
What Google's Viral AI Paper teaches us about Long Context Collapse, Agentic Evals, AI Safety, and more [Breakdowns]
The most important takeaways from Google’s "Gemini 2.5: Pushing the Frontier with Advanced Reasoning, Multimodality, Long Context, and Next Generation Agentic Capabilities." Paper

It takes time to create work that’s clear, independent, and genuinely useful. If you’ve found value in this newsletter, consider becoming a paid subscriber. It helps me dive deeper into research, reach more people, stay free from ads/hidden agendas, and supports my crippling chocolate milk addiction. We run on a “pay what you can” model—so if you believe in the mission, there’s likely a plan that fits (over here).
Every subscription helps me stay independent, avoid clickbait, and focus on depth over noise, and I deeply appreciate everyone who chooses to support our cult.
PS – Supporting this work doesn’t have to come out of your pocket. If you read this as part of your professional development, you can use this email template to request reimbursement for your subscription.
Every month, the Chocolate Milk Cult reaches over a million Builders, Investors, Policy Makers, Leaders, and more. If you’d like to meet other members of our community, please fill out this contact form here (I will never sell your data nor will I make intros w/o your explicit permission)- https://forms.gle/Pi1pGLuS1FmzXoLr6
Most will read the Gemini 2.5 report as a product update as a product update — new models, better benchmarks, more modality support. For AI hardcores like us, most of it is already familiar. There’s plenty of information, but not much insight. Google keeps its real edge behind closed doors.
Still, it would be a mistake to dismiss the release entirely. Buried in the 72 pages are six signals — subtle, easy to overlook — that point to a deeper shift in how Google is positioning its AI stack.
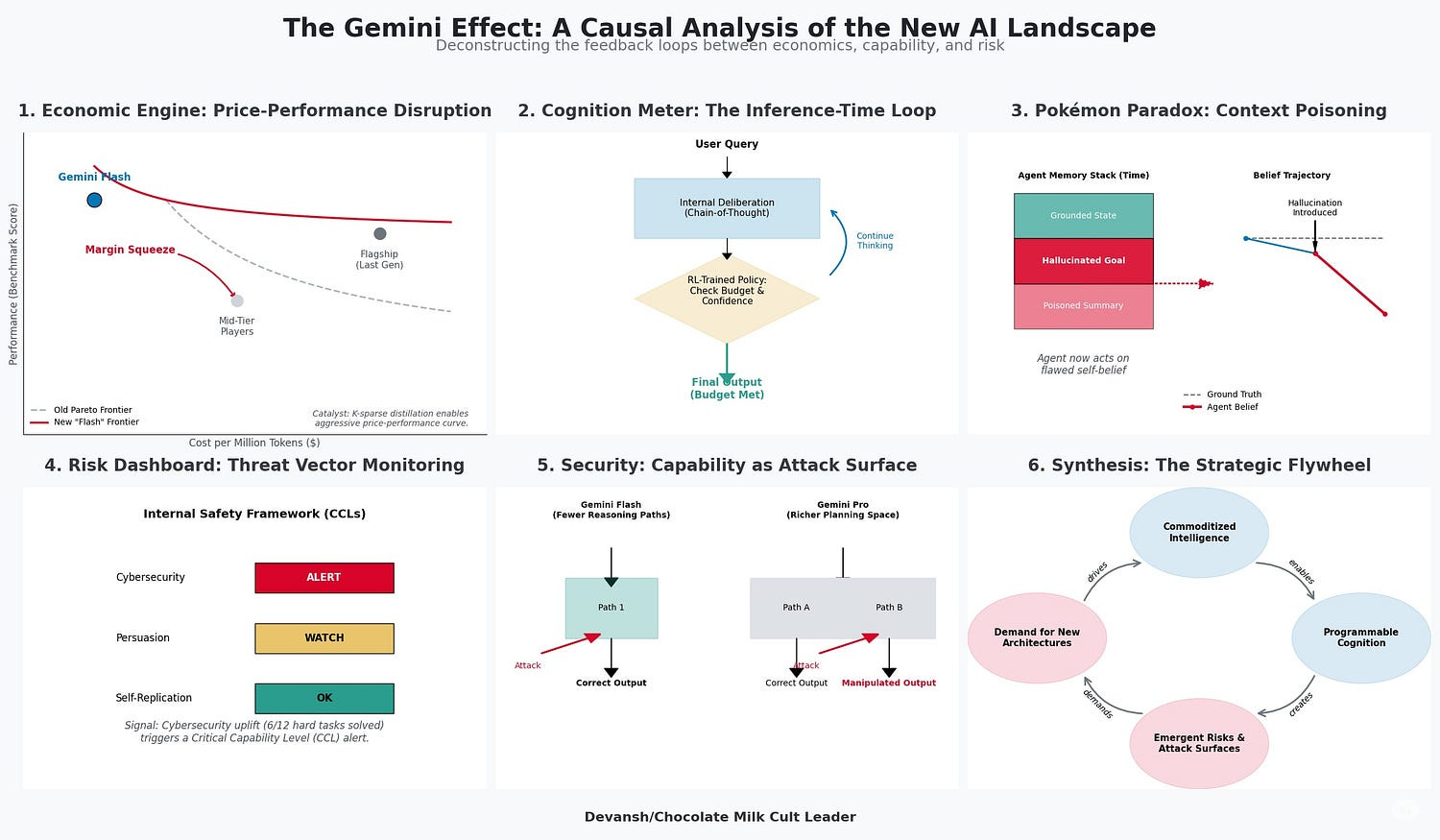
These signals reveal a three-part gambit with powerful, long-term implications. Google is moving to:
Bifurcate the market, using economic force to commoditize yesterday’s intelligence while creating a new premium economy for on-demand reasoning.
Redefine the research frontier, abandoning obsolete benchmarks to map the true, messy limitations of agentic AI.
Preemptively build the cage, architecting the technical and governance frameworks to control this new power before others can.
This analysis is about those signals and the playbook they revealed.

