


What are the biggest challenges in Machine Learning Engineering [Breakdowns]
And how we can fix them

Hey, it’s Devansh 👋👋
In my series Breakdowns, I go through complicated literature on Machine Learning to extract the most valuable insights. Expect concise, jargon-free, but still useful analysis aimed at helping you understand the intricacies of Cutting-Edge AI Research and the applications of Deep Learning at the highest level.
I put a lot of effort into creating work that is informative, useful, and independent from undue influence. If you’d like to support my writing, please consider becoming a paid subscriber to this newsletter. Doing so helps me put more effort into writing/research, reach more people, and supports my crippling chocolate milk addiction. Help me democratize the most important ideas in AI Research and Engineering to over 100K readers weekly.
PS- We follow a “pay what you can” model, which allows you to support within your means. Check out this post for more details and to find a plan that works for you.
Executive Highlights (tl;dr of the article)
Primary Research Referenced for this article: “Operationalizing Machine Learning: An Interview Study”.
This is a follow-up article to our analysis on “What do organizations need to be successful at Machine Learning?”, which covers important background information such as:
The 4 major tasks that an ML Engineer works on.

What value does each of the above tasks add to the ML workflow?
What are the 3Vs that determine ML Success?
How to handle the experimental nature of ML Engineering?
How to combine product-centric metrics with traditional ML metrics to pick the correct model.
How can you keep your models performing optimally after you’ve put them out to production?
Understanding the above gives us richer insight into what drives success in ML Engineering. Once we have that, we can then understand how to address the following challenges that are currently terrorizing ML Engineers everywhere-
Development-Production Mismatch: There are discrepancies between development and production environments. This includes data leakage; differing philosophies on Jupyter Notebook usage; and non-standardized code quality- all of which cause unanticipated bugs in production. Bridging this gap with tools that provide similar environments while supporting varying iteration speeds is crucial. I also HIGHLY recommend leveraging asynchronous documentation/style guide checks + team culture to standardize many of these practices so that your engineers unconsciously follow the SOPs that you have established. As a wise man (me) once said- Subconscious brainwashing often succeeds where education fails. More on this to come in future articles.
Handling Data Errors: ML engineers face challenges in handling a spectrum of data errors, such as schema violations, missing values, and data drift. The difficulty lies in determining appropriate responses for each type of error and mitigating alert fatigue caused by false positives. These can be addressed by developing/buying tools for real-time data quality monitoring and automatic tuning of alerting criteria.
Taming the Long Tail of ML Bugs: Debugging ML pipelines presents unique challenges due to the unpredictable and often bespoke nature of bugs. While symptoms may be similar, pinpointing the root cause can be time-consuming and lead to a sense of “debugging trauma”. Categorizing bugs and developing tools that provide insights into performance drops and their root causes are potential solutions. This is why I obsessively emphasize better transparency and monitoring frameworks- they can help you avoid huge recurring mistakes.
Lengthy Multi-Stage Deployments: The iterative and unpredictable nature of ML experiments + the multi-stage deployment processes can lead to extended timelines for validating and launching new models or features. This often results in dropped ideas due to shifting priorities or evolving user behavior. Streamlining deployments and tools that predict end-to-end gains could minimize wasted effort. However, your best bet is to embrace the maxim of “less is more”. Look for ways to (in)validate ideas as quickly as possible, as this will save you a lot of time and energy. Remember, you win every battle you don’t fight.
Observed Anti-Patterns: Several anti-patterns hinder MLOps progress, including the mismatch between industry needs and classroom education, the urge to keep GPUs constantly running experiments without strategic focus, the tendency to retrofit explanations after observing results, and undocumented knowledge about specific pipelines. Addressing these anti-patterns requires improved educational resources, automated documentation tools, and a shift towards prioritizing quality over quantity in experimentation.
The authors end on a discussion of the MLOps tool landscape. The landscape can be organized into four layers: the Run Layer for managing executions; the Pipeline Layer for specifying dependencies and computations; the Component Layer for individual units of computation; and the Infrastructure Layer for underlying resources.

If you’re an MLOps tool builder- understand these layers and look for ways to significantly boost the 3 Vs in them. The two main points from that section are-
Engineers like tools that enhance their experience. We’ve discussed this in-depth in our sister publication, Tech Made Simple. Improving UX, especially for somewhat mature tools/apps, tends to have higher ROI than improving engineering (it’s expensive to make the train go faster, but it’s easy to put WiFi on a train to make the journey bearable).
