


What do organizations need to be successful at Machine Learning? [Breakdowns]
Learning how to MLOps from the excellent “Operationalizing Machine Learning: An Interview Study”

Hey, it’s Devansh 👋👋
In my series Breakdowns, I go through complicated literature on Machine Learning to extract the most valuable insights. Expect concise, jargon-free, but still useful analysis aimed at helping you understand the intricacies of Cutting-Edge AI Research and the applications of Deep Learning at the highest level.
I put a lot of effort into creating work that is informative, useful, and independent from undue influence. If you’d like to support my writing, please consider becoming a paid subscriber to this newsletter. Doing so helps me put more effort into writing/research, reach more people, and supports my crippling chocolate milk addiction. Help me democratize the most important ideas in AI Research and Engineering to over 100K readers weekly.
PS- We follow a “pay what you can” model, which allows you to support within your means. Check out this post for more details and to find a plan that works for you.
Executive Highlights (tl;dr of the article)
Companies all over are scrambling to adopt Machine Learning into their workflows. A large part of the focus/investments are directed towards upskilling, hiring, and buying the tools. While these are important, organizations often underestimate the importance of investing in the right MLOps practices. The former set of practices tends to emphasize individual contributions (the fabled ‘10x engineers’) while investing in the latter enables the development of 10x teams- which are more powerful in the long run.
In this article, we will be building on the insights of the excellent publication, “Operationalizing Machine Learning: An Interview Study” to answer how organizations can be more successful at building Machine Learning teams. The goal is to provide a good foundation that you can use to set up Machine Learning teams in your own organization (if you are looking for help with that, please reach out!). As always, if you have any thoughts on this matter, I would love to hear them.

To really enable successful ML Engineering we need to understand two foundational things. Firstly, we must have a good understanding of what ML Engineers do for their work. This then feeds into understanding what drives successful machine learning engineering at organizations-
Production ML Lifecycle Tasks: ML engineers engage in four key tasks: data collection and labeling, feature engineering and model experimentation, model evaluation and deployment, and ML pipeline monitoring and response. These tasks ensure a continuous flow from data preparation to model building, deployment, and ongoing maintenance. Many new organizations tend to overprioritize the model experimentation stage and skimp on the others. This is a big no-no. We will talk about where and why each stage is important and how they fit into the larger picture.

Three Vs of MLOps: Success in MLOps hinges on three crucial factors: Velocity for rapid iteration and prototyping; Validation for early and proactive identification of errors; and Versioning for managing model and data versions to facilitate rollbacks and minimize downtime.
ML Engineering’s Experimental Nature: MLOps thrives on a culture of experimentation. Collaboration with domain experts and data scientists, prioritizing data-driven iterations, and recognizing diminishing returns are key practices. Additionally, keeping code changes small and utilizing config-driven development streamlines the process. A lot of this is generally good Software Engineering practice, but it’s very important to contextualize your practices in an ML setting to better deal with ML’s inherent stochasticity and opaqueness.
Active Model Evaluation: Keeping models effective requires active and rigorous evaluation processes. This involves dynamically updating validation datasets, standardizing evaluation systems across teams, employing multi-stage deployments with progressive evaluation, and focusing on product-centric metrics alongside traditional ML metrics. The last part is worth tattooing onto your forehead b/c teams often forget to contextualize the metrics/evaluation into their domain.
Sustaining Model Performance: Maintaining models post-deployment requires deliberate practices such as frequent retraining on fresh data, having fallback models, incorporating heuristics and filters, continuous data validation, prioritizing simplicity in model design, and implementing organizational practices like on-call rotations and bug queues for efficient response to issues.
The paper also looks into how these insights on MLOps processes reflect on the various challenges and opportunities for improving the MLOps process. We will cover these and explore how to build better MLOps tools in a follow-up article.
The rest of this article will go deeper into understanding the ML Engineering workflow and how you can build better processes for your ML Engineering teams. As always, if this is a challenge you’re looking to solve OR you have some thoughts on this matter- please reach out. With that out of the way, let’s get into the details.