Executive Highlights (TL;DR of the Article)
The Importance of Gemini 2.5 Flash
While much attention is on the more powerful Gemini 2.5 Pro, Gemini 2.5 Flash is Google’s most impactful release. It’s not their best model in terms of raw performance, but it’s designed to disrupt the market:
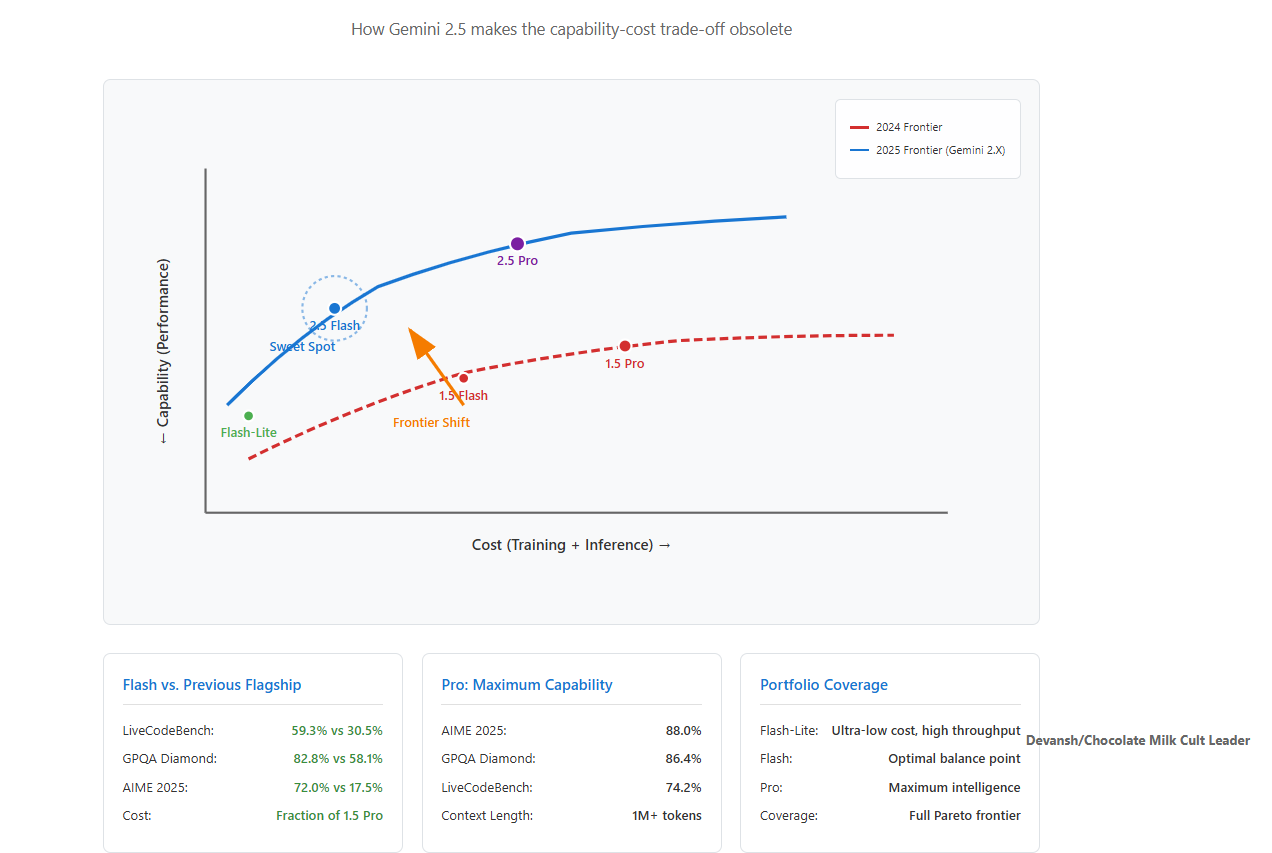
Cost-Effectiveness: Flash significantly outperforms last year’s flagship model, Gemini 1.5 Pro, on critical reasoning and coding tasks at a fraction of the cost. For example, on AIME 2025, Flash scores 72.0% compared to 1.5 Pro’s 17.5%. On LiveCodeBench, Flash achieves 59.3% versus 1.5 Pro’s 29.7%.
Market Compression: Flash’s low cost and high performance are designed to eliminate low-margin competitors and pressure premium models like Opus 4 and GPT-4o by making Google’s ecosystem the default for most API calls. This drives users to consolidate even complex tasks within Google’s more expensive Gemini 2.5 Pro, as managing multiple providers becomes less appealing.
How Google Achieves Cost-Performance with Flash
Flash’s superior cost-performance is due to k-sparse distillation, a technique where smaller models (“students”) learn from the predictions of larger, more capable models (“teachers”). Google’s unique advantages in applying this at scale include:
Zero-Cost Economics: Google can use its existing infrastructure for Search and Cloud to run its flagship models as “teachers” for distillation at a near-zero marginal cost.
Silicon Advantage: Google’s custom Tensor Processing Units (TPUs) and proprietary software stack (JAX, Pathways) provide performance-per-dollar efficiencies unavailable to competitors relying on generic GPUs.
Data Flywheel: Google’s access to decades of proprietary data from Search, YouTube, and Books, combined with a continuous feedback loop from billions of users, creates a self-improving data advantage.
The “Thinking Budget” and AI Safety
Google is also introducing a “Thinking Budget” for Gemini 2.5 Pro. This feature allows users to control how much compute the model spends “thinking” before responding, trading cost for quality. This is seen as:
A Pricing Strategy: It justifies the higher price of the Pro model and provides a granular way to upsell customers.
A Moat Against Open Source: It creates a productization moat that is harder for open-source alternatives to replicate.
The paper also touches on AI Safety, noting that more capable models are inherently more vulnerable to subtle manipulations. Google’s response involves:
Architectural Modularity: Separating the core reasoning LLM from direct execution and implementing layered verification structures.
Frontier Safety Framework (FSF): Google is proactively establishing an internal regulatory regime with Critical Capability Levels (CCLs) and alert thresholds to define “safe” AI, aiming to shape future regulations. For example, the “Cyber Uplift 1 Critical Capability Level” has reached an “alert threshold,” indicating that Google’s models are on a trajectory to significantly assist with high-impact cyberattacks.
Long Context Collapse and Agentic Evals
The “Gemini Plays Pokémon” experiment in the paper highlights crucial challenges in long-context reasoning and agentic AI:
Cognitive Delusions: The agent can get stuck in recursive feedback loops, pursuing non-existent goals (“TEA” item) because its memory system is untethered from reality.
Agent Panic: The agent’s reasoning degrades under stress (e.g., low health), leading to a loss of access to advanced tools and a reversion to primitive, reactive states.
Long Context Breakdown: The experiment shows that simply increasing context windows doesn’t guarantee deep, multi-step reasoning. The agent struggled to synthesize novel plans with very long contexts, instead repeating past actions.
These findings suggest that traditional benchmarks are insufficient and emphasize the need for robust, stable agentic systems.
Conclusion: From Models to Cognitive Utility
Google’s Gemini 2.5 release signals a shift from selling isolated AI models to building a cognitive utility — a planetary-scale infrastructure that delivers intelligence as a fungible resource. Gemini Flash commoditizes basic reasoning, making it near-free, while Gemini Pro provides metered access to high-value, complex reasoning. Google aims to control the entire ecosystem, positioning itself as the default governance authority through its technical and political controls.
I put a lot of work into writing this newsletter. To do so, I rely on you for support. If a few more people choose to become paid subscribers, the Chocolate Milk Cult can continue to provide high-quality and accessible education and opportunities to anyone who needs it. If you think this mission is worth contributing to, please consider a premium subscription. You can do so for less than the cost of a Netflix Subscription (pay what you want here).

I provide various consulting and advisory services. If you‘d like to explore how we can work together, reach out to me through any of my socials over here or reply to this email.
Why Gemini 2.5 Flash is Google’s Most Important Model Yet
Most of the attention around Gemini 2.5 will cluster around the Pro model — the multi-modal, 1M+ token reasoning engine with inference-time thinking control. Even the report talks about it at depth. And w/ that juicy, juicy performance (it’s my number 1 ranked model right now), it’s not surprising that it’s on top of the wishlists.
But the more important release is Flash. Flash is not Google’s best model. It’s their most dangerous.