The frequency of changes decreases as we go deeper. The run layer has lots of changes, the infra layer tends to have very few. Many teams tend to make infra decisions through a very short-term lens(“AWS was giving us a nice discount” or “the group we hired only knew Azure”) but this can lead to huge problems later. It’s worthwhile to spend some time thinking deeply about infra trade-offs before diving into decisions. To quote the authors- “Infrastructure changed far less frequently than other layers in the stack, but each change was more laborious and prone to wide-ranging consequences”. As the saying goes, “Spend 10 hours sharpening your axe and 2 cutting the tree.”
The rest of this piece will go into the challenges in the MLOps/Engineering space in more detail and discuss some possible ways to resolve them. Once again, I invite you to share your thoughts on these topics. If nothing else, hearing about your experiences in AI/Tech Leadership allows me to pretend to know more than I do. My knowledge is 80% a mish-mash of what others have told me, 15% my own experiences, and 5% my intuition (keep this a secret b/w us though).
How ML Teams Get Catfished
Is the most impressive thing about most of your Tinder dates their Photoshop skills? If so, consider joining an ML team and getting catfished professionally. Differences b/w training and production environments often lead to inflated performance metrics and a passionate tango with failure when your system hits production. Let’s talk about some of the most common reasons why this happens-
Data Leakage
Data Leakage happens when your model gets access to information during training that it wouldn’t have in the real world.

This can happen in various ways:
Target Leakage: Accidentally including features in your training data that are directly related to the target variable, essentially giving away the answer.
Train-Test Contamination: Not properly separating your training and testing data, leading to overfitting and an inaccurate picture of model performance. This problem
Temporal Leakage: Information from the future leaks back in time to training data, giving unrealistic ‘hints’. This happens when we randomly split temporal data, giving your training data hints about the future that it would not (this video is a good intro to the idea).
Inappropriate Data Pre-Processing: Steps like normalization, scaling, or imputation are done across the entire dataset before splitting. Similar to temporal leakage, this gives your training data insight into the all the values. For eg, imagine calculating the average income across all customers and then splitting it to predict loan defaults. The training set ‘knows’ the overall average, which isn’t realistic in practice.
External Validation with Leaked Features: When finally testing on a truly held-out set, the model still relies on features that wouldn’t realistically be available when making actual predictions.
We fix Data Leakage by putting a lot of effort into data handling (good AI Security is mostly fixed through good data validation + software security practices- and that is a hill I will die on). Here are some specific techniques-
Thorough Data Cleaning and Validation: Scrutinize your data for inconsistencies, missing values, and potential leakage points. Implement data quality checks and validation procedures to ensure your data is representative of the real world.
Feature Engineering with Care: Pay attention to the features you create and their potential for leakage. Avoid features that directly reveal the target variable or are overly dependent on the training data distribution.
Rigorous Code Reviews: Have multiple pairs of eyes review your code to identify potential data leakage pathways, especially in complex preprocessing or feature engineering steps. Having outsiders audit your practices can be a great addition here. Below is a description of Gemba Walks, a technique that Fidel Rodriguez, director of SaaS Analytics at LinkedIn(and former head of analytics at Google Ads) relies on extensively:
Gemba Walks- This was a new one for me, but when Fidel described it, I found it brilliant. Imagine your team has built a feature. Before shipping it out, have a complete outsider ask you questions about it. They can ask you whatever they want. This will help you see the feature as an outsider would, which can be crucial in identifying improvements/hidden flaws.
These processes reduce your Velocity. There is a tension b/w velocity and security present in ML Engineering. I don’t have enough experience leading AI Projects to tell you how to resolve that or to teach you how to identify where your team should fall on that spectrum. But we do have a lot of senior leaders in our adorable little chocolate milk cult, and I’m hoping some of you can share your insights here. For now, let’s move on to the next way there might be a mismatch b/w your dev and prod environments.
Jupyter Notebooks
Jupyter Notebooks are the go-to tool for data exploration and experimentation. Their interactive nature and flexibility make them ideal for rapid prototyping and trying out new ideas. However, their free-form structure can also lead to messy code, lack of reproducibility, and difficulty in transitioning to production.
