


TrivialAugment: The next evolution in Data Augmentation [Breakdowns]
Machine Learning (Image Classification) meets German Efficiency

Hey, it’s Devansh 👋👋
In my series Breakdowns, I go through complicated literature on Machine Learning to extract the most valuable insights. Expect concise, jargon-free, but still useful analysis aimed at helping you understand the intricacies of Cutting-Edge AI Research and the applications of Deep Learning at the highest level.
If you’d like to support my writing, consider becoming a premium subscriber to my sister publication Tech Made Simple to support my crippling chocolate milk addiction. Use the button below for a lifetime 50% discount (5 USD/month, or 50 USD/year).
p.s. you can learn more about the paid plan here.
First off, a massive thank you all for your kind words on my recent breakdown Do Language Models really understand Language. It’s always really surreal that so many experts read and appreciate my work, but the reception for that piece has been particularly positive.
Based on the comments, it seems like y’all really love the investigation style pieces- where I go through a bunch of related papers to answer one bigger question. That’s great because those are also more fulfilling to write (although they take way more effort and energy to produce). Going forward, we will do more of those.
The first one I have in mind is about using AI in Mass Surveillance and Internet Suppression (both how it’s used by States, and how we can break it). Since I will not be able to include all my research in the articles, I will be putting it as much I can on Instagram/Twitter/LinkedIn. If you want BTS looks, you’ll be able to find it there. An example from the upcoming Censorship Article can be seen below. Over there I go over Project Geneva (which we covered earlier) and how it overcomes government packet interference. To those of you curious, the next post will be on AI in signal jamming-

I was also given two very interesting ideas for the next investigation. If you’d like to participate in the vote to determine which you prefer (or to suggest a third alternative), come by over here.
Deep Learning requires a lot of computational power to achieve great results. The deep and complex models used to map relationships between features are very costly to train. On top of this, we need tons of input data which is expensive to collect, clean, label, and use in the models. And once you have a model, we need to deploy it so that it can be used. If we’re lucky, things end here. However, many kinds of data are susceptible to phenomena such as Data Drift, so you’ll have to keep monitoring and retraining your data.

So far, the reducing costs of computing (and electricity) along with the high returns of implementing Machine Learning have allowed for the ML Boom. This has led to a trend where more and more researchers and teams are developing models and procedures that are convoluted and expensive just to hit marginal performance gains. The authors of TrivialAugment: Tuning-free Yet State-of-the-Art Data Augmentation buck that trend. Instead, they show that simple techniques can be used to achieve state-of-the-art results.
TrivialAugment is so simple, that the following image is all there is to the implementation. More than being a paper that is ‘impressive’ or ‘difficult’, I wanted to talk about this paper because it highlights something important about AI Research. We will cover this protocol, why it’s important for Machine Learning, and the results it was able to generate. To do so, let’s first understand the basics of Data Augmentation.

Data Augmentation- Background
Data Augmentation is a powerful technique in Machine Learning. It involves taking input data and modifying it by applying functions. We then use both the synthetically generated data and the original data as input for our models. Done right, DA will allow our models to generalize to real-life noisy input much better, while also helping generalize to unseen distributions. Google Researchers were able to beat huge machine learning models using fewer resources using Data Augmentation as one of their pillars.

It is not surprising that there is a lot of research put into Data Augmentation policies. Researchers started to use Machine Learning to evaluate the dataset to figure out the best augmentation policies. This was expensive, but it propelled performance to the next level. It seemed that DA policies would involve complex hyperparameter tuning and complicated policies to be the best. Then, along came RandAugment.

RandAugment was so simple, that its performance didn’t make sense. It only took hyperparameters- N and M. It would then randomly apply N augmentations with the magnitude of M. Not only was this a cheap way to produce to images, but it also completely outperformed everything else.