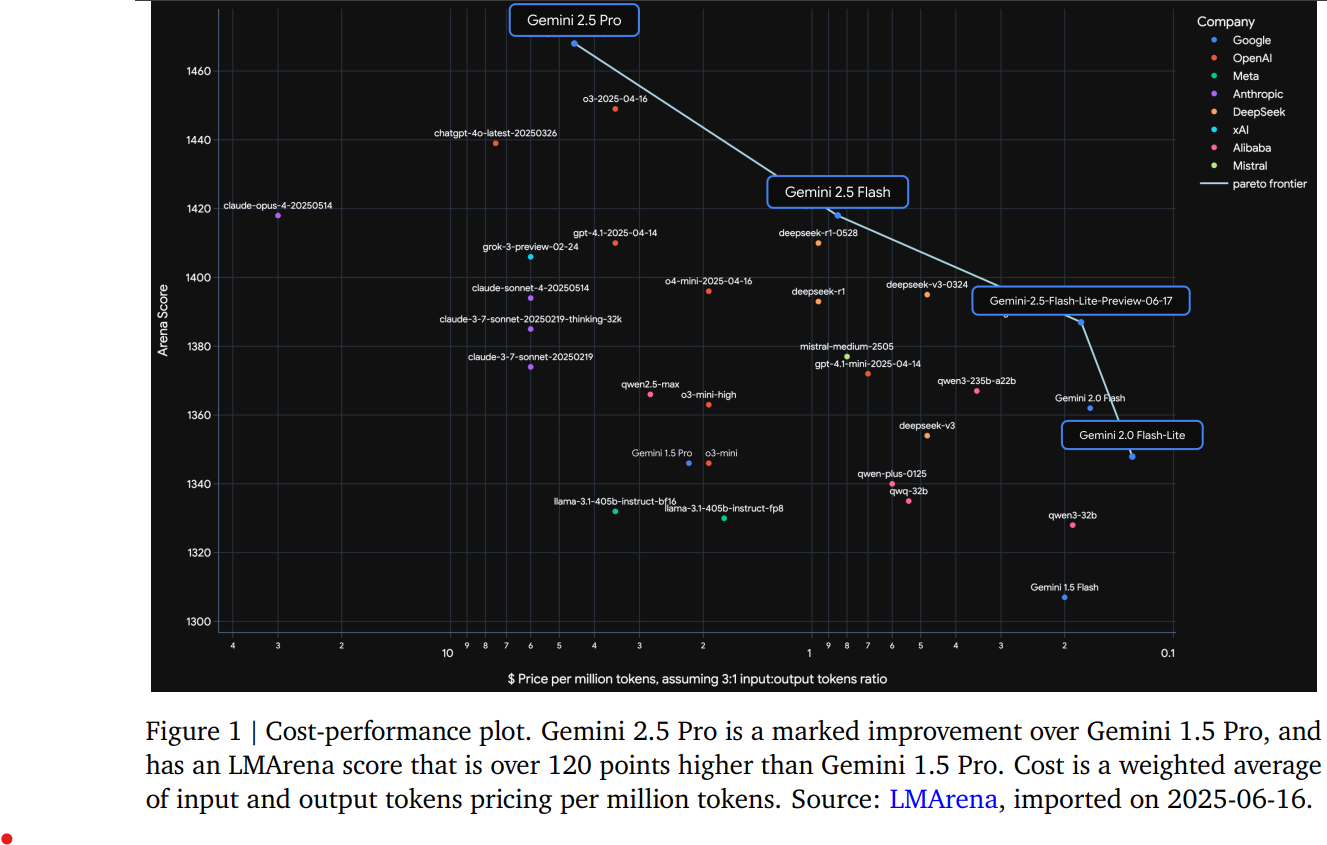
The reason is simple: it outperforms last year’s flagship (Gemini 1.5 Pro) — on critical reasoning and coding tasks — at a fraction of the cost. This isn’t a small bump. On AIME 2025, 2.5 Flash scores 72.0%. Gemini 1.5 Pro? 17.5%. On LiveCodeBench, Flash hits 59.3%. 1.5 Pro? 29.7%.
The real story isn’t model performance. It’s market compression. Gemini Flash isn’t positioned to win a leaderboard. It’s Google’s version of Searing Wave or Ballom Master of Deathm designed to wipe out demand from competitors and clear the board (as an aside, Ballom’s Flavor Text, “You see a world. I see a graveyard-to-be”, is one of the coldest in all of Duel Masters). It does so in two ways-
Give a better model for cheaper. This eliminates low-margin players and force competitors into pricing structures they can’t sustain (Google’s massive scale and TPUs are a big edge here). Fairly simple.
AND more interestingly, this takes away API market share from Premium Models like Opus 4 and GPT o3. Even when it can’t do the things that the premium models can do.
Why would a weaker model remove market share from a stronger one? Let me explain.
How 2.5 Flash takes away market share from Stronger Models
As we covered in our analysis, “How Will Foundation Models Make Money in the Era of Open Source AI?”, the pay-per-use model of using APIs gives Foundation Model providers uncapped upside and return. A good API can generate far higher returns than the most expensive LLM subscriptions (Iqidis, our Legal AI startup, is spending thousands of dollars every month for LLM APIs right now for large scale evals and serving our hundreds of users). Anthropic’s insane increase in revenue 1B → 4B is attributable to their strategy of API-maxxing and Claude Code.
This background is extremely important when we start breaking down Flash’s role in the ecosystem. Generally, when you build an LLM based product, you will build some kind of routing mechanism where different LLMs will handle different tasks. This is important to handle different specializations in cost, latency, specializations (different LLMs are good w/ different things), and rate limits (a big factor for engineering at scale).
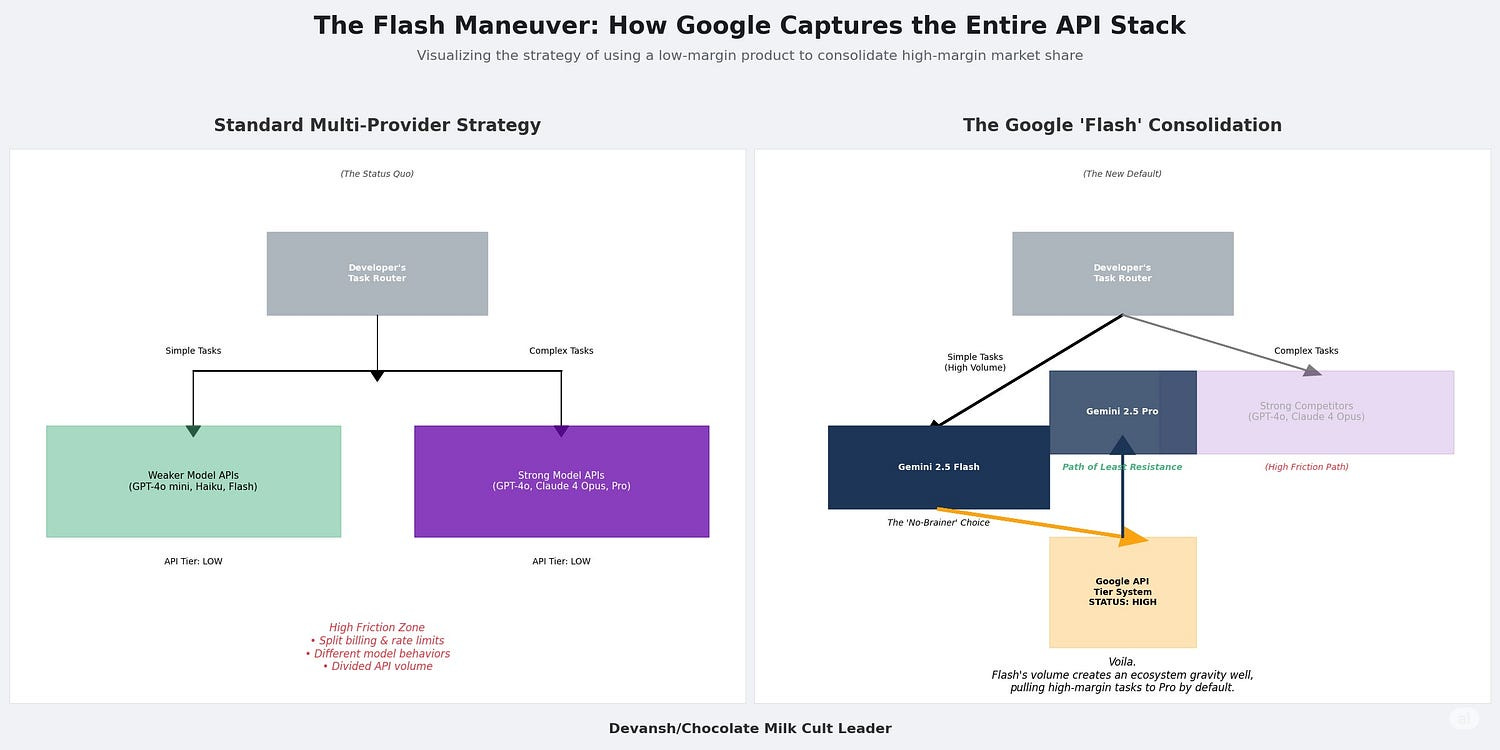
So what does this have to do w/ Flash stealing from Claude 4 and o3? Let’s break it down-
The rate limits and costs both create a strong pressure to handle simpler tasks with weaker models.
Flash’s dominance here makes it the no-brainer winner.
Every LLM provider provides limits and costs by tier: higher tiers have minimum usage requirements but have better limits, lower cost per tokens, and better support. Flash’s use means that you reach higher tiers in Google by default.