A deep look into MLOps
To set up functioning ML Teams, let’s first take some time to understand what is required for Machine Learning Engineering.
What do Machine Engineers actually do
We’ve already established the four key tasks that all ML Engineers do. Let’s take some time to understand why each of the stages is important and how it plays a role in the greater
Data collection and labeling:
“Data collection spans sourcing new data, wrangling data from sources into a centralized repository, and cleaning data. Data labeling can be outsourced (e.g., Mechanical Turk) or performed in-house with teams of annotators”. Data is the most important part of the whole process, and we have consistently seen that high-quality data is what differentiates different AI setups. A recent example can be seen from Phi 3, which is from a family of Language Models created by Microsoft to be small but trained on the highest quality data. We see Phi-3 outperform Llama despite being comparatively tiny-

Feature engineering and model experimentation-
A common mistake that teams make is to overemphasize the importance of models and underestimate how much the addition of simple features can contribute to performance. Feature Engineering is a great way to integrate domain expertise directly into AI, and good features act as guides for your AI Models, allowing them to reach better convergence. As an added bonus, the integration of features improve the transparency of your system- giving you better insight into why your models do what they do. If you’re struggling to improve your AI performance, consider moving some resources from models to feature extraction/engineering.
Following is an example where a puny SVM + feature engineering mayches fine-tuned Language Models on language classification in specialized domains-
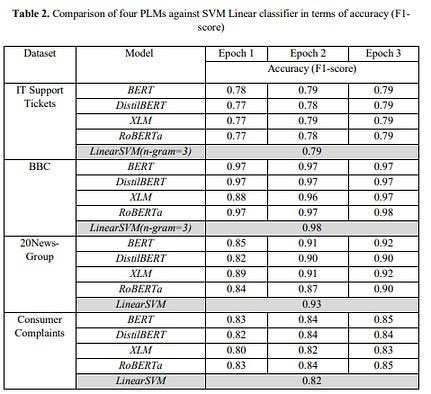
A similar principle applies to Computer Vision. A large reason behind the strength of Complex Valued Neural Networks in Vision is their ability to pull out better features- “CoShRem can extract stable features — edges, ridges and blobs — that are contrast invariant. In Fig 6.b we can see a stable and robust (immune to noise and contrast variations) localization of critical features in an image by using agreement of phase.”
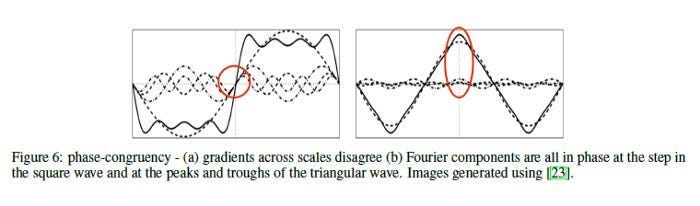
When it comes to detecting features (and their magnitudes) in images where perturbation applies, this works very well.

Better features contribute to better decision boundaries, which leads to superior performance. It also saves you a lot of compute. When possible, look into how you can do more to extract features/integrate domain expertise into your AI models. It’s a smarter approach than helping Cloud Providers or Nvidia execs buy another vacation home. Not to fan-boy too hard on complex-valued NNs, but this is precisely why they are good- their phasicness aligns well with domains like signal processing and vision- leading to better features extracted.

Of course different model architectures have their own inductive biases and limitations, so models themselves are not trivial. Far from it. However, their importance is often overstated by people.
Model evaluation and deployment
Model evaluation is to ML Engineering what Rodri is to Man City- the overlooked engine responsible for success. People cut corners in this portion. Don’t be people. Use cross-validation, use multiple splits, and integrate sources of randomness into your testing. Otherwise you will end up with incomplete evaluations and possibly even the wrong model.

ML pipeline monitoring and response.
Unfortunately, your work isn’t done when you upload the model into production. Things can change for various reasons, leading to data drift. Here are a few-
Consumer behavior changes over time, leading to the need for new models.
Changes in some library you’re using breaks code you’ve written.
Updates to underlying Operating Systems change the values of the features extracted (has happened to me).
You start collecting more data/increase scope of the model- requiring more updates.
Users find new bugs for you.
For strong monitoring, it helps to focus on explainability and transparency. While there are techniques for this in Deep Learning, DL is fundamentally limited here. This is why I’ve always advocated for simple models and utilizing traditional AI techniques where possible. It helps a lot with security and transparency, even if DL models are considered more powerful. Below is an excerpt from our discussion on, “How to Pick between Traditional AI, Supervised Machine Learning, and Deep Learning” that picks at this in more detail-

