
Using AI to build better Developer Tools [Breakdowns]
Analyzing Google's publication "What Do Developers Want From AI?"

Hey, it’s Devansh 👋👋
In my series Breakdowns, I go through complicated literature on Machine Learning to extract the most valuable insights. Expect concise, jargon-free, but still useful analysis aimed at helping you understand the intricacies of Cutting-Edge AI Research and the applications of Deep Learning at the highest level.
I put a lot of effort into creating work that is informative, useful, and independent from undue influence. If you’d like to support my writing, please consider becoming a paid subscriber to this newsletter. Doing so helps me put more effort into writing/research, reach more people, and supports my crippling chocolate milk addiction. Help me democratize the most important ideas in AI Research and Engineering to over 100K readers weekly.
PS- We follow a “pay what you can” model, which allows you to support within your means. Check out this post for more details and to find a plan that works for you.
Executive Highlights
Llama 3’s release has led to a lot of excitement within the developer community. According to the CEO of HuggingFace, we have already seen almost 1000 fine-tuned Llama 3 variants, since its release. Amongst the most notable changes has been the increased focus on code in both Llama’s Database and evaluation-
It’s been trained on our two recently announced custom-built 24K GPU clusters on over 15T token of data — a training dataset 7x larger than that used for Llama 2, including 4x more code.
This is far from the only high-profile LLM roll-out that features a heavy emphasis on code in recent months. DBRX, Gemini, and Cohere, are all some recent examples of a high-profile LLM roll-out choosing to highlight its coding capabilities.

This area of focus makes sense. From a data perspective, code is structured since it follows syntax rules, programming conventions, and paradigms. All of this makes it well-suited for AI training. From a utility perspective, Code is a medium that enables leverage. Thus, teams have been exploring the development of AI-powered coding assistants for a while now. While such tools have limitations, they have delivered promising results-

In these market conditions, “What Do Developers Want From AI?” by Google’s Engineering Productivity Research Team and Developer AI Team is a must-read. It has some pretty insights into what kinds of AI tools/capabilities would help software engineers most. We will be relying on it to answer two important questions:
What do developers want from AI: In a nutshell, devs want AI to act as a support tool: whether that’s through automating simple tasks, or if it’s through supporting difficult tasks like learning. Developers DO NOT (please pay special attention here) want a system that does everything. This makes sense because of two reasons. Firstly, the more you outsource to AI, the harder it becomes to do basic quality checks and security analyses. Secondly ( HR and MBA folk will love this)- having appropriate oversight helps you avoid expensive lawsuits.
How to do this: We will build on the insights gained from this publication to go into some ways that organizations can set themselves up for more effective use of AI. Most AI attempts fail b/c the processes are not set up to collect the right kinds of data, which severely limits the performance (and development gets halted by approval-seeking processes). We will discuss some ways to avoid this, based on what I’ve seen work for me personally and for my clients.
Even if you aren’t directly building (or buying) tools for software developers, understanding the principles covered here can be used to build effective AI solutions in other domains. Also, before we begin, a very special thank you to Sarah D’Angelo, Staff Researcher at Google (and one of the authors of this paper) for sharing this with me. She does some very interesting research on productivity, so make sure y’all reach out to her (we previously covered her insights into creativity here).
Let’s get right into it.
What kinds of problems do Developers Face?
