
The Real Cost of Open-Source LLMs [Breakdowns]
A ground-level audit of how much “free” models actually cost when taken to production.

It takes time to create work that’s clear, independent, and genuinely useful. If you’ve found value in this newsletter, consider becoming a paid subscriber. It helps me dive deeper into research, reach more people, stay free from ads/hidden agendas, and supports my crippling chocolate milk addiction. We run on a “pay what you can” model—so if you believe in the mission, there’s likely a plan that fits (over here).
Every subscription helps me stay independent, avoid clickbait, and focus on depth over noise, and I deeply appreciate everyone who chooses to support our cult.
PS – Supporting this work doesn’t have to come out of your pocket. If you read this as part of your professional development, you can use this email template to request reimbursement for your subscription.
Every month, the Chocolate Milk Cult reaches over a million Builders, Investors, Policy Makers, Leaders, and more. If you’d like to meet other members of our community, please fill out this contact form here (I will never sell your data nor will I make intros w/o your explicit permission)- https://forms.gle/Pi1pGLuS1FmzXoLr6
I keep hearing the same thing:“Open-source LLMs are free.”
That statement is wrong. Technically. Economically. Strategically. And if you're building anything serious, it’s dangerously naive.
After DeepSeek’s release, “open-source” became the new flex word for VC pitches and LinkedIn posts. As someone who helps lead one of the largest open-source AI research communities in the world, I’m glad it’s receiving attention. But there’s a problem: most people throwing it around don’t understand what it actually takes to use these models in the real world.
This article breaks it down. No fluff, no fantasy. Just the full cost ledger of deploying open-source LLMs at scale: inference, integration, monitoring, upgrades, staffing, and more.
I'm not anti-open source. Far from it. I’ve written elsewhere about why open source is very good business. But worshipping OSS without understanding its operational weight is how you end up bleeding money and shipping broken products.
Because you probably think Open Source LLMs are free.
But you probably also thought that Jake Paul vs a 60-year-old Mike Tyson was going to be a close fight worth watching.
You stupid, stupid, crayon snorter.

Executive Highlights (TL;DR of the Article)
Open-source LLMs are not free — they just move the bill from licensing to engineering, infrastructure, maintenance, and strategic risk.
Even a minimal internal deployment can cost $125K–$190K/year.
Moderate-scale, customer-facing features? $500K–$820K/year, conservatively.
Core product engine at enterprise scale? Expect $6M–$12M+ annually, with multi-region infra, high-end GPUs, and a specialized team just to stay afloat.
Hidden taxes include: glue code rot, talent fragility, OSS stack lock-in, evaluation paralysis, and mounting compliance complexity.
Most teams underestimate the human capital cost and the rate of model and infra decay. OSS gives you flexibility — until you’re too deep to pivot.
The download is free. The cost is operational.
The rest of this article will break down the costs of running an open source model, focusing largely on the additional costs that would be minimized/negligible if you were just calling the API bro. Specifically, we will look into the following cost centers-
The Human Capital Toll — Even pre-trained models need expert handlers
Infrastructure & Operational Bleed — Where “free” goes to die
Maintenance & Support — The forever-job no one tells you about
Strategic Miscalculations — The quiet implosions OSS can trigger
Cost Scenarios — Real-world deployments, real price tags

I put a lot of work into writing this newsletter. To do so, I rely on you for support. If a few more people choose to become paid subscribers, the Chocolate Milk Cult can continue to provide high-quality and accessible education and opportunities to anyone who needs it. If you think this mission is worth contributing to, please consider a premium subscription. You can do so for less than the cost of a Netflix Subscription (pay what you want here).

I provide various consulting and advisory services. If you‘d like to explore how we can work together, reach out to me through any of my socials over here or reply to this email.
Section 2: The Human Capital Toll: Even Pre-Trained Models Need Expert Handlers
Open source doesn’t mean zero effort. It just means someone else did the upstream heavy lifting. You still have to get the thing working in your system, for your data, at your latency, under your constraints. And guess what? That’s where most teams bite the dust.
You’re not building the LLM. But you do have to build everything around it.
Let’s talk about the people you’ll need. This will be the absolute barebones crew you need to assemble to ensure that the LLM you took is turned into a proper product. Without these Queens, the constant challenges will really rock you.