Now that we have a good understanding of the scope of an ML Engineer’s job, let’s look into what drives success in MLOps.
Three Vs of MLOps:
The authors note the following 3Vs as the key to MLE success-
“Velocity. Since ML is so experimental in nature, it’s important to be able to prototype and iterate on ideas quickly (e.g., go from a new idea to a trained model in a day). ML engineers attributed their productivity to development environments that prioritized
high experimentation velocity and debugging environments that allowed them to test hypotheses quickly.Validation. Since errors become more expensive to handle when users see them, it’s good to test changes, prune bad ideas, and proactively monitor pipelines for bugs as early as possible. P1 said: “The general theme, as we moved up in maturity, is: how do you do more of the validation earlier, so the iteration cycle is faster?”
Versioning. Since it’s impossible to anticipate all bugs before they occur, it’s helpful to store and manage multiple versions of production models and datasets for querying, debugging, and minimizing production pipeline downtime. ML engineers responded to buggy models in production by switching the model to a simpler, historical, or retrained version”
When making leadership decisions (or looking at various tools that might be helpful)- it is best to look at how decisions will impact these 3 Vs. The next insight ties into this theme very well. Let’s talk about the ML’s experimental nature and how we can
Unlocking ML Engineering’s Experimental Nature:
ML Engineering is a lot more chaotic than traditional software engineering. Good ML Engineering teams embrace the chaos instead of shying away from it. Here are some ways
Collaboration is key: Successful project ideas often stem from collaboration with domain experts, data scientists, and analysts. This is both the challenge and power of ML- it’s an inherently multi-disciplinary field with where we have to loop in insights and knowledge from very different experts. “We really think it’s important to bridge that gap between what’s often, you know, a [subject matter expert] in one room annotating and then handing things over the wire to a data scientist — a scene where you have no communication. So we make sure there’s both data science and subject matter expertise representation [on our teams]”
Focus on data iteration: Prioritizing data-driven experiments like adding new features can lead to faster iteration and improvements. We’ve already talked about the high ROI of data, so I’m not going to harp too much on this here. “I’m gonna start with a [fixed] model because it means faster [iterations]. And often, like most of the time empirically, it’s gonna be something in our data that we can use to kind of push the boundary…obviously it’s not like a dogmatic We Will Never Touch The Model, but it shouldn’t be our first move”
Account for diminishing returns: Recognizing the diminishing returns of experiments as they progress through deployment stages helps prioritize efforts and avoid wasted time. This is one of the reasons that I believe that every Engineer/Researcher should be clued into the larger business process. It allows the technical folk to make better decisions and judge ROI more accurately. “end-to-end staged deployments could take several months, making it a high priority to kill ideas with minimal gain in early stages to avoid wasting future time. Additionally, to help with validating early, many engineers discussed the importance of a sandbox for stress-testing their ideas (P1, P5, P6, P11, P12, P13, P14, P15, P17, P18, P19). For some engineers, this was a single Jupyter notebook; others’ organizations had separate sandbox environments to load production models and run ad-hoc queries”
Small changes are preferable: Keeping code changes small facilitates faster review, easier validation, and fewer merge conflicts, especially in large organizations where config-driven development is common.
Setting up your SOPs/workflow to encourage these will go a long way to improving your MLOps. The rapid experimentation will allow you to develop strong systems. Next comes evaluation. Let’s cover that next-
How to Evaluate your Machine Learning
The paper emphasizes the need for active and continuous model evaluation in MLOps, highlighting the limitations of traditional static approaches. Here are the key takeaways:
Dynamic Validation Datasets: Continuously update validation datasets to reflect real-world data and capture evolving patterns, ensuring accurate performance assessments. We’ll do an in-depth investigation into catching data drift soon. “Although the dynamic evaluation process might require many humans in the loop — a seemingly intense organizational effort- engineers thought it was crucial to have. When asked why they invested a lot of energy into their dynamic process, P11 said: “I guess it was always a design principle — the data is [always] changing.” ”
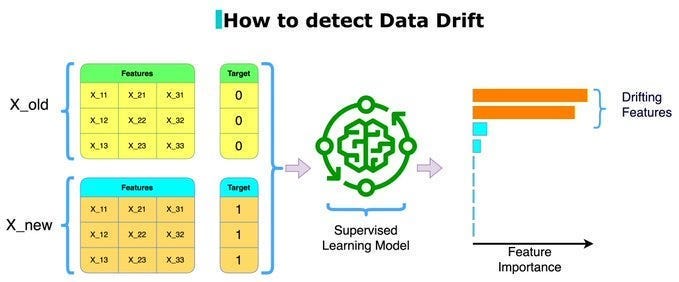
Standardized Validation Systems: Implement consistent evaluation processes and metrics across teams to facilitate objective comparisons and collaboration. Standardizing Validation has an interesting impact of Velocity. It definitely hits velocity, since a dev can’t push their changes willy-nilly. However, it reduces friction from people using different standards, improving larger-scale collaboration. The overall benefits of this outweigh the impact on velocity (not to mention the improvement in average quality)- so this is a strong recommendation for any AI team.
Multi-Stage Deployments: While offline evaluation is essential, it doesn’t fully capture the complexities of a live production environment. The paper proposes a multi-stage deployment process where models are progressively rolled out to increasing percentages of users, with thorough evaluation at each stage. This allows for early detection of issues and provides opportunities to refine the model before it impacts the entire user base. One interesting idea was the “shadow mode,” where the model generates predictions on live data but doesn’t expose them to users. This allows for direct comparison with the existing model and assessment of the new model’s impact without affecting user experience.
Product-Centric Metrics: Evaluate models based on metrics aligned with business goals, such as click-through rate or user churn, to ensure they deliver tangible value. “Tying [model performance] to the business’s KPIs (key performance indicators) is really important. But it’s a process — you need to figure out what [the KPIs] are, and frankly I think that’s how people should be doing AI. It [shouldn’t be] like: hey, let’s do these experiments and get cool numbers and show off these nice precision-recall curves to our bosses and call it a day. It should be like: hey, let’s actually show the same business metrics that everyone else is held accountable to to our bosses at the end of the day.”
There is nothing to be gained by cutting corners in the evaluation process. Spend a lot of time on it.
Let’s say we have a model that meets all our needs. How do we stop our prince charming from losing hair, putting on weight, and turning into a frog? Let’s talk about that next-
Keeping your Model Performant.
Here are some ways for maintaining model performance post-deployment and minimizing downtime:
Frequent retraining and labeling: Regularly retraining models on fresh, labeled data helps mitigate performance degradation caused by data drift and evolving user behavior. Depending on your product, it is possible to overdo this. Take TikTok’s RecSys below. The performance of the 5-hour sync interval and the 30-minute interval is close enough that I would rather take the cost savings of not updating as frequently. This might be personal bias given my experience in low-resource ML environments, but it’s always worth thinking about the ROI of updates.