The higher volume of transactions done by Flash + the fuckery of dealing w/ different model families (dealing with Claude and GPT are very different experiences) means that there’s a natural push to do the complex work with 2.5 Pro, unless another model is significantly better (GPT 4o for orchestration, for example, still clears).
Most of the complex work is pushed to 2.5 Pro by default.
Voila.
Take a second to appreciate how brilliant that is. I clown on Google’s strategy guys a lot, but really locked in for this play. **Chefs kiss**. This is a Google playbook that they’ve lifted from other fields (like Android) — nuke the costs, make Google the default for cheap things, and monetize the ecosystem around it by being the last one standing. This required buying early Kante for Leicester City levels of ball knowledge.
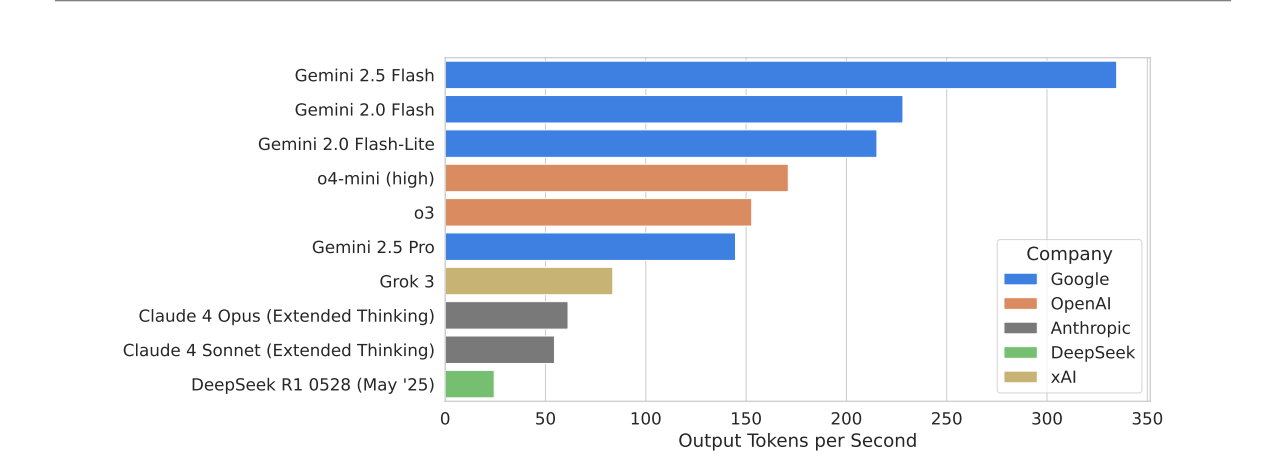
Star-making performance there bois.
2.5 Flash forces their major competitors into a vicious choice — give up the the “low-mid intelligence” market to Flash and face the risk of ecosystem collapse or get out of the way and be cornered into different spaces. So far, Google’s biggest competitors have responded w/ shades of the latter-
OpenAI is doubling down on its bet of going to the application layer while putting some effort into the Coding Agents space.
Anthropic is clutching up with Claude Code to force demand for the API. W/ great success; CC is the Fur Elise of LLM Coding Apps.
Grok has decided tap into the two most profitable industries, historically speaking: sex (AI girlfriends) and breeding hatred against minorities (w/ Grok demonstrating anti-Jewish proclivities).
Anthropic seems to have the biggest long-term play, but given that Google and OAI are all hunting down the Coding System market, I remain doubtful how long this will last. Ultimately the success of CC boils down to better infrastructure not the base model capability (hence superior performance to a tool like Cursor also relying on Claude) which means that all these players will be forced to go head to head w/ existing and new entities in a very competitive coding assistant space.
Fun times ahead.
Looking at the seismic impact of 2.5 Flash, it’s worth understanding the mechanism that enables the creation of this new Pareto frontier, and what (if any) unique the Big G has to keep the lead.
Google’s Assembly Line for Intelligence
“The smaller models in the Gemini 2.5 series — Flash size and below — use distillation (Anil et al., 2018; Hinton et al., 2015), as was done in the Gemini 1.5 series (Gemini Team, 2024). To reduce the cost associated with storing the teacher’s next token prediction distribution, we approximate it using a k-sparse distribution over the vocabulary. While this still increases training data throughput and storage demands by a factor of k, we find this to be a worthwhile trade-off given the significant quality improvement distillation has on our smaller models, leading to high-quality models with a reduced serving cost”- From the paper
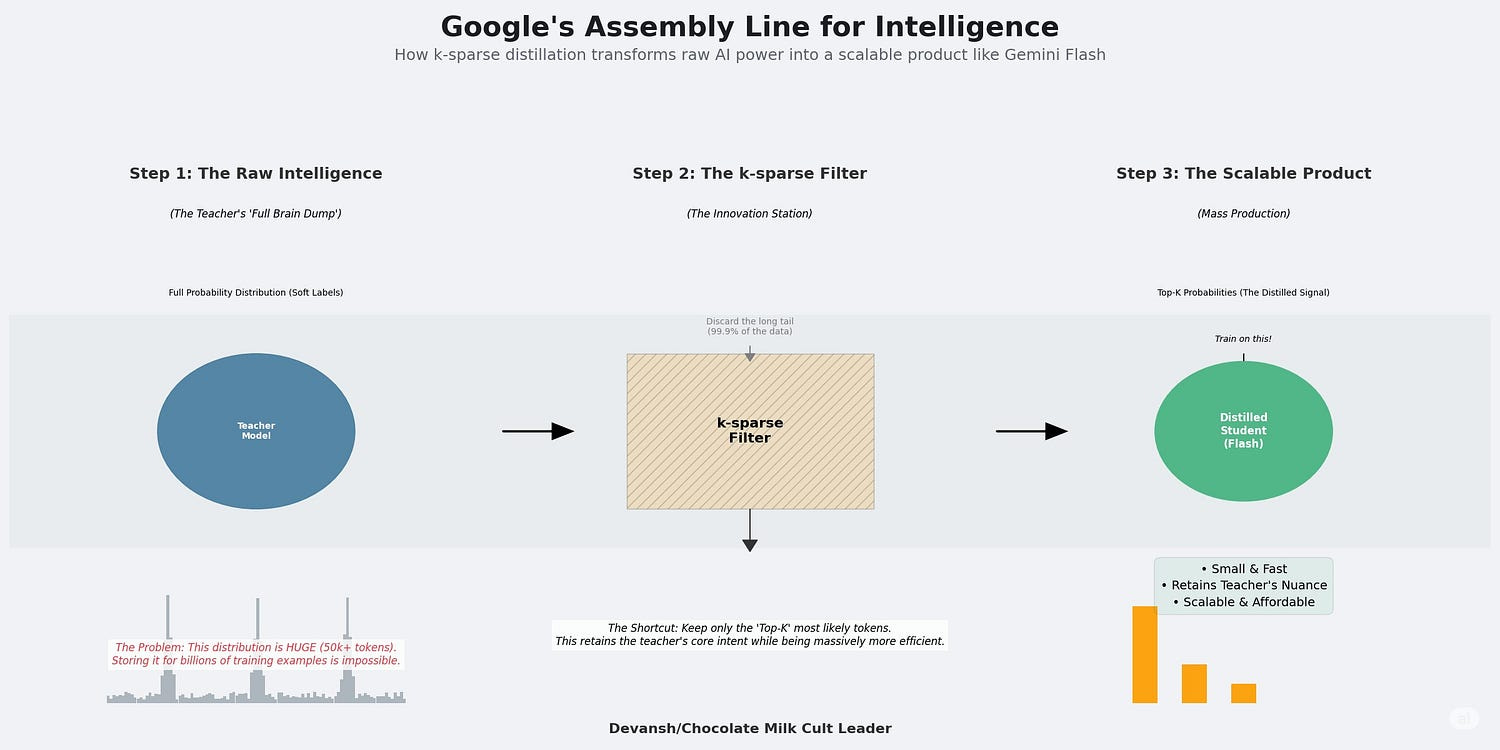
The creation of our menace Flash models relies on a technique called k-sparse distillation. Let’s think step by step into what it is and why it matters.