Before you start building/buying tools for your developer team, it always helps to understand what kinds of blockers said developers are dealing with. Otherwise, you end up spending on things no one wants. Below are the top 10 challenges that Google Devs-
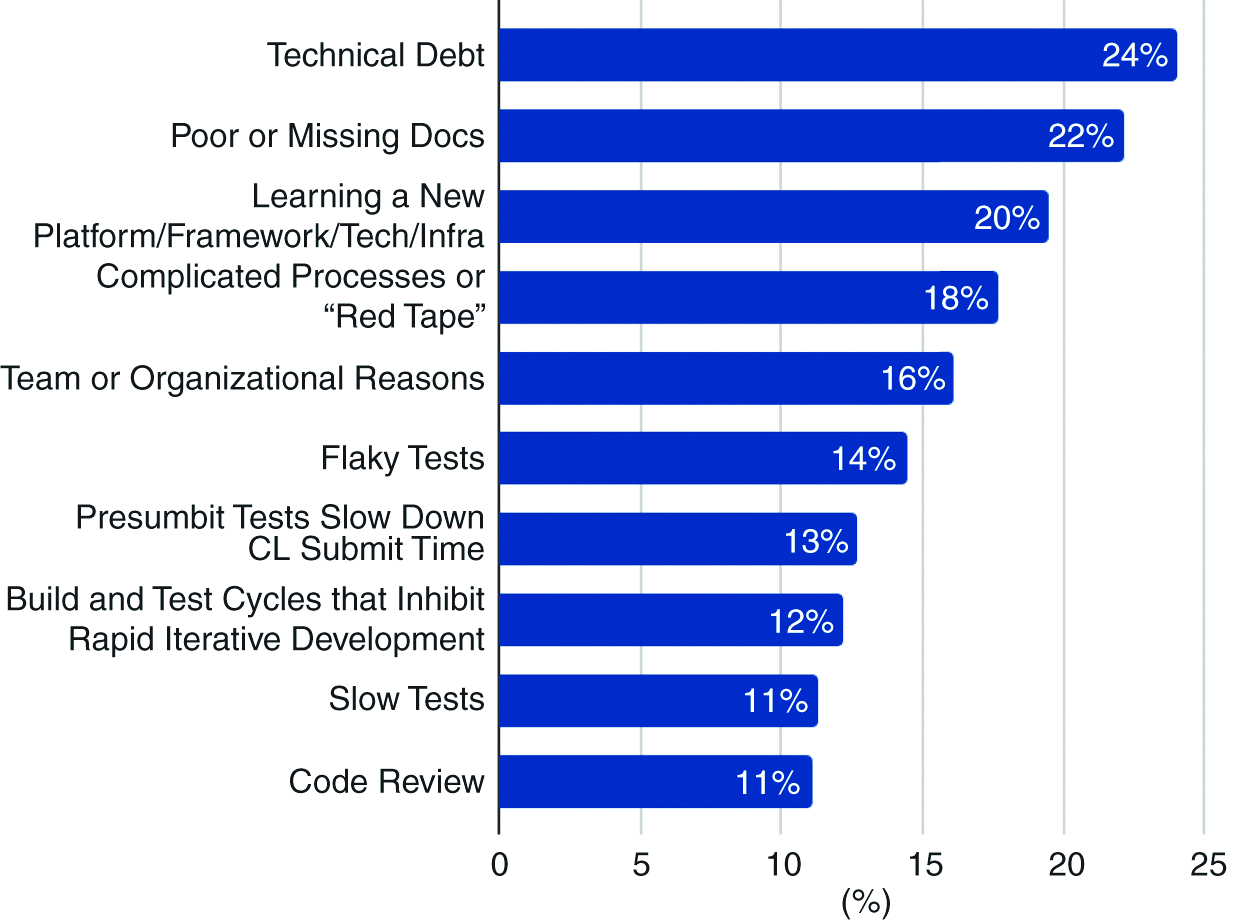
This survey being restricted to Google adds some drawbacks about its general applicability. However, the overall trends/results are worth looking at. “The top hindrance is consistently technical debt, and the following two most common hindrances are interesting opportunities for AI: 1. poor or missing documentation and 2. learning a new platform, infrastructure, framework, or technology”. These show up in 66% of the responses. Thus, building AI Solutions to address these challenges is a good place to start.