A. Assembling the Deployment & Operations Crew
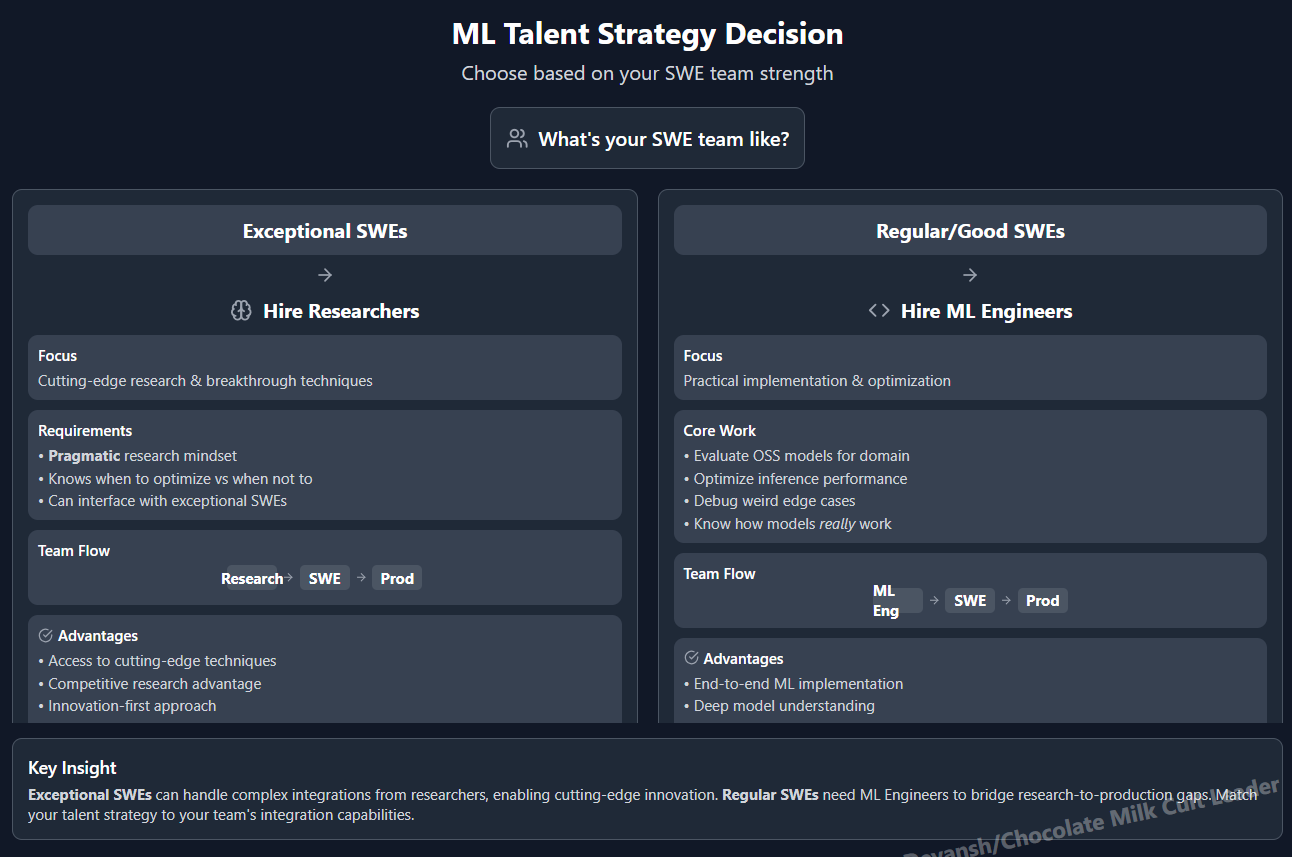
1. ML Engineers /Research Engineers for OSS Integration
You’ll need ML engineers to:
Evaluate which OSS models are good for your domain. LLM evals are extremely hard to get right (hence the rise of LLM eval startups like Braintrust and Haize Labs).
Optimize for inference performance (quantization, batching, distillation)
Debug weird edge cases no blog post ever warned you about
They need to know how the model really works. Because when something breaks, HuggingFace isn’t sending help.
If your SWEs are exceptional, you might hire some researchers instead of MLEngineers to focus more on the cutting edge and have them interface with your SWEs for integration. This requires strong pragmatic researchers that can figure when something should and should not be optimized.
2. MLOps Engineers to make your system scalable and secure
You want auto-scaling, model versioning, rollback triggers, real-time observability?
That’s not a side project. That’s a full-time engineer who knows the inference stack inside out — Triton, TGI, vLLM, Docker, K8s, GPU quotas, the works.
3. Software Integration Engineers
The OSS LLM doesn’t run in a vacuum. It needs to:
Serve responses through an API
Validate inputs, shape outputs
Mesh with your data pipeline, auth systems, UI layer, logging infra
This is where 60% of the real engineering effort goes — and where most teams discover the model they picked “because it worked in a Colab” was a mistake.
“Jupyter notebooks were heavily used in development to support high velocity, which we did not find surprising. However, we were surprised that although participants generally acknowledged worse code quality in notebooks, some participants preferred to use them in production to minimize the differences between their development and production environments. P6 mentioned that they could debug quickly when locally downloading, executing, and manipulating data from a production notebook run. P18 remarked on the modularization benefits of a migration from a single codebase of scripts to notebooks: We put each component of the pipeline in a notebook, which has made my life so much easier. Now [when debugging], I can run only one specific component if I want, not the entire pipeline… I don’t need to focus on all those other components, and this has also helped with iteration”
-When we covered the Biggest Challenges that teams Face in Machine Learning Engineering, we saw that mismtaches from Jupyter notebooks was one of the biggest sources of constant headaches. That’s why we need great SWEs.
4. Data Scientists — Evaluation & Monitoring
No, you don’t need them to fine-tune (yet). You need them to:
Run pre-deployment evals on task-specific data
Establish drift detection pipelines
Flag when your model starts hallucinating legal advice or turning racist on Tuesdays
They are your last line of defense between “working” and “oh god, it’s live and wrong.”
This can be done by your ML Crew, but then you’ll need more MLEs to handle the load. So you’re not really saving money by skippping them.
5. (Optional) Domain Experts
If you’re doing medical, legal, financial, or anything that gets you sued — yes, you need someone who actually knows the field to sanity check the outputs. Otherwise, enjoy your malpractice lawsuit. People try to use LLM as judges, and they’re very good for simpler evals. But in more complex domains, LLM evals and expert evals tend to diverge significantly (hence the adage- “It’s funny how GPT is an expert in everything except for your field of knowledge”). In this case, you need the expert to make sure you’re still focused on the right domain.