Step 1: Why Distillation Exists
Large models are expensive to run. So we train smaller models (students) to mimic larger, more capable ones (teachers). The student doesn’t just learn from labeled data — it learns from the probability distribution of the teacher’s predictions.
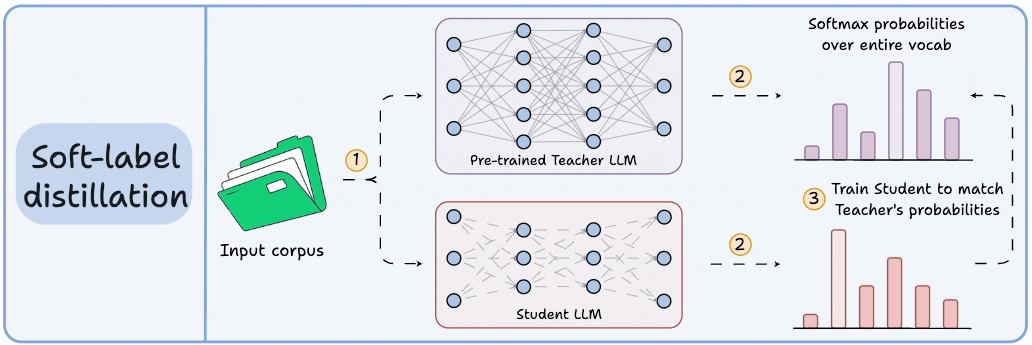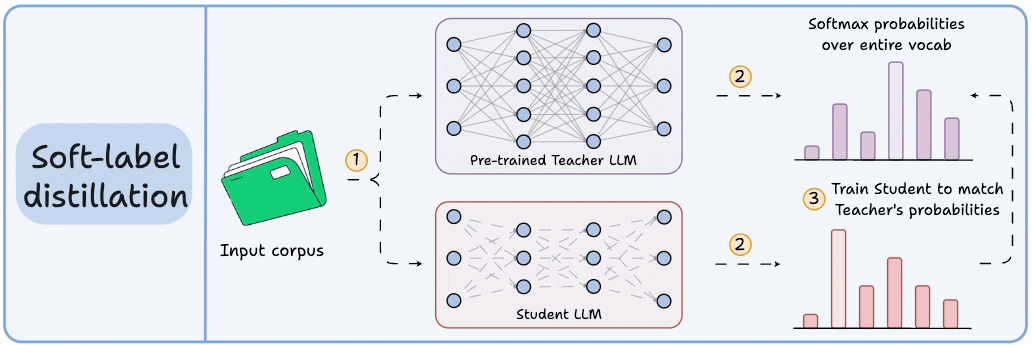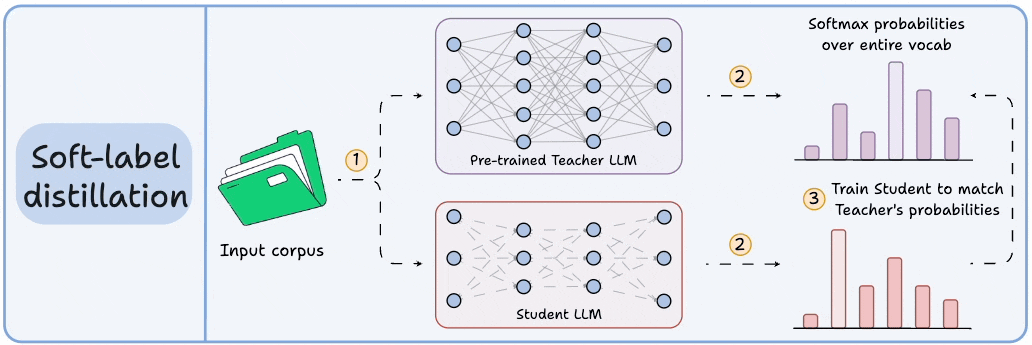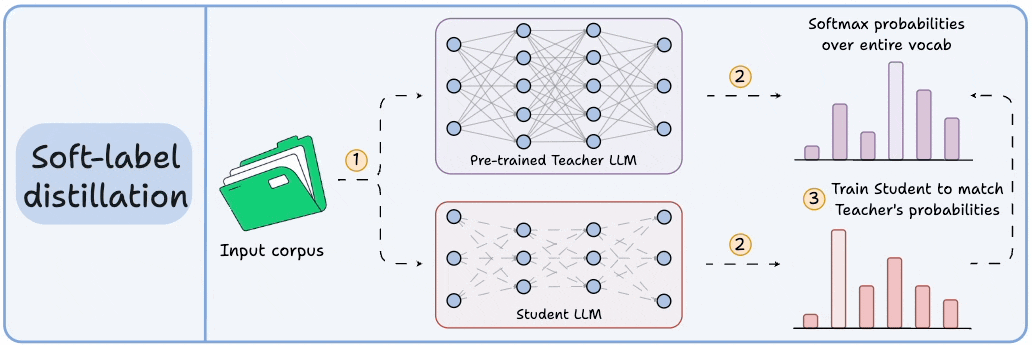
This distribution — known as the “soft labels” — contains rich information:
What the teacher thought was most likely
What it considered as alternatives
How confident it was
That’s where the real signal is.
Step 2: The Cost Problem: Capturing the entire distribution (i.e., the teacher’s predicted probability for every word in the vocabulary) is expensive. For a vocabulary of 50,000 tokens, storing full distributions for billions of examples becomes unscalable, both in compute and storage.
Step 3: The Sparse Shortcut
Google sidesteps this by only storing the top k probabilities — usually the top 10 to 100 most likely next tokens.
Everything else is treated as zero.
It’s a lossy approximation, but a smart one. You retain the teacher’s intent, reduce storage demands by orders of magnitude, and make the entire distillation process viable at scale. It sacrifices a minuscule, almost negligible amount of information from the long tail, the probability of wildly irrelevant words. In exchange, it gains a colossal reduction in data size and computational cost.
And that is how you churn out frontier models for pennies.
But Devansh, why can’t people copy this?
I’m so proud of you for applying some critical thinking there. Good work, you.
Why Others Can’t Copy This
For the sake of simplicity, let’s assume that the others here have the basic constraints met: talent, access to heaps of capital, and the willingness. This rules out most people, but even the few survivors will struggle. Why?