Notebooks allow you to trade simplicity + velocity for quality. Depending on your priorities, this means you are either going to be pro or against using Notebooks in production. The following passage is very insightful look about why some people utilize NBs in production-
“Jupyter notebooks were heavily used in development to support high velocity, which we did not find surprising. However, we were surprised that although participants generally acknowledged worse code quality in notebooks, some participants preferred to use them in production to minimize the differences between their development and production environments. P6 mentioned that they could debug quickly when locally downloading, executing, and manipulating data from a production notebook run. P18 remarked on the modularization benefits of a migration from a single codebase of scripts to notebooks: We put each component of the pipeline in a notebook, which has made my life so much easier. Now [when debugging], I can run only one specific component if I want, not the entire pipeline… I don’t need to focus on all those other components, and this has also helped with iteration”
I’m not one of these people, but given that we are in the Kali Yug, one expects such degeneracy. The following quote from the paper aligns closer to my experience with Notebooks in production-
“P10 recounted a shift at their company to move any work they wanted to reproduce or deploy out of notebooks: here were all sorts of manual issues. Someone would you know, run something with the wrong sort of inputs from the notebook, and I’m [debugging] for like a day and a half. Then [I’d] figure out this was all garbage. Eight months ago, we [realized] this was not working. We need[ed] to put in the engineering effort to create [non-notebook] pipelines”
Why do these differences arise? The paper raises a brilliant point. Essentially the tension b/w security and speed shows up once again-
The anecdotes on notebooks identified conflicts between competing priorities: 1) Notebooks support high velocity and therefore need to be in development environments, (2) Similar development and production environments prevents new bugs from being introduced, and (3) It’s easy to make mistakes with notebooks in production, e.g., running with the wrong inputs; copy-pasting instead of reusing code. Each organization had different rankings of these priorities, ultimately indicating whether or not they used notebooks in production.
The paper also touches on how non-standardized quality requirements cause a mismatch between dev and prod. We will not be touching on that for two reasons. Firstly, I didn’t think the publication had anything profound to say about this topic. Secondly, to say anything intelligent about this topic (especially in a more general sense) requires experience, which I lack. For now, I’ll stick to the generic, “Clear explicit communication matters, and companies should not be shy about investing into documentation, style guides, and knowledge-sharing mechanisms.” Shoot me a message 2–3 decades from now, and I might have something valuable to add to this. In the meantime- you might want to reach out Dr. Christopher Walton, a senior AI Leader from Amazon. He had some amazing insights on managing AI teams over in his guest post here.
With that covered, let’s move on the next set of challenges- the infinite variety of errors in ML Projects.
✨✨The Fabulous Spectrum of Data Errors ✨✨
Hard Errors
These are the easiest to identify. Hard errors often lead to immediate and noticeable problems, causing models to crash or produce nonsensical results. Some ways to detect hard errors include-
Schema Validation: Define a schema that specifies the expected data types, formats, and ranges for each field. Validate incoming data against the schema to catch any violations.
Data Profiling: Analyze your data to identify missing values, outliers, and other anomalies that may indicate hard errors.
Rule-Based Checks: Implement rules to flag specific types of errors, such as checking for negative values in age fields or ensuring categorical variables have valid categories.
With LLMs, there is always a temptation to fine-tune your LLM with lots examples of acceptable and unacceptable inputs and let them act as data filtering. When it comes to handling hard errors, I would suggest not doing that. It might require more work- but letting traditional AI handle rule-based checks is cheaper, more accurate, and will fail predictably (which is a huge advantage). Even if your errors are only partially hard- using basic checks can supplement your LLMs/Deep Learning works very well. Deepmind’s AlphaGeometry already showed us the power of blending the two-
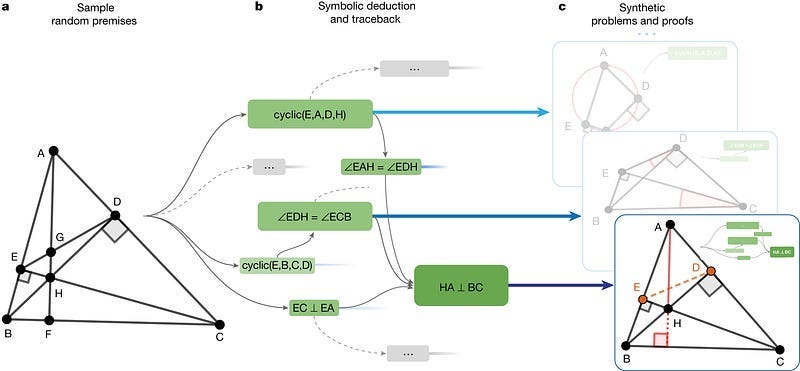
Soft Errors
Soft errors are more subtle and may not immediately cause model failures. They represent deviations from the expected data distribution or quality standards that can still impact model performance and lead to biased or inaccurate predictions. Examples include:
Outliers: Extreme values that deviate significantly from the rest of the data.