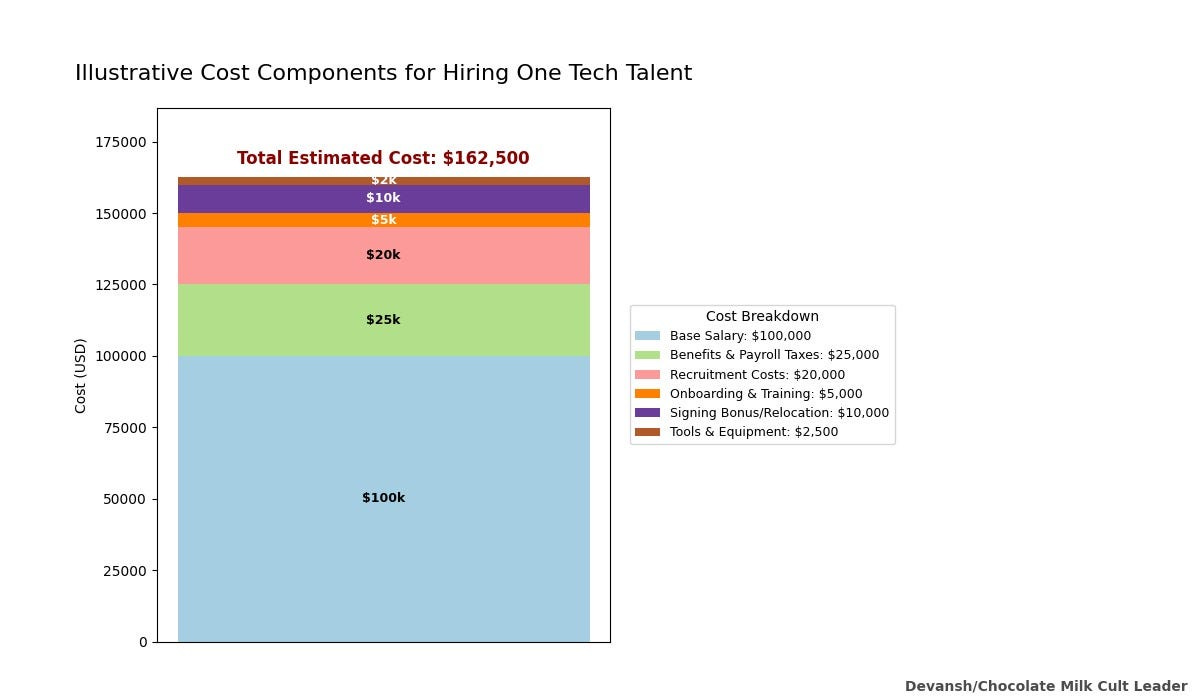
According to the 2024 Technical Skills Report, the average cost of hiring new tech talent is $23,450 per employee.
-Source. This is likely underrated when we consider how costly bad talent can be.
B. The True Economics of Talent
Let’s be real. These people don’t come cheap. And the better ones are already employed fixing someone else’s mess.
Salaries: $120K–$200K+ per head. That’s being conservative, especially in competitive tech hubs. So your estimated total Annual Burn: ~$610K–$710K before benefits and overhead.
Recruitment: OSS familiarity isn’t universal. If you’re using obscure models, good luck hiring anyone who’s touched them before.
Onboarding & Ramp-Up: Expect weeks — maybe months — before your team fully understands how to get performance from the model you picked.
Continuous Learning: OSS models evolve. Deployment tools change. If your team doesn’t stay current, you’ll fall behind — quietly, then catastrophically.
Possibly the most insidious human capital cost is the opportunity cost of misallocation. Every brilliant engineer you have wrestling with the idiosyncrasies of deploying someone else’s “free” model is an engineer not building unique, proprietary value for your company. They’re not creating your next market-defining product. They’re performing complex, often frustrating, systems integration and maintenance work that, in a proprietary model scenario, would largely be handled by the vendor. This is the silent killer, the strategic drain that doesn’t show up on an expense report until it’s far too late.
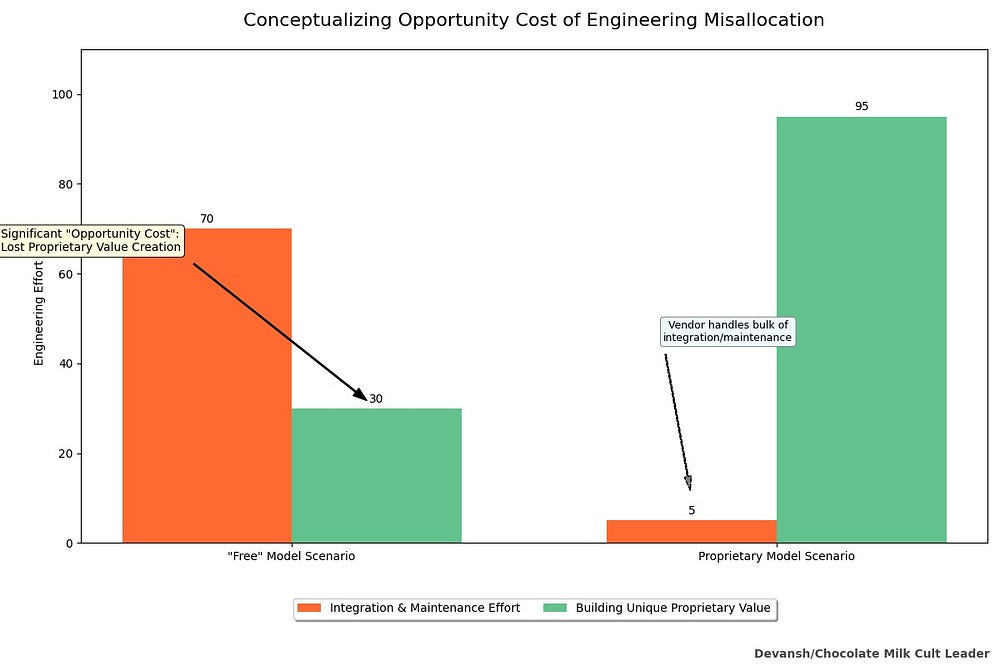
You’ve already spent upwards of half a million dollars on getting your talent working. You might think this is the biggest challenge and we’re in for smooth sailing after this, but Picture abhi baaki hai dost.