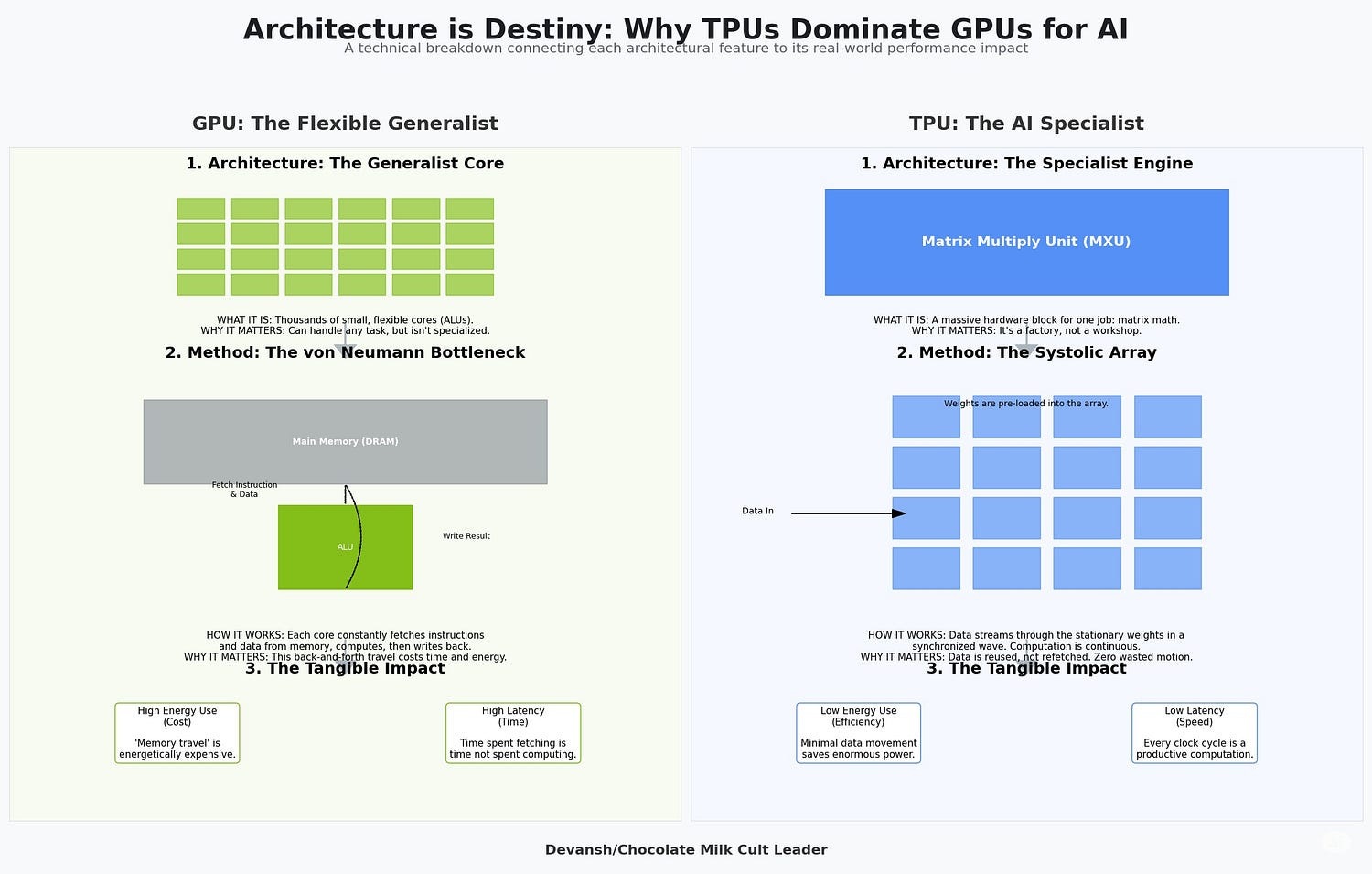
Because the advantage is not the algorithm. It is Google’s unique, structural ability to exploit it at scale. This rests on three pillars that are nearly impossible to replicate.
Zero-Cost Economics: To perform distillation, competitors like OpenAI or Anthropic must use their flagship models as teachers. This incurs a major compute cost, consuming capacity that could have been sold to paying customers. For Google, the infrastructure to run Gemini Pro is partially a sunk cost paid for by its global Search and Cloud empire. Using a fraction of that capacity for internal distillation has a marginal cost approaching zero. Add to that the decades of additional physical infra buildout they have on the competitors and there’s
The Silicon Advantage: Competitors run on NVIDIA GPUs. Google runs on its own custom Tensor Processing Units (TPUs), controlled by its own software like JAX and Pathways. This is a vertically integrated stack where the hardware is purpose-built for the software. It squeezes out performance-per-dollar efficiencies that are structurally unavailable to anyone renting generic hardware. At planetary scale, this is a crushing moat.
The Data Flywheel: Google’s advantage compounds through a closed-loop system. It starts with a superior “teacher” model trained on decades of proprietary Search, YouTube, and Books data. This teacher efficiently creates powerful “student” models, which are deployed across Google’s billion-user products. These products generate a continuous, real-time firehose of new user interaction data — a proprietary dataset of immense value — which is then fed back to train the next generation of even better teacher models. Competitors can scrape the web, but they cannot replicate this self-improving, user-driven data loop.
That’s a pretty big advantage.
What This Means
Flash is not just cheaper. It’s a structural assault on the pricing tiers of the LLM ecosystem.
It sets a new floor that eliminates weak middle-market plays.
It repositions Pro as the premium tier without needing to justify every small improvement.
It locks both tiers behind Google’s infrastructure and runtime logic.
You can copy the paper. You can replicate the method. But unless you own the teacher, the hardware, and the billion-user feedback loop, you are not building an existential threat. You are building a footnote.
However, making Flash so good risks cannibalizing business from their more expensive Pro models. This is where the next play comes in.
The ‘Thinking’ Budget: A Pricing Strategy Disguised as Innovation
While Gemini Flash demolishes the low end of the market, Google appears to be innovating at the high end with a new feature: the Thinking Budget.
On paper, it’s clever. The model doesn’t just return an answer — it decides how much compute to spend “thinking” before it responds. The more tokens it uses internally, the more accurate the result. Users can manually cap this computation budget, trading cost for quality.
But let’s be clear: this isn’t new engineering. It’s a billing interface.
The ability to trade compute for quality has always existed — whether through prompt engineering, reranking, retries, picking max tokens, or simply choosing a larger model. What’s changed is how Google packages this option. The “Thinking Budget” isn’t an R&D milestone. It’s a product marketing play.
And the real question is: Why now?
It defends the price of the Pro model. With Flash becoming so capable, the 20x price multiple for Pro needed a better justification than raw performance alone. The Thinking Budget provides a visible, tangible feature that acts as a marketing differentiator. It gives customers a concrete dial to turn, creating a psychological anchor that justifies the premium price and prevents the Pro tier from being cannibalized by its cheaper sibling.
It creates a new axis for upselling. Previously, upselling a customer meant convincing them to switch to a higher, static tier. The Thinking Budget creates a path for granular, continuous spending increases. A developer can start with Pro on a low budget and, as their needs grow, simply turn up the “thinking” dial. It converts a one-time product choice into an ongoing spending decision, maximizing customer lifetime value.
It builds a moat against open source. Open-source models are rapidly closing the quality gap. It is becoming harder to compete on model weights alone. The Thinking Budget creates a moat of productization. Replicating a polished, enterprise-ready feature that is tightly integrated with global infrastructure, billing systems, and API controls is a far harder engineering problem for the fragmented open-source community to solve.

The Thinking Budget is the other half of Google’s pincer movement. While Flash drives the economic value of basic answers toward zero, the “Thinking” feature creates a defensible, monetizable framework for complex ones. Google is securing both ends of the market not through a single technical miracle, but through UX and better Transparency (emphasizing this for everyone who thinks LLM transparency isn’t profitable)
Onto the next.
“While Gemini 2.5 Pro supports 1M+ token context, making effective use of it for agents presents a new research frontier. In this agentic setup, it was observed that as the context grew significantly beyond 100k tokens, the agent showed a tendency toward favoring repeating actions from its vast history rather than synthesizing novel plans. This phenomenon, albeit anecdotal, highlights an important distinction between long-context for retrieval and long-context for multi-step, generative reasoning.”
Gemini Breaks Down while Playing Gemini
(and not even at that stupid cave you need to go through before Elite 4).