Naturally, RandAugment took over the world. To read more about this protocol, read this article. Seeing the performance of RandAugment, the authors of TrivialAugment took things a step further.
TrivialAugment
TrivialAugment simplified this a step further. As mentioned earlier, RandAugment has 2 hyperparameters. This is still potentially a lot of tuning. So the authors decide that they will automate this process. TrivialAugment randomly selects an augmentation and then applies it with a selected strength. Don’t believe me, check out this quote from the paper:
TA works as follows. It takes an image x and a set of augmentations A as input. It then simply samples an augmentation from A uniformly at random and applies this augmentation to the given image x with a strength m, sampled uniformly at random from the set of possible strengths {0, . . . , 30}, and returns the augmented image.
Unlike RandAugment, TA fixes on only one augmentation per image. It also samples the strength uniformly. This means that while RA still has to spend some resources going through the dataset with different hyperparameter configurations, TA doesn’t do that.
This might seem too simple to be effective. Logically speaking, there is no way it should be able to outperform the current policies. However, it does just that. Below you can see TA compared to other popular augmentation policies.
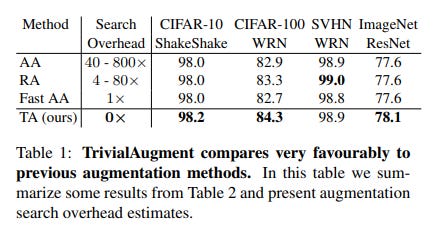
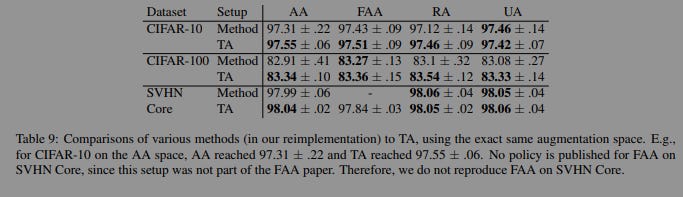
The results here are quite impressive (especially given the overhead). The authors show several other examples TrivialAugment outperforming/matching many other augmentation policies in the image classification tasks over a variety of architectures. The fact that it does so while using significantly few resources goes without saying.
Closing
TrivialAugment obviously a huge step forward for various reasons. Its performance is impressive, but I think its final contribution is much greater than that. I hope that this paper sparks more first-principles thinking. There are probably tons of assumptions that we make that can be simplified. There is great value in going back and evaluating what we consider normal, and checking if something is really the simplest version tested. Below is a quote from the paper that sums it up very well.
Second, TA teaches us to never overlook the simplest solutions. There are a lot of complicated methods to automatically find augmentation policies, but the simplest method was so-far overlooked, even though it performs comparably or better
It’s not as though TrivialAugment is the second-coming of Machine Learning Jesus Christ. Unlike RandAugment and other policies, it doesn’t have great performance in Object Detection tasks (requires tuning here). It is also outperformed on certain augmentation spaces by more sophisticated policies.
That being said, the performance of TA shows us some important conclusions:
Simple methods can be used to achieve great results.
As mentioned earlier, it is important to evaluate current practices to see if there are simpler techniques that have not been tested.
This paper is not extraordinarily complex in terms of the idea and execution. But not everything needs to be. Aside from the paper, I would suggest looking at the PyTorch documentation. It will help you implement the technique for yourself.

ElasticTransform transform (see also elastic_transform()) Randomly transforms the morphology of objects in images and produces a see-through-water-like effect.If you liked this article and wish to share it, please refer to the following guidelines.
That is it for this piece. I appreciate your time. As always, if you’re interested in working with me or checking out my other work, my links will be at the end of this email/post. If you like my writing, I would really appreciate an anonymous testimonial. You can drop it here. And if you found value in this write-up, I would appreciate you sharing it with more people. It is word-of-mouth referrals like yours that help me grow.
If you find AI Made Simple useful and would like to support my writing- please consider becoming a premium member of my cult by subscribing below. Subscribing gives you access to a lot more content and enables me to continue writing. This will cost you 400 INR (5 USD) monthly or 4000 INR (50 USD) per year and comes with a 60-day, complete refund policy. Understand the newest developments and develop your understanding of the most important ideas, all for the price of a cup of coffee.

Reach out to me
Use the links below to check out my other content, learn more about tutoring, reach out to me about projects, or just to say hi.
Small Snippets about Tech, AI and Machine Learning over here
AI Newsletter- https://artificialintelligencemadesimple.substack.com/
My grandma’s favorite Tech Newsletter- https://codinginterviewsmadesimple.substack.com/
Check out my other articles on Medium. : https://rb.gy/zn1aiu
My YouTube: https://rb.gy/88iwdd
Reach out to me on LinkedIn. Let’s connect: https://rb.gy/m5ok2y
My Instagram: https://rb.gy/gmvuy9
My Twitter: https://twitter.com/Machine01776819
Just wanted to say I really appreciate your visuals in your breakdowns!
There was a buzzword recently: Synthetic Data. DA sounds like a tool in that broader space. Synthetic Data is a way to overcome dirty and biased data too.