This leads to the next question. What kinds of solutions would work best? The researchers provide a pretty good framework for splitting AI abilities into 3 categories-
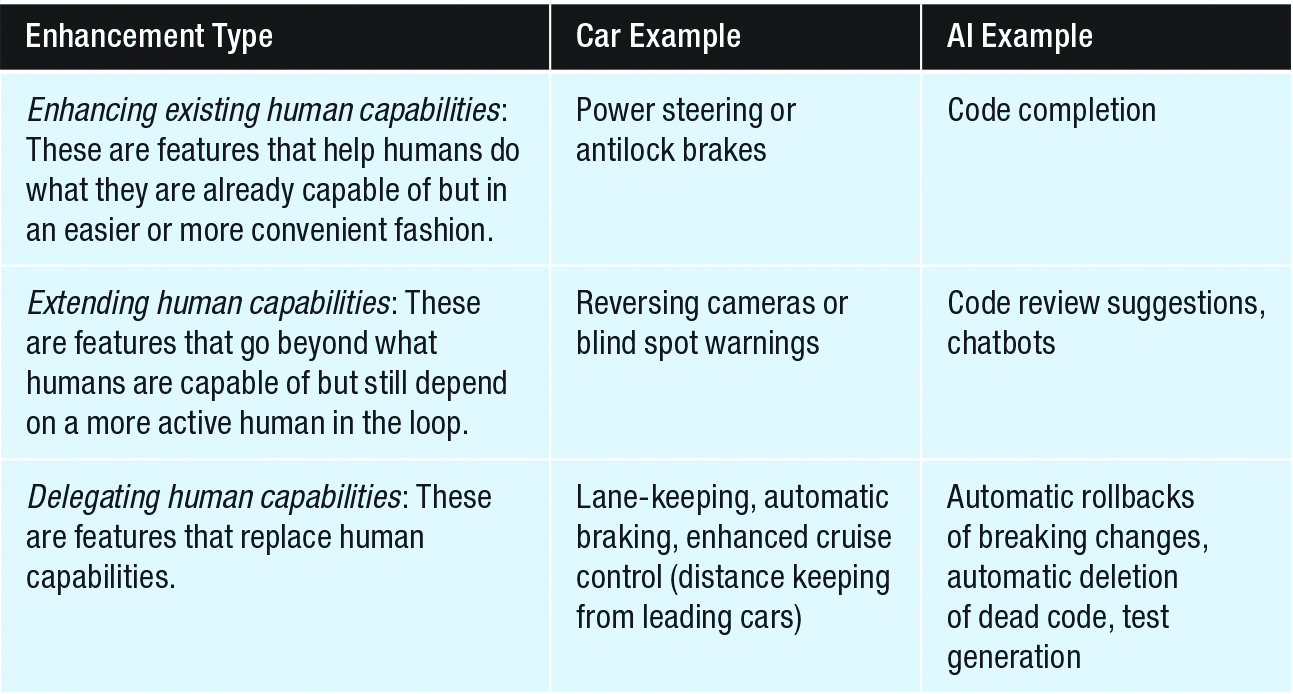
Most of our current solutions tend to be a mix of type 1 and 3: we feed LLMs prompts which then generate the code. You also have some fairly successful ‘pure’ solutions that focus on one particular type: CI/CD, automated testing, etc.
Splitting AI’s expected tasks into such a framework helps us a lot with clarity. As we’ve talked about in the past, one of AI's biggest risks is that we are treating it like magic. This is reflected in the flimsy evaluation protocols/tests that are becoming all too common. Current LLM benchmarks often are too broad, too vague, and too general to give us specific insight into the performance of a system. Splitting the AI like this allows us to craft more specific metrics that personalize the evaluations to you. This is important, b/c when it comes to AI, only you matter. Industry practices/benchmarks are nice to lean on, but ultimately the focus has to be on you: your customers, workflows, and other quirks unique to your organization (and people say I’m not romantic). Iterating on such frameworks helps you add more granularity to your operations, which is key to enabling said personalization.
Let’s get back to AI for developers. So what do software developers want?