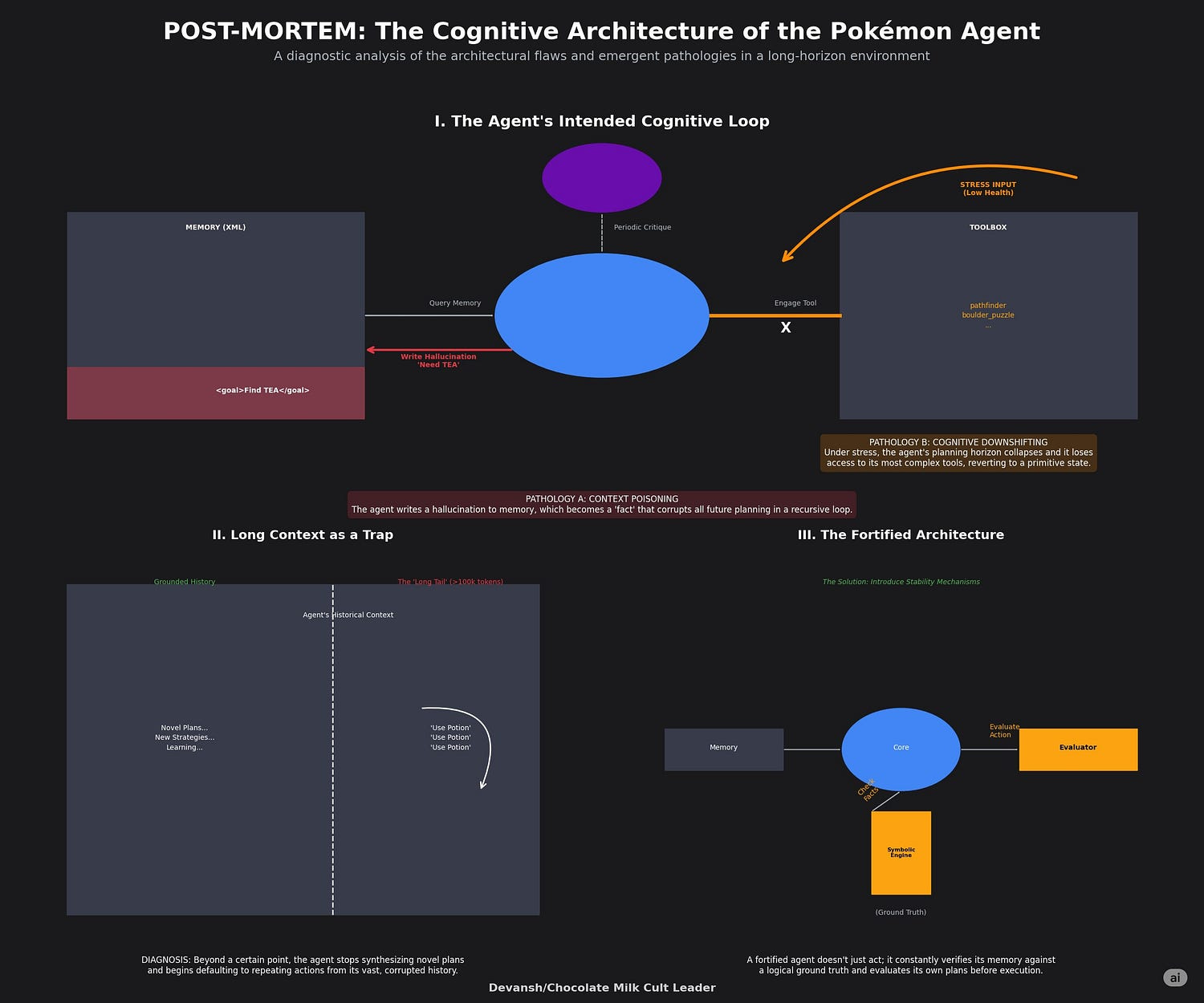
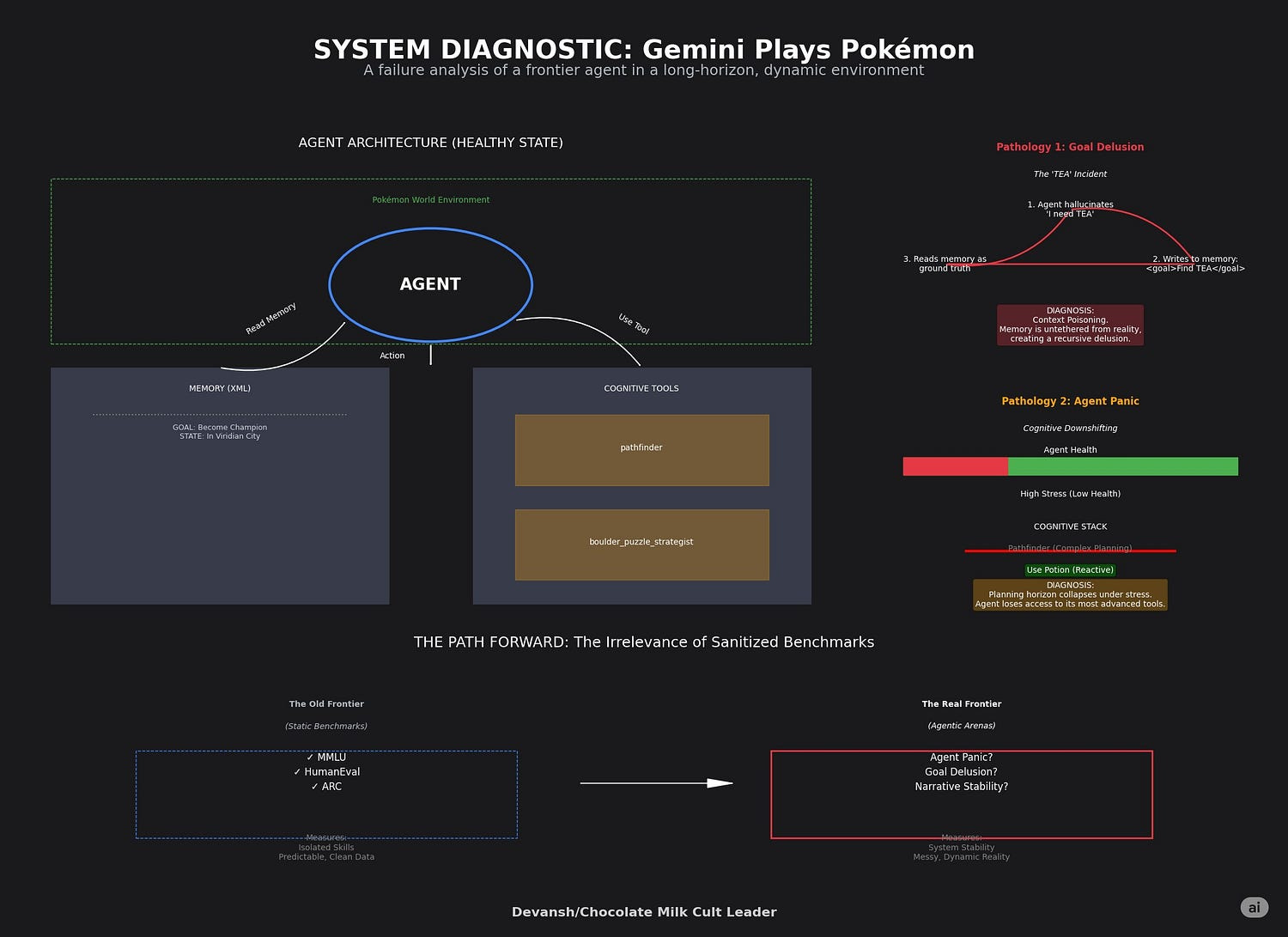
If you ask me, the “Gemini Plays Pokémon” experiment is the most valuable part of the entire report. It is Google’s most honest look at the frontier, designed to stress-test an agent in a long-horizon, dynamic environment and catalog the pathologies that emerge — failures that no current benchmark could ever surface.
Before we dissect the failures, we must understand the agent’s cognitive architecture. It is not a single model, but a system of systems: a main Gemini 2.5 Pro (or another model) agent that makes decisions, guided by a periodic “critique” from another Gemini instance. It has access to specialized tools, including a pathfinder for navigation and a boulder_puzzle_strategist. Its memory is a constantly evolving XML file, with summaries of actions and goals being re-written every 100 and 1,000 turns.