Data Inconsistencies: Minor errors or inconsistencies in the data, such as typos or formatting issues.
Feature Distribution Shifts: Changes in the distribution of individual features over time.
Detecting Soft Errors:
Statistical Analysis: Analyze the distribution of your data and features to identify outliers, skewness, and other anomalies.
Data Quality Metrics: Track metrics like completeness, consistency, and accuracy to assess the overall quality of your data.
Machine Learning Techniques: Train models to detect anomalies or deviations from expected patterns in the data. We’ve covered possible solutions in a few different articles and I will likely put everything together in one guide at some time.
Data Drift:
Data drift refers to changes in the underlying data distribution over time. This can happen gradually or abruptly and causes your model’s performance to degrade as it’s no longer optimized for the current data distribution.

There are several ways of Detecting Drift:
Monitoring Statistical Properties: Track changes in the mean, standard deviation, and other statistical properties of your data and features over time.
Distribution Comparison Methods: Use techniques like Kullback-Leibler (KL) divergence or Jensen-Shannon divergence to compare the distribution of current data to historical data or a reference distribution.
Machine Learning Models: Train models to detect changes or anomalies in the data distribution, signaling potential drift.
It’s important to remember that there’s a tradeoff b/w sensitivity and robustness to shift. That’s unavoidable-
P8 described how, in their NLP models, the vocabulary of frequently-occurring words changed over time, forcing them to update their preprocessor functions regularly. Our takeaway is that any function that summarizes data — be it cleaning tools, preprocessors, features, or models — needs to be refit regularly
B/c data is such an important of our lives- issues with Data don’t just end here. Instead, the technical issues of Data lead to another problem for MLEs. Let’s talk about that next-
Alert Fatigue: Separating Signal from Noise
A common pitfall in data quality monitoring is alert fatigue. When monitoring systems are too sensitive or generate too many alerts, engineers become overwhelmed and desensitized and we risk missing critical issues.
The pain point is dealing with that alert fatigue and the domain expertise necessary to know what to act on during on-call. New members freak out in the first [on call], so [for every rotation,] we have two members. One member is a shadow, and they ask a lot of questions.
Overtly sensitive flagging systems cause alert fatigue. Thus the solutions to alert fatigue involve reducing the cognitive load on engineers by only pinging them the number of times they get flagged-
Focus on Actionable Alerts: Prioritize alerts that indicate real problems requiring immediate attention. Filter out noise and low-priority alerts (write them to a log).
Smart Alerting Systems: Use machine learning or statistical techniques to identify the patterns in alerts and distinguish true issues from false positives (this is a general motif in this article).
Alert Aggregation and Correlation: Group related alerts together to provide a more comprehensive view of potential problems and avoid overwhelming engineers with individual notifications.
Alert Fatigue is extremely contextual and fixing it requires a deep understanding of your data and domain. That is what allows you to tailor bespoke strategies for your solution (ML is inherently multi-disciplinary). The bespokeness of ML creates a very interesting sub-type of problem-
The Long Tail of ML Bugs:
ML bugs often fall into a long tail distribution, where a small number of common issues occur frequently, but there are also a lot of rare and unique bugs unique to individual groups-
While some types of bugs were discussed by multiple participants…the vast majority of bugs described to us in the interviews were seemingly bespoke and not shared among participants. For example, P8 forgot to drop special characters (e.g., apostrophes) for their language models. P6 found that the imputation value for missing features was once corrupted. P18 mentioned that a feature of unstructured data type (e.g., JSON) had half of the keys’ values missing for a “long time.”