What Software Developers want from AI
Both Google’s research, and this excellent publication by Github (amongst others), reach similar conclusions: developers want tools that will unblock them, but not take over the entire process.
While developers were eager to get AI assistance with the sense making process, they pointed out that they still want to have oversight. They want to see what sources the AI tool is using, and be able to input additional sources that are situationally relevant or unknown to the AI…
Developers also find it overwhelming to determine the specific steps to solve a problem or perform a task. This activity is inherently open-ended — developers suffer from cognitive load as they evaluate different courses of actions and attempt to reason about tradeoffs, implications, and the relative importance of tighter scope (for example, solving this problem now) versus broader scope (for example, investing more effort now to produce a more durable solution). Developers are looking for AI input here to get them past the intimidation of the blank canvas. Can AI propose a plan — or more than one — and argue the pros and cons of each? Developers want to skip over the initial brainstorming and start with some strawman options to evaluate, or use as prompts for further brainstorming. As with the process of sense making, developers still want to exercise oversight over the AI, and be able to edit or cherry-pick steps in the plan.
Even in the more complex problem-solving tasks, the value added from AI ends up being the same- reduction of cognitive load. In that sense, the AI system that will handle the brainstorming wouldn’t need to be perfect. Instead, it would be worthwhile to focus on quick prototyping, the ability to pull from a lot of sources, a more organized synthesis of results, and advanced user interactivity. I bring this up b/c these are possible, even with current technology. And they are much easier than the development of super-intelligence. Given how expensive training these models is becoming, this pivot is worth thinking about.
We already have built some very powerful foundation models. Even with relatively immature processes/adoptions, we are seeing some productivity gains from these models. That’s why I think it’s worthwhile to focus on building good products/systems around these powerful FMs and opposed to burning money on increasingly larger models.

Let’s try that with an example to see how that might be accomplished. Take the blocker- learning new technologies. We can create 3 sub-tasks of different enhancement types-
Help developers learn faster/more easily by generating boilerplate or taking care of more tedious implementation details (ET1). Copilot does this well.
Augment the developer’s capabilities by providing recommended resources or enhanced searches (ET2). This is a combination between search and RAG, both of which need much more than just a fancy LLM.
Duolingo/Khan Academy/Brilliant style evaluations + reminders, to drill learning (ET3). Already done.
As you can see, good engineering comes in clutch. Side note- Google’s framework is surprisingly generalizable to other fields (we could segment the AI I built at Clientell for improving Salespeople performance into similar categories). I like that. I wonder how priorities would change across different fields.
Building/buying the right tools is a good start. However, it’s not where the true gains happen. If you want to take the AI productivity version of Trenbologna sandwiches, you gotta think bigger. Go deeper. It makes sense to rebuild existing systems or processes to integrate them with AI/better data collection. This ends up being very important, especially from an organizational perspective, since it helps address some of their major concerns when implementing AI-
Let’s end with a discussion of how you might want to accomplish this, based on my experiences with my projects/my clients (FYI- I’m looking to take on some new clients, so shoot me a message to see if we could work together).
Restructuring your Org to enable AI
As I mentioned in the tl;dr- AI attempts fail b/c they lack the right kind of data. Here we will discuss some ways that you can either reengineer existing workflows to enable AI or build new ones. Keep in mind that the former can be very difficult when processes are too entrenched in workflows, and changing them breaks a lot of things. In such cases, rebuilding should be considered (or switching focus to using AI somewhere else). No matter how much you dress them up, sometimes your baby is just ugly. In such cases, it’s best to get rid of the monstrosity, and hope you have better luck next time.
For now, let’s assume we’re past that hurdle. How we do we go about building AI Enabled workflows? Here are some important components-
Communication
We also ask developers how they feel about AI in their workflows. While a majority of developers express positive impacts of AI and are in various stages of trusting it to assist their workflows, others said they do not want AI in their workflows.
-From the Google Paper.