The cost curve is only beginning.
Better start logging everything. When you decide to end it all, it’ll help your loved ones figure out why.
Section 3: Infrastructure & Operational Bleed: Where “Free” Goes to Die
So you’ve hired the team. They’ve onboarded. You picked a model. Maybe even wrapped it in a nice API.
You’re feeling good.
As you will soon learn, Life isn’t a battle between joy and despair. It’s a slow bleed of disappointment, punctuated by bursts of accidental grace.

You’re now about to meet the real villain of open-source LLM deployment: infrastructure. If human capital is the brain, infrastructure is the perpetually famished, multi-headed hydra of your LLM operation. And each head demands its pound of flesh,
It doesn’t spike once. It bleeds you — quietly, persistently, month after month — until you’re staring at billing dashboards like they’re death sentences.
Let’s count the cuts.

A. Compute: The Inference Engine That Never Stops Eating
You’re not training a model. No one’s running 1,000-GPU jobs here. But inference? That’s the slow, grinding furnace you can never turn off.
1. Inference at Scale
Every token served = a slice of GPU time. And every millisecond of latency you shave = another engineering sprint or another compute bill.
Let’s say you’re serving a quantized 7B model. You’re running it across ~5 g5.xlarge instances just to hit tolerable latency for moderate user load. That’s ~$1.20/hour * 5 instances * 24 * 30 = $4,320/month — before traffic spikes, load testing, or redundancy.
That’s the low end.

Now imagine it’s a 13B model. Add context window expansion. Add high RPS from downstream services. Suddenly you’re looking at $10K–$40K/month for compute… and that’s before a single optimization error torches your week.
Forget to scale down your staging cluster? That’s a five-figure “oops.” Better hope you can “Tee-Hee” your heart out to CFO-senpai.
Choose the wrong model architecture for inference? Enjoy the latency tail eating your SLAs alive.
2. Serving Stack Hell
You’re not doing model.generate() in a notebook anymore.
You’re running:
vLLM or TGI for batch scheduling
Triton Inference Server for multi-model juggling
Tokenizer bottlenecks, I/O starvation, thread-pool deadlocks
Each of these has config files longer than your last “Babe I can explain” text and mistakes in those configs can quietly 2x your compute bill.


3. Quantization & Optimization Games
Your engineers will try to optimize inference:
FP16 → INT8 quantization
LoRA-based distilled variants
Compile optimizations with ONNX, TensorRT, etc.
Every optimization is a tradeoff:
Lower precision = better cost, worse performance. Although done right, this can be minimized.
Distilled models = smaller size, possibly dumber outputs
Compilation = faster inference, harder debugging
You won’t get it right on the first try. Or the second. Every failed experiment is a tax you pay in GPU hours and team time (the opportunity cost we mentioned earlier).

4. Cloud vs On-Prem: Choose Your Torture
Cloud:
Pros:
Easy to scale
No upfront capex
Bleeding-edge hardware
Cons:
Elastic spend becomes elastic panic
Spot instance interruption mid-request? Enjoy the outage.
GPU shortages during peak? Welcome to the queue.
Forgot to deallocate staging? The next AWS yacht party was funded by you.
On-Prem-
Pros:
Predictable cost curves after six months of hell
Theoretically secure, until your HR clicks on the phishing email, completely bypassing your security.
Massive Aura Farming potential (means a lot more than you’d think).
Cons:
Setup hell.
Driver hell.
Firmware hell.
Cooling hell.
“Why does this server keep rebooting randomly” hell.
Oh — and no one on your team actually knows how to maintain bare metal anymore.
Pro tip: If your startup’s power bill is higher than your funding round, you may have gone too far. Subscribe for more such revolutionary insights.

B. Storage: Your Quiet, Growing Problem
1. Model Artifacts
You’ll store:
Base model weights
Quantized versions
Experimental checkpoints
Different variants for A/B
It adds up. Not just in GB, but in headaches.
Miss one version tag? Roll back the wrong checkpoint? That’s a prod outage hidden in a .tar.gz file.
Meta did you a massive favor and released their logs for training their LLMs on Githubs. Check it out. You’re gonna learn very quickly why Zucky Chan had a midlife crisis strong enough to give him a complete makeover.
2. Evaluation & Monitoring Data
All your evals, benchmarks, prompt traces, output samples… versioned, tagged, logged, archived.
Your observability stack becomes a forensic archive. And it grows forever.
3. Logs, Logs, Logs
Inference logs. API logs. Error logs. Security logs.
You’ll be swimming in logs. Which FYI tends to cause it’s own kind of problem, such as massive cognitive fatigue for the people you have monitoring them.
You’ll need them — until you don’t, and your storage bill spikes so high you start deleting blindly.
More teams that you think teams don’t realize how much it costs to understand why their model broke — until they can’t afford the logs that would’ve told them.
4. Backup & Recovery
You will mess something up. You will restore from backup.
Unless you forgot to test your backup system. In which case, you will cry. More than Inter Fans are crying right now.
C. Networking: The Hidden Tax No One Told You About
Data Egress & Ingress
You know what’s funny?
Cloud providers are giving you free compute credits… and then charging $0.09/GB to use your own data.
Internal service calls?
Multi-region deployments?
Frontend->backend->LLM hops?
All of it taxed. Quietly. Constantly.
Some startups spend more on egress fees than compute. And they don’t notice until the quarterly burn review hits. I’m not naming names, but you know who you are.
2. Internal Bandwidth
Your model isn’t alone. It talks to microservices. DBs. Auth systems.
Every internal call carries latency, cost, and potential failure points. You will end up building a mini-networking team just to keep this duct tape from catching fire.
D. Energy Consumption: If You Went On-Prem, This Is Your Life Now
Each A100 can pull up to 300W
Full racks can exceed 3–5kW
That’s just power
Add cooling
Add backup power redundancy
Add your internal ops team asking why the breaker flipped again
If you’re not logging power usage, you’re not serious about cost control. If you’re still trying to argue on-prem was “cheaper,” send your CFO a handwritten apology.
Infrastructure is not a one-time cost.
It’s a living creature.
It grows. It mutates. And if you don’t feed it, monitor it, and optimize it —
it eats your margin and starts chewing through your roadmap.
And this is before you touch maintenance.
Strap in. That’s next.
Section 4: The Long March of Maintenance & Support
There’s something uniquely beautiful about the maintenance phase. It doesn’t announce itself. There’s no big failure, no sexy postmortem. Just a slow seep of confusion. A rising count of support tickets. A latency spike at 2 AM that no one can explain. Parts of the stack remain untouched because “they’re fragile,” and the only person who understands how the model interacts with the API has left for a crypto gig in Lisbon. The decay is silent. But constant.

Worse, no one budgets for it. How could you? Leadership approved the OSS model because it was “free.” Maybe they understood compute costs. Maybe even storage. But no one priced in what it takes to maintain belief in a system that evolves faster than your team can learn it. You’re not supporting software. You’re suppressing entropy. And you’re doing it alone.
There’s no vendor. No SLA. If the tokenizer breaks, you file a GitHub issue and pray some pseudonymous maintainer feels generous. Meanwhile, your engineers are stuck in a loop of reactive duct-taping:
Hotfix one regression, trigger three new ones
Patch the inference server, discover a latent bug in the tokenizer
Update your logging system, break your latency monitor
And the worst part? It doesn’t explode. It erodes. It drags. It slows everything down without ever formally failing.
You don’t see the cost in dollars. You see it in:
Roadmaps that slip
Burned-out engineers who want off the project
Failed hires who bounce after realizing what they’ve inherited
The real failure isn’t the model.
It’s what the model quietly does to everything around it. This is where you Stockholm syndrome yourself to remember the “good ol-days you spent looking for the right models”.
You didn’t just spend money. You didn’t just lose time.
You made bets. On models. On architectures. On teams.
And now it’s time to talk about what happens when those bets go wrong.

Section 5. Strategic Miscalculations & Second-Order Effects:
By now, you’ve seen the bills. You’ve felt the rot. You’ve absorbed the daily pain of keeping someone else’s experiment alive in your infrastructure. But that’s just the visible cost. The deeper wounds — the ones that don’t show up on a cloud invoice — are strategic. They don’t just slow you down. They kill the company quietly.
These are the second-order effects. You don’t just lose money. You lose direction, morale, reputation, and eventually, control. All from the illusion that “open” meant “simple.”
A. The Career Risk Premium: Betting on OSS and Paying in Reputation
Proprietary LLMs come with PR protection.
If GPT-4 fails, the problem wasn’t you — it was OpenAI. The market shrugs.
But OSS? That’s personal.
You chose the model.
You picked the architecture.
YOU argued it was “just as good” and “way cheaper.”
Then it underperforms. Or breaks something. Or gets exploited.
Now it’s your face in the slide deck when management asks: “Why didn’t we just use Anthropic?”
This is the career risk premium no one tells you about.
Every minor outage becomes a referendum on your decision.
Every new bug becomes evidence you chose wrong.
The result? You spend more time defending your decision than building on it. And eventually, no one wants to be the one who champions OSS again.
B. Internal Political Overhead: Freedom Without Strategy Is a Knife Fight
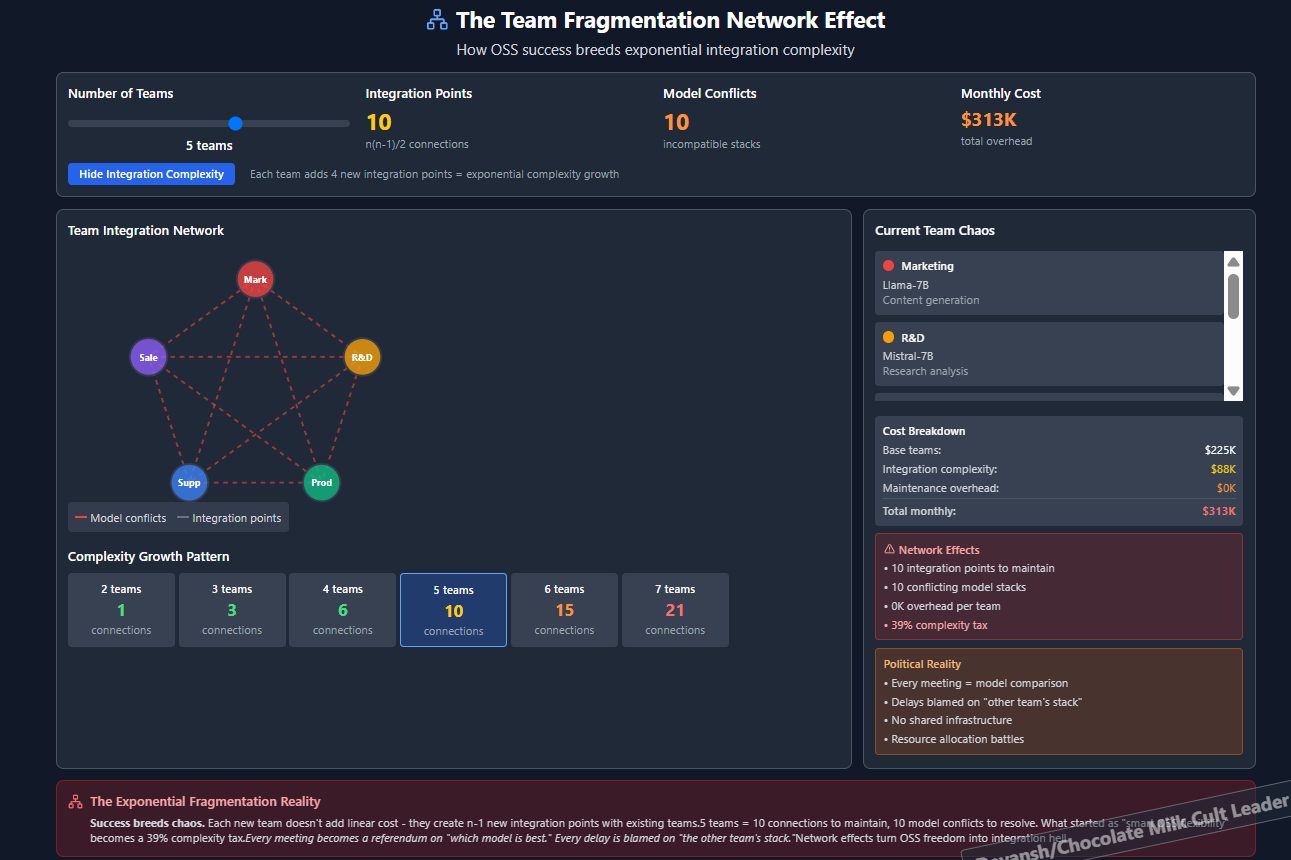
OSS promises flexibility. What it delivers, without discipline, is chaos.
Once you show that OSS LLMs can work very well in your vertical, everyone wants in on the style points of having their own LLMs. Why wouldn’t they- it means more budgets, a lower likelihood of getting fired due to “major project in progress”, and bragging rights (don’t underestimate what people will go through for them bragging rights).
All of a sudden, you get:
Marketing running one model
R&D playing with 3 more
Product trying to integrate a fifth
Engineering stuck supporting all of it
There’s no alignment. No reuse. No shared infra. Just duplicated cost, conflicting pipelines, and a political minefield where every team pushes the agenda that their model is “the one.”
What started as a smart OSS move becomes a resource black hole.
Every meeting becomes a referendum on “which model is best.”
Every delay is blamed on “the other team’s stack.”
Isn’t working life simply wonderful?
C. Evaluation Hell: Infinite Models, No Confidence
The OSS LLM space moves faster than your hiring pipeline. Every week, a new model drops. Better scores. Bigger context. Some mysterious new training trick.
So what do you do? You benchmark. Again. And again. And again.
Each cycle eats:
Engineering hours
GPU costs
Team focus
Product momentum
And half the time, the gains aren’t real. The evals are cherry-picked. The benchmarks are gamed (y’all hearing the murmurs that Qwen might have trained on some testing data now?). You waste weeks proving a new model is only marginally better, then do it all over again when the next one drops.
E. OSS Lock-In: The Vendor Is Gone, But You’re Still Trapped
You thought you were avoiding lock-in.
You avoided licenses. You avoided tokens. But you didn’t avoid dependence.
You are now locked into:
A serving stack no one else uses
A tokenizer with zero documentation
A model family your team had to learn from Reddit threads
Data pipelines, pre-processing, prompt formats, and finetune scripts built around quirks you didn’t design — but now can’t leave
Your team doesn’t want to switch. Not because there’s no better option, but because switching is suicide. You’ve built too much. You’re too deep.
This is the OSS trap no one talks about:Freedom that decays into inertia.
And inertia that kills adaptability.
Strategic failure doesn’t start with the wrong model. It starts with the wrong assumptions.
In reality:
OSS requires brutal governance
It demands architectural foresight
And it punishes naivety more harshly than any license fee ever could
“Free” was just the bait.
This — this is the price.
Speaking of price, let’s end with some Cost Estimation Scenarios.
No more theory. Just numbers.
Section 6: Estimating costs of OSS LLM Deployment Scenarios
We’ve dissected the anatomy of costs. Now, let’s get us some numbers. The following scenarios aim to provide a tangible, sobering framework for estimating the Total Cost of Ownership (TCO) when deploying open-source LLMs. I’ve kept it on the lower end to steelman the argument.
SCENARIO 1: Internal Tooling — Low-Volume, Internal-Only Use Case
Use Case: Chatbot for internal documentation search, knowledge base Q&A, used by ~100–200 employees.
Model: 7B-13B parameters (quantized, e.g., Mistral 7B or a smaller LLaMA variant).
Inference Load: ~10,000–20,000 queries/day.
Latency Tolerance: Moderate (e.g., ≤1–2 seconds per query).
Deployment: Cloud (e.g., AWS g5 instances), minimal redundancy.
Serving Stack: vLLM or TGI, basic cloud-native monitoring.
Estimated Monthly Costs Breakdown (Conservative but Realistic):
Compute (Inference): Running one to two mid-range GPU instances (e.g., g5.xlarge/2xlarge or equivalent) 24/7. Cost: $1,500 — $3,000.