This makes it challenging to develop comprehensive testing and debugging strategies. However, while there might be many kinds of bugs, there are only a few ways they cause problems (the authors dub this as “unpredictable causes, predictable symptoms”. Thus dealing with the long tail requires 2 key things- obsessive investments in transparency and the blessings of God. It’s important to invest in transparent AI tools and make it easy (this part is important) to monitor different slices of your data-
Basically there’s no surefire strategy. The closest that I’ve seen is for people to integrate a very high degree of observability into every part of their pipeline. It starts with having really good raw data, observability, and visualization tools. The ability to query. I’ve noticed, you know, so much of this [ad-hoc bug exploration] is just — if you make the friction [to debug] lower, people will do it more. So as an organization, you need to make the friction very low for investigating what the data actually looks like, [such as] looking at specific examples.
This has been a long one, but we’re very close to the finish line. Let’s end on a discussion of the MLOps anti-patterns (“a common response to a recurring problem that is usually ineffective and risks being highly counterproductive”) that might be hindering your progress.
Common ML Anti-Patterns
Section 5.2 of the paper sheds light on some common MLOps anti-patterns. Recognizing these anti-patterns is crucial for building robust and reliable ML systems.
Industry-Classroom Mismatch: Many ML engineers report feeling unprepared for the realities of production ML after leaving school. At best, university courses teach you theoretical concepts (this is useless at best- the Computer Science courses I took taught me nothing useful). Courses don’t teach you about handling real-world data, parsing unclear instructions, interacting with various tools/libraries, understanding tradeoffs, or many of the other engineering challenges. Universities teach you how to become researchers, which is a different beast altogether. If you’re a good student, the academic rigor and focus on theory can be a good grounding that will allow you to learn things quickly- but you will still have to invest a lot of effort into teaching yourself.

Keeping GPUs Warm: Multiple interviewees reported that they would constantly run experiments to utilize their computational resources (“keep GPUs warm”). They later realized that the right thing to do was to instead be smart with their experiments and think about what would have the highest ROI. One person claimed that they realized that it was more productive to spend their cognitive resources on one important idea at a time, instead of scattering it in different places. I’m a little confused as to why this isn’t obvious, and I’m not sure if the authors were trolling over us here. If not running experiments for the sake of it isn’t an obvious principle, please tell me why.
Retrofitting an Explanation: Contrary to the last point, this one is actually super important. One thing I try to stress is the theoretical flimsiness of ML. We don’t have a strong foundation for a lot of what we do- a lot of it is experiment. Often, we find things that work first and then come up with explanations later. This isn’t always a bad thing- so long as we acknowledge it. It’s only a problem if we develop overconfidence in what are mostly at best educated guesses.

Undocumented Tribal Knowledge: As ML systems and teams evolve, knowledge about specific models, pipelines, and data intricacies can become concentrated within a few individuals, esp. when This “tribal knowledge” can create bottlenecks and dependencies, hindering collaboration and making it difficult to maintain and evolve systems over time. This becomes a huge person if the key people get promoted, fired, or leave the team for some other reason. To avoid this, prioritize documentation, knowledge sharing, and cross-training to ensure that critical information is accessible to the entire team.