Fallback models: Maintaining older or simpler versions of models as backups ensures continuity in case the primary model fails.
Heuristics and filters: Adding rule-based layers on top of models can help address known failure modes and prevent incorrect outputs.
Data validation: Continuously monitoring and validating data entering and exiting the pipeline helps identify and address data quality issues that can impact model performance.
Simplicity: Prioritizing simple models and algorithms over complex ones can simplify maintenance and debugging while still achieving desired results.

Organizational practices: Implementing processes like on-call rotations, central bug queues, service level objectives (SLOs), and incident reports helps effectively manage and respond to production issues.
If your organization is looking to expand its capacities in Machine Learning, it first makes sense to understand where you are currently and then build up from there. Hopefully, this article gives you a good area to start. If you’re looking for an outside perspective on this, shoot me a message. Would be happy to talk shop.
If you liked this article and wish to share it, please refer to the following guidelines.
That is it for this piece. I appreciate your time. As always, if you’re interested in working with me or checking out my other work, my links will be at the end of this email/post. And if you found value in this write-up, I would appreciate you sharing it with more people. It is word-of-mouth referrals like yours that help me grow.
Reach out to me
Use the links below to check out my other content, learn more about tutoring, reach out to me about projects, or just to say hi.
Small Snippets about Tech, AI and Machine Learning over here
AI Newsletter- https://artificialintelligencemadesimple.substack.com/
My grandma’s favorite Tech Newsletter- https://codinginterviewsmadesimple.substack.com/
Check out my other articles on Medium. : https://rb.gy/zn1aiu
My YouTube: https://rb.gy/88iwdd
Reach out to me on LinkedIn. Let’s connect: https://rb.gy/m5ok2y
My Instagram: https://rb.gy/gmvuy9
My Twitter: https://twitter.com/Machine01776819
Hi Devansh,
It's really cool to see you interleave concrete examples to back some of the points you highlight (e.g. iterate on the data not the model).
First, you're exactly right to think like an org and focus on the team. Star students are celebrated in school, but you wouldn't want to be a hero in MLOps. Productive collaboration practices make the difference for whether small startups can scale-up and continue their growth --- or not. Big orgs like FAANG have figured this out and have a lot of institutional knowledge built-into their processes, toolchains, and practices.
Second, how we close the loop, integrating feedback into future rounds of training and Validation is the crux of MLOps. I think once you can streamline the feedback loop, you have a functioning operation.
Finally, when this paper was written, it was on the cusp of the ChatGPT revolution, and before the mass layoffs. Most things stay the same, but there are a couple important differences worth thinking about.
So much of my professional life I've been taught to assume people salaries are much more expensive than hardware, and to spend more on compute if it makes people more productive programmers. With the massive energy and water needs of generative AI, and the scarcity of NVIDIA's most advanced GPUs, that trend is starting to shift. We're starting to see hardware become more expensive. That could disrupt how we think about programmers and developer productivity. We could be returning to a time like the 50s when massive IBM mainframes justified hiring large teams of operators.
Great work!
Excellent as always, Devansh. Really enjoyed the executive highlights and the highlighting on the graphic showing a section of a paper. I'll add to the experimentation bullet: it's important that experimentation is done thoughtfully because ML doesn't only require a ton of experimentation- that experimentation can also be very expensive.