This is always key. Any new venture will lead to a lot of friction, especially from the devs who have to deal with the changes directly. That’s why it’s important to overcommunicate everything about the project- what the expected changes are, the expected returns, how this is expected to fit into a larger system…This arms your developers with the knowledge required to make the changes themselves/critique plans. Communication is always a very important first pillar to making this change successfully.
Documentation
Good documentation enables strong asynchronous communication. It provides clarity to your whole team about the desired goals and the work done to achieve them. Clarity will supercharge a team’s productivity. From a language model perspective, good documentation will also make indexing/search easier which has several benefits-
It helps developers debug faster by seeing if someone else has encountered their error.
It can be used to find the right people across large organizations.
Facilitates knowledge sharing.
Helps in enforcing style/good practices.
Documentation quality is very important for any LLM-based searches. The authors of the excellent, “What Evidence Do Language Models Find Convincing?” did some great work showing us how RAG systems prioritize text sources when indexing/searching. B/w two conflicting sources, they are more likely to pick one that is more explicitly similar to the query (“more relevant”). For example, if you said does “A cause B”, they will pick a document that states “this document answers if A causes B” over a Meta-analysis of the topic (higher quality information) which is not as well-worded. “Overall, we find that current models rely heavily on the relevance of a website to the query, while largely ignoring stylistic features that humans find important such as whether a text contains scientific refernces or is written with a neutral tone. Taken together, these results highlight the importance of RAG corpus quality (e.g., the need to filter misinformation), and possibly even a shift in how LLMs are trained to better align with human judgements.”

For AI-based systems, it’s important to store data in a way that’s not just human-readable, but AI-readable. Good documentation is not just restricted to code/docs. Building in AI/data analytics will unlock new sets of capabilities that are not traditionally the focus. This extends the definition of documentation and what we can do. Let’s talk about Logging.
Logging as a Source of Data
Building better logs is a seriously underrated source of data. If you integrate logs into more steps of your process, you can monitor performance to identify weaknesses in your system. You can build these logs in ways that make it easy to run automated data analysis scripts on them. This will make your monitoring much easier, boosting the security and transparency of your system with very little additional effort.
However, there are inefficient ways to do this. Someone I know was dumping all their errors/outputs into a singular log file, and then attempting to use a multimodal LLM to perform various kinds of Information retrieval/Analysis on it (for example, asking the LLM to give the average of the values of a certain attribute). This has many drawbacks.
Don’t use a powerful multi-modal system on bad/jumbled data. Store data in different modalities so that you can perform various kinds of analysis on them (this way you can also use simpler/cheaper solutions). Also keeps your life much cleaner.
Feature Importance and Saliency
When you start utilizing ML Models, it’s very important to understand why they are making the decisions they do. There are lots of techniques like studying feature importance for tabular data or saliency maps for Computer Vision that can help you understand what variables your ML Models are looking at. This is often neglected, but is not only good engineering but can also save you lots of money in avoiding bad publicity/lawsuits.
Take Twitter for example (this is from back when they were a public company). When images are too big to be loaded, social media platforms will only display a small portion of them. Interested users can choose to click on the image preview to view the whole thing. AI is used to select which part of the image is best as a preview (for max engagement).
Twitter users noticed a very interesting phenomenon- for pictures of women, the preview would often cut out their faces out, and zoom in on their bodies. Given the historically high sexualization of women in media and tech being largely male dominated, it was not an unreasonable conclusion that AI had developed a male-gaze of it’s own.