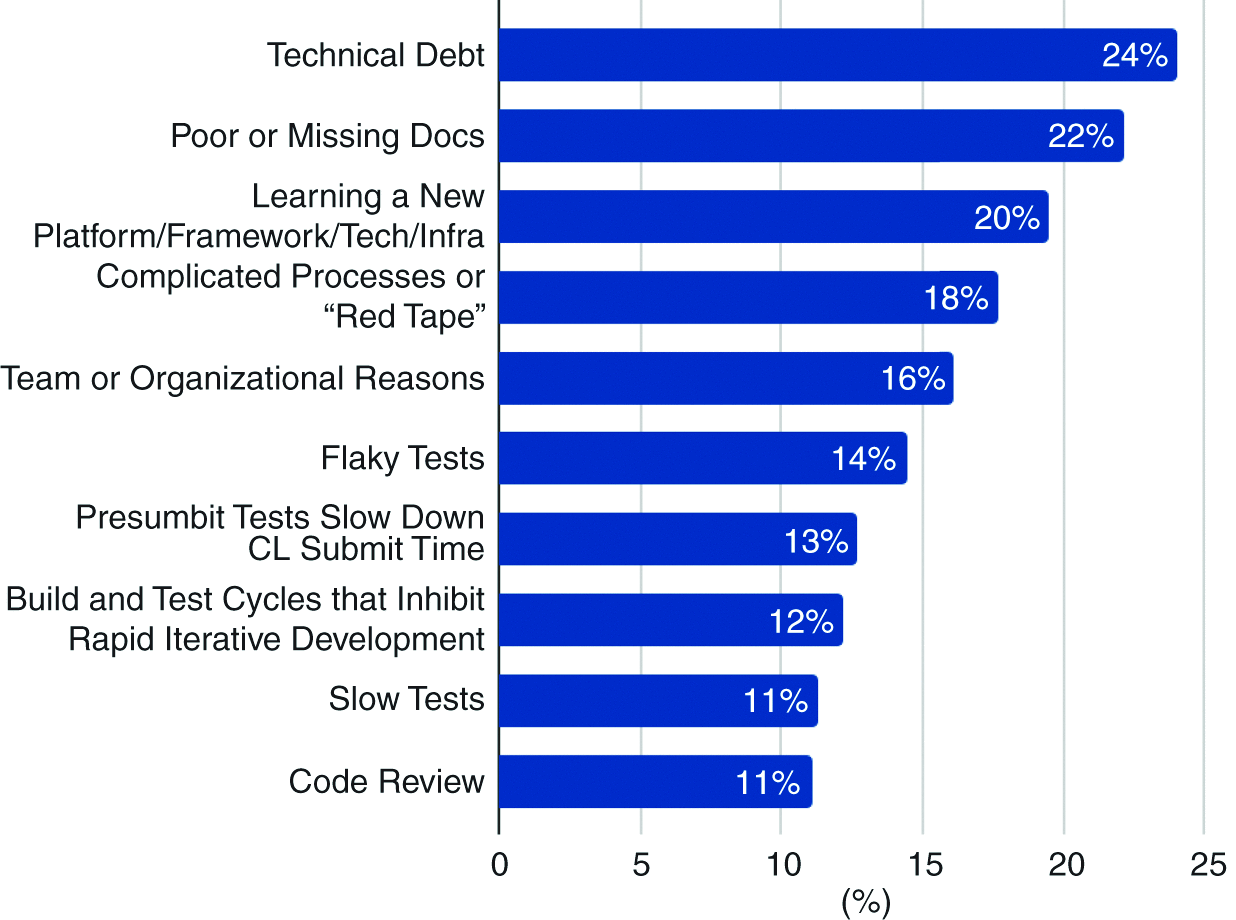
As we covered in our piece on using AI to build better developer tools, tech debt, learning new frameworks and bad/missing docs are massive problems blocking developers. This publication corroborates that (and shows that it’s a problem in companies of all sizes). Thus building solutions that solve these issues will be a huge plus (we covered how in that article). Has your team been successful in buying or using any tools? Or failed with them? Would love to hear about it either way.
If you liked this article and wish to share it, please refer to the following guidelines.
That is it for this piece. I appreciate your time. As always, if you’re interested in working with me or checking out my other work, my links will be at the end of this email/post. And if you found value in this write-up, I would appreciate you sharing it with more people. It is word-of-mouth referrals like yours that help me grow.
Reach out to me
Use the links below to check out my other content, learn more about tutoring, reach out to me about projects, or just to say hi.
Small Snippets about Tech, AI and Machine Learning over here
AI Newsletter- https://artificialintelligencemadesimple.substack.com/
My grandma’s favorite Tech Newsletter- https://codinginterviewsmadesimple.substack.com/
Check out my other articles on Medium. : https://rb.gy/zn1aiu
My YouTube: https://rb.gy/88iwdd
Reach out to me on LinkedIn. Let’s connect: https://rb.gy/m5ok2y
My Instagram: https://rb.gy/gmvuy9
My Twitter: https://twitter.com/Machine01776819
I'm amazed that in this lengthy article there isn't a single mention of the largest potential source of error in the data - data bias due to either undetected biases in the population, or due to inappropriate selective sampling of the data. Data teams need to check continually to ensure that the data that is being used is truly representative of the population being modeled and to take care to evaluate whether population biases are creeping in - not to mention their own biases.