Storage: Model artifacts, logs, evaluation datasets. Cost: $150 — $300 (will grow).
Networking: Data egress/ingress, primarily internal. Cost: $75 — $150.
Tools & Services: Basic tier logging/monitoring. Cost: $250 — $400.
Talent (Fractional Allocation — assuming skilled personnel):
Software Engineer (0.33 FTE for integration, API maintenance): Approx. $5,000 — $7,000.
MLOps/SRE (0.20 FTE for deployment, upkeep): Approx. $3,500 — $5,000.
Total Estimated Monthly TCO: Approximately $10,475 — $15,850 per month.
Annualized: Roughly $125,000 — $190,000+.
Key Risks/Hidden Costs for This Scenario: Team burnout from individuals wearing multiple hats, underestimation of integration effort, rapid scaling outstripping initial infrastructure, and security oversight due to lean staffing. Many teams lack effective profiles for “fractional” usage and often end up hiring full-time employees for this purpose, thereby incurring higher costs.
SCENARIO 2: Customer-Facing Feature — Moderate Scale, Performance Sensitive
Use Case: LLM-based writing assistant, advanced search, or summarization embedded in a SaaS product.
Model: 13B-30B parameters (FP16 or aggressively quantized, e.g., LLaMA-2 13B/30B or Mixtral 8x7B sparse variant).
Inference Load: ~1M — 3M requests/month, with daily peaks.
Latency Tolerance: Strict (e.g., ≤300–500ms P95).
Deployment: Cloud with autoscaling (e.g., 4–10 GPU instances), high availability.
Serving Stack: Optimized TGI or vLLM with autoscaling, Prometheus/Grafana, managed Kubernetes.
Estimated Monthly Costs Breakdown (Conservative but Realistic):
Compute (Inference): Autoscaled GPU instances (e.g., 4–10 g5.2xlarge/4xlarge or A10G equivalents). Cost: $7,000 — $18,000 (highly dependent on utilization, instance type, and optimization).
Storage: Multiple model variants, verbose logs, backups. Cost: $500 — $1,000.
Networking: Significant external API traffic and data egress. Cost: $1,000 — $2,500.
Tools & Services: Mid-tier logging/monitoring, managed Kubernetes service. Cost: $800 — $1,800.
Talent (Dedicated Roles):
Senior Software Engineer (1 FTE for integration, performance): Approx. $14,000 — $18,000.
MLOps Engineer (0.75 FTE for deployment, scaling, CI/CD): Approx. $11,000 — $15,000.
Data Scientist (0.33 FTE for evaluation, drift monitoring): Approx. $5,000 — $7,000.
Evaluation Overhead (Recurring): Compute & labor for model re-evaluation/testing. Cost: $2,500 — $5,000.
Total Estimated Monthly TCO: Approximately $41,800 — $68,300+ per month.
Annualized: Roughly $500,000 — $820,000+.
Key Risks/Hidden Costs for This Scenario: Dependency hell from a more complex stack, security vulnerabilities at scale, cost of retraining/replacing the model as OSS landscape evolves, internal political overhead for resource allocation.
SCENARIO 3: Core Product Engine — High-Scale, Mission-Critical
Use Case: LLM is central to product value — AI legal copilot, advanced code generation, financial modeling. Such as Iqidis AI, for lawyers, which you can use for free!!.
Model: 30B-70B+ parameters, or ensemble of multiple specialized models (e.g., fine-tuned LLaMA 70B, Mixtral variants).
Inference Load: 10M — 50M+ queries/month, demanding global availability and high concurrency.
Latency Tolerance: Very Strict (e.g., ≤150–250ms P99).
Deployment: Cloud with multi-region redundancy, advanced autoscaling, potentially hybrid on-prem components.
Serving Stack: Highly optimized vLLM or Triton Inference Server, advanced queueing, A/B testing, comprehensive observability & security.
Estimated Monthly Costs Breakdown:
Compute (Inference): 20–70+ high-end GPU instances (e.g., A100s, H100s on reserved/long-term contracts) globally distributed. Cost: $100,000 — $300,000+ (H100s are pricier; A100s slightly less but may need more for same throughput).
Dedicated Fine-Tuning/Experimentation Cluster: Several high-end GPU instances. Cost: $15,000 — $45,000.
Storage: Extensive logs, model zoo, data lake for fine-tuning. Cost: $3,000 — $12,000.
Networking: Global egress, CDNs, private links. Cost: $10,000 — $30,000.
Tools & Services: Comprehensive observability stack, advanced security tooling. Cost: $15,000 — $40,000.
Talent (Dedicated Senior Team):
Lead/Principal ML Engineer (1 FTE): Approx. $20,000 — $30,000.
Senior ML Engineers (3–4 FTE): Approx. $60,000 — $90,000.
Senior MLOps/SRE (2–3 FTE): Approx. $40,000 — $70,000.
Senior Software Engineers (4–5 FTE): Approx. $65,000 — $100,000.
Principal Data Scientist (1 FTE): Approx. $18,000 — $25,000.
Group Product Manager (AI focused): Approx. $18,000 — $25,000.
(Total Monthly Talent — Direct Salary Est.): ~$221,000 — $340,000. Fully burdened (x1.4): ~$310,000 — $476,000.
Model Evaluation / R&D (Continuous): Cost: $20,000 — $50,000.
Security & Compliance (Ongoing Audits, Certs): Cost: $8,000 — $20,000.
Total Estimated Monthly TCO: Approximately $500,000 — $1,000,000+ per month.
Annualized: Roughly $6M — $12M+, and can easily exceed this for very large, complex, global deployments.
Key Risks / Hidden Costs: At this scale, even small inefficiencies — poor GPU utilization, misconfigured autoscaling, or sloppy data handling — can cost six figures monthly. SLA breaches carry financial penalties, client churn, and reputational damage. Multi-region resilience adds further complexity and risk.
Talent fragility is critical: losing key MLEs or MLOps engineers can paralyze operations. Replacements are rare, expensive, and slow to ramp.
Security becomes existential: a major breach at this level doesn’t just hurt — it can end the business. Enterprise-grade security is a non-optional, ongoing investment.
Architectural rigidity sets in fast: pivoting to new model architectures or serving stacks becomes slow, expensive, and politically risky. Despite using OSS, you may be more locked in than with a vendor.
Compliance overhead is constant: GDPR, HIPAA, the AI Act — global data regulations demand continuous monitoring, engineering effort, and audit readiness across every subsystem.
SCENARIO 4: The R&D “Model Zoo” & Evaluation Pipeline
Use Case: Organization maintains an active process of evaluating, benchmarking, and potentially fine-tuning new OSS LLMs.
Benchmarking Volume: 5–15+ new models/variants tested per month.
Evaluation Compute: 10–100 GPU hours per model.
Personnel: 1–2 FTE Data Scientists / ML Researchers, 0.5 FTE MLOps/SWE tooling.
Estimated Monthly Costs Breakdown:
Compute (Evaluation & Light FT): 200–1000 GPU hours (mixed types). Cost: $3,000 — $15,000 (reflecting better spot instance usage or access to slightly older but still capable GPUs for some tasks).
Storage: Model checkpoints, datasets, logs. Cost: $500 — $1,200.
Tools & Services: Experiment tracking, MLOps platforms. Cost: $300 — $800.
Talent:
Data Scientist/Researcher (1.5 FTE): Approx. $20,000 — $30,000.
MLOps/SWE Support (0.5 FTE): Approx. $7,500 — $11,000.
Total Estimated Monthly TCO: Approximately $31,300 — $58,000+ per month.
Annualized: Roughly $375,000 — $700,000+ just for R&D and evaluation.

Key Risks / Hidden Costs : A major hidden cost is evaluation paralysis — teams trapped in endless benchmarking cycles without clear criteria or production goals. This leads to heavy spend with little strategic output. Inconsistent methodologies and non-standardized metrics further increase the risk of poor model selection based on misleading or incomparable results.
Tooling sprawl is another creeping threat. Each new model often requires bespoke setups, leading to fragmented environments, duplicated infra, and growing maintenance overhead. The sunk cost fallacy compounds waste — teams continue investing in marginal models simply because time has already been spent.
Knowledge loss also hits hard. Without rigorous documentation, insights are siloed or forgotten, forcing teams to re-learn past lessons and duplicating evaluation work. This creates a silent tax on institutional efficiency.
Finally, R&D effort can drift into strategic distraction — evaluating external models at the expense of developing proprietary capabilities or solving business-critical problems that general-purpose LLMs will never fully address.
Additional One-Time or Periodic Major Costs (Common Across Scenarios):
These significant, less frequent expenditures must also be factored in:
Initial Major Fine-Tuning (e.g., LoRA/QLoRA): Costs range from $7,000 to $100,000+ per project, depending on data, model, epochs, and hardware.
Legal Review & OSS License Compliance: Initial review: $7,000 — $30,000+, with ongoing costs for complex uses.
Security Audits (External): For production systems: $15,000 — $70,000+ per audit.
Backup & Disaster Recovery System Setup: Initial: $4,000 — $20,000, plus recurring costs.
Initial Team Ramp-Up & Specialized Training: For teams new to specific OSS stacks: $15,000 — $75,000.
Major Model Migration / Replacement Project: Engineering effort: $30,000 — $250,000+.
Conclusion
Open-source LLMs aren’t free — they’re deferred-cost systems disguised as freedom. You save on licenses, and pay in engineering time, architectural rigidity, and operational complexity.
The download is free. The deployment is a commitment.
Know what you’re signing up for — before it signs you up for a multi-million dollar maintenance contract with your own team.
Thank you for being here, and I hope you have a wonderful day.
I’m still an OS guy, I promise-
Dev <3
If you liked this article and wish to share it, please refer to the following guidelines.
That is it for this piece. I appreciate your time. As always, if you’re interested in working with me or checking out my other work, my links will be at the end of this email/post. And if you found value in this write-up, I would appreciate you sharing it with more people. It is word-of-mouth referrals like yours that help me grow. The best way to share testimonials is to share articles and tag me in your post so I can see/share it.

Reach out to me
Use the links below to check out my other content, learn more about tutoring, reach out to me about projects, or just to say hi.
Small Snippets about Tech, AI and Machine Learning over here
AI Newsletter- https://artificialintelligencemadesimple.substack.com/
My grandma’s favorite Tech Newsletter- https://codinginterviewsmadesimple.substack.com/
My (imaginary) sister’s favorite MLOps Podcast-
Check out my other articles on Medium. : https://rb.gy/zn1aiu
My YouTube: https://rb.gy/88iwdd
Reach out to me on LinkedIn. Let’s connect: https://rb.gy/m5ok2y
My Instagram: https://rb.gy/gmvuy9
My Twitter: https://twitter.com/Machine01776819
“Open-source LLMs are not free — they just move the bill from licensing to engineering, infrastructure, maintenance, and strategic risk”
Isnt that the case with every OSS?
Databases, message brokers, data processing frameworks etc.
Isnt what you are talking about just self hosting vs managed infra?
No free lunch, and great analysis on the hidden costs.