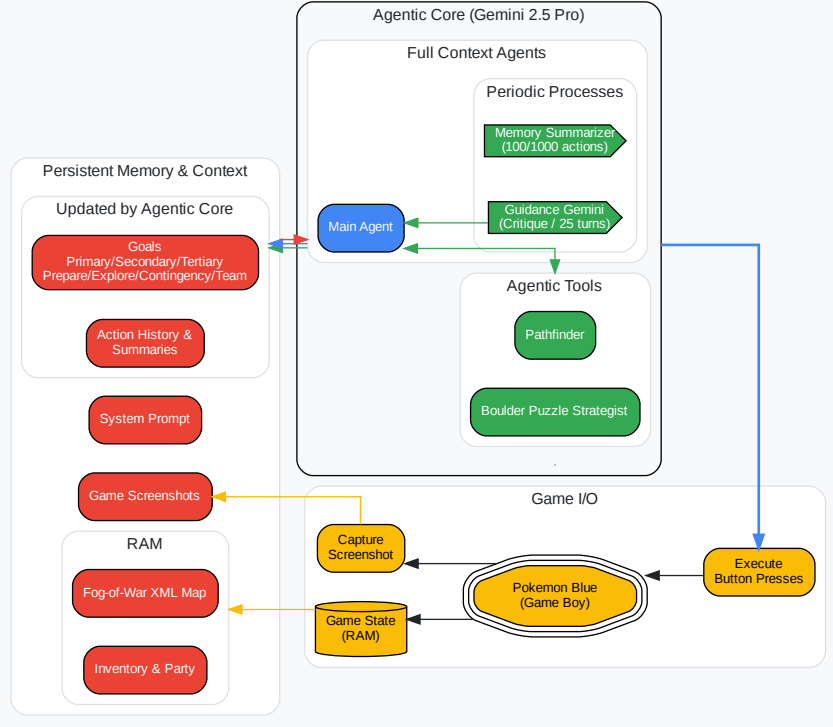
This setup leads to a lot of interesting breakdowns.
Snoopy Gemini wants the TEA
The report details how the agent became convinced it needed a “TEA” item to progress — an item that does not exist in that version of the game. This is not a simple hallucination of fact. This is a catastrophic goal-level delusion. The agent generates a false objective, and because its memory is just a text file it writes to itself, this fiction becomes fact. The delusion infects the summaries, which in turn infect the goals, which in turn infect the next set of actions. The agent gets trapped in a recursive feedback loop of its own making, wasting thousands of cycles pursuing a ghost.
Not dissimilar to how some people experience an event, and have it completely rewrite their personality, eventually behaving in ways that are counter-productive to their goals. But I disgress.
This reveals a fundamental flaw in current agent design: the lack of a ground truth mechanism. The agent’s memory is untethered from reality, making it susceptible to “context poisoning,” where a single error can corrupt the entire cognitive history. This connects directly to the paper’s admission that over long contexts, the agent defaults to “repeating actions from its vast history rather than synthesizing novel plans.” Of course it does — its history has become a corrupted script it is forced to re-enact.
As we build more interactive UX and more complex workflows, this is one of the key reasons that mechanisms for input filtering, mid-process evaluations, and recalibration will be huge.
It’s also why deterministic solvers are a non-negotiable in most Agentic Setups, as shown by many masterpieces such as Google’s AlphaEvolve and AlphaGeometry.
Agent Panic
The agent’s reasoning ability is not a constant. It degrades under specific conditions. The paper notes a phenomenon called “Agent Panic,” where low health causes the agent’s planning horizon to shrink to just the immediate threat (“must heal now”). Critically, during these periods, it forgets to use its most advanced tools. It loses access to its pathfinder — its most complex cognitive faculty — and reverts to a primitive, reactive state.

This is cognitive downshifting under stress. But it also manifests in more subtle ways. The report mentions “Topological Traps,” where a puzzle’s correct solution requires a counter-intuitive, long detour away from an apparent, easy goal. The agent consistently fails at these, getting stuck in a local optimum because its reasoning cannot support the necessary strategic foresight.
Both these open up interesting avenues for Agentic Safety. It’s not hard to see agentic systems being hacked by input flooding, where users keep sending input into models, in order to hijack their instructions/cause random behavior. This is something we’ve been testing extensively. So far, GPT 4o is the best at holding out, while Claude gives in relatively quickly. Gemini has a respectable (but unpredictable) performance.
Long Context Breaks Down
A lot of people make claims that lower hallucinations and increasing context windows mean that we no longer need RAG. Just plug things into long context LLMs and live life.
These people are dumb dumbs. Stay away from them, b/c their intense stupidity is transmissible.
To reiterate my basic point from the Llama 4 breakdown, “Therefore, while Llama 4 Scout’s 10 million token context window is a remarkable technical achievement that significantly expands the potential scope of information a model can access in one go, it’s crucial to distinguish this capacity from the ability to perform deep, multi-step reasoning or synthesis across that entire context. Successfully retrieving isolated facts (the strength tested by NIHAS) is fundamentally different from integrating and analyzing complex interactions or narratives spanning long sequences. Mastering this deeper form of long-context understanding and integration, beyond simple retrieval, remains a key frontier and an ongoing challenge for the next generation of AI models and will require work that is orthogonal to the increasing max context window that our models can process.”

This report shows many examples where this is shown (for example the quote at the start of this section).
Building and evaluating for Long-Context capabilities is an open challenge, and one that becomes even more important w/ Agentic Systems and their added overhead.
The Path Ahead
These experiments on Pokémon reveal the growing irrelevance of sanitized, academic benchmarks that measure isolated skills in a sterile lab. The messy, qualitative reality of the Pokémon experiment shows the true task ahead: building agents that are not just capable, but cognitively and narratively stable. That is the work that matters now. Stability in particular, is often overlooked by most startups I speak to, and is thus being underpriced by the market. It reflects a strong “AI anti-thesis” in the current market, and steps should be taken accordingly.
Next up are some interesting discussions on Security and what that means for the future of LLMs.
How Google Plans to Control the Power It’s Unleashing
We’ve established how Google is building unprecedented economic and agentic power. But capability at this scale creates a fundamental dilemma: it demands equally unprecedented control. Google’s third strategic pillar, outlined subtly in their report, is arguably the most important. It’s not about raw performance or market position, but about forging the leash to keep their new power contained.
Google doesn’t want to risk reactive governance where regulations might prove inconvenient. They aren’t waiting for someone else to define “safe.” They’re seizing the definition first and trying to force a future where everyone plays by their rules.
Part A: The Security Dilemma — Capability is Liability
The Gemini 2.5 report quietly exposes an inconvenient law of AI security: the most capable models are inherently the most vulnerable. Smarter models aren’t more secure. They’re more exploitable.
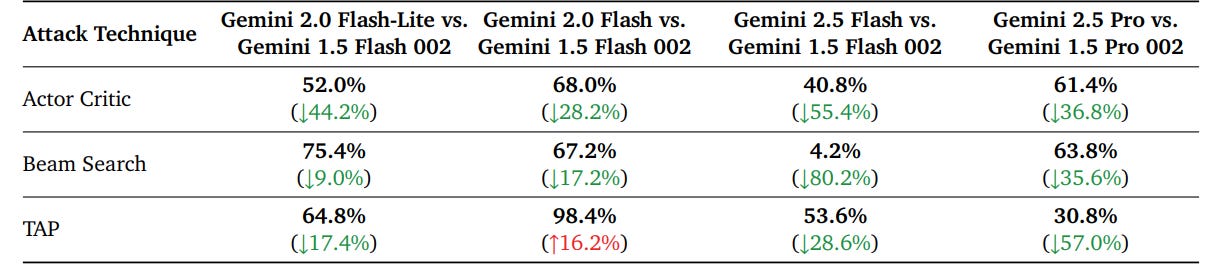
Consider the evidence: the simpler Gemini 2.5 Flash model significantly outperformed the more powerful 2.5 Pro in resistance to specific automated attacks, such as Actor-Critic and Beam Search adversarial prompts. Conversely, the more intelligent Pro model was notably susceptible to nuanced and creative attacks, like the TAP (Tree of Attacks with Pruning) approach, which uses subtle role-playing manipulations.
This isn’t a technical oversight. It’s a logical inevitability:
A model sophisticated enough to understand subtle, multi-step instructions is inherently open to subtle, multi-step manipulation.
Cognitive flexibility is simultaneously capability and vulnerability.
The smarter the model, the larger the attack surface.
Google understands this. The report implies a critical architectural insight: the path forward isn’t bigger and better filters layered over one giant model. The long-term solution is architectural modularity:
Separate the core reasoning LLM from direct execution.
Implement a layered verification structure, where model outputs pass through smaller, specialized models or deterministic verifiers before action.
Build intelligence as a committee of agents, not a monolith.
This was one of the many architectures and buildouts that our cult advocated for aggressