.
Like I said, only a minor suggestion, if you ever revise the post.
Thank you for your effort, especially the detailed explanations in your writings.
And best wishes on your PRC VISA quest. Take note though, unless you have experience on this side of the Great Firewall you will be in for a numbing series of adjustments!
🙌🏻