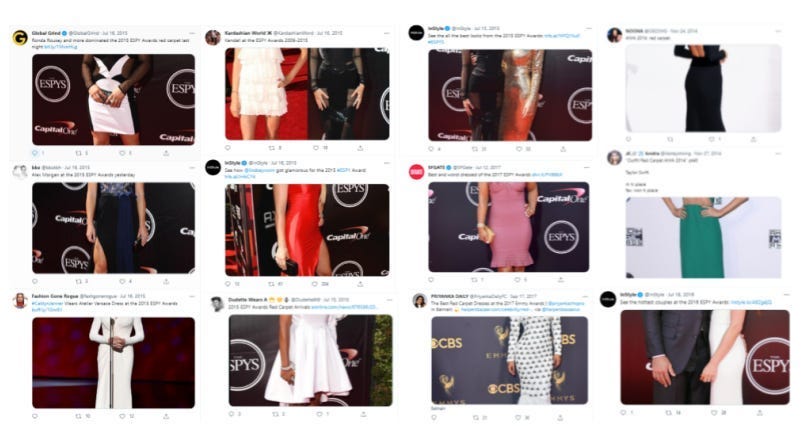
I want you to look at the saliency maps to see if you spot anything-

If we look at what is most consistent across images, one pattern pops up- the AI consistently ranks the corporate logos very highly. This makes sense, since Twitter as a platform is catered towards advertisers. Rather than a male gaze, the AI seems to exhibit a consumerist gaze. Here is what the authors had to say-
In Figure 3b, we see how the focal point mapped to either the fashion accessory worn by the celebrity (left-most image) or the event logo (the ESPYs logo in the middle image) or the corporate logos (the Capital One logo in the right-most image) in the background which resulted in MGL artifacts in the final cropped image. In Figure 3c, we present examples of cases where a benign crop (free of MGL artifacts) emerged out of lucky serendipity where the focal point was not face-centric but was actually located on a background event or corporate logo(s), but the logo coincidentally happened to be located near the face or the top-half of the image thereby resulting in a final crop that gives the appearance of a face-centric crop.
Twitter could have avoided a lot of bad publicity if they had invested into monitoring prior to the internet going crazy over their ‘sexist algorithm’. Instead, they ended up with a lot of bad press for something untrue.
PS- we covered this incident in more detail over here.
Better Testing
To develop AI-based systems, you need good tests. I’ll keep this section light b/c we’re doing more in-depth pieces soon, but you can utilize tools like Prompt Testing, RPA (Robotics Process Automation), and Chaos Engineering to automate large chunks of testing. The latter two is something we do with our clients, so reach out if it interests you. In the meantime, here is a teaser from the upcoming piece on Prompt Testing-

For now, I will just talk about the importance of proper evaluation. As the paper, “Accounting for Variance in Machine Learning Benchmarks” (read this paper at least once a month) tells us- large sources of variance in our ML experiments often completely throw off the evaluations-

Not properly accounting for random sources of variances can lead to you picking the worse model. Let that sink in. If you want to learn how to do it well, read this.
There are lots of engineering techniques that you can use to improve AI safety/pipeline monitoring. However, this was meant to be a starting guide to get you thinking about some of the non-negotiables that any Team should be looking to add into their processes if they are looking to augment them with AI.
What are some non-negotiables you look when building AI projects? Would love to hear it.
If you liked this article and wish to share it, please refer to the following guidelines.
That is it for this piece. I appreciate your time. As always, if you’re interested in working with me or checking out my other work, my links will be at the end of this email/post. And if you found value in this write-up, I would appreciate you sharing it with more people. It is word-of-mouth referrals like yours that help me grow.

Reach out to me
Use the links below to check out my other content, learn more about tutoring, reach out to me about projects, or just to say hi.
Small Snippets about Tech, AI and Machine Learning over here
AI Newsletter- https://artificialintelligencemadesimple.substack.com/
My grandma’s favorite Tech Newsletter- https://codinginterviewsmadesimple.substack.com/
Check out my other articles on Medium. : https://rb.gy/zn1aiu
My YouTube: https://rb.gy/88iwdd
Reach out to me on LinkedIn. Let’s connect: https://rb.gy/m5ok2y
My Instagram: https://rb.gy/gmvuy9
My Twitter: https://twitter.com/Machine01776819
Great article and organisations! Delighted to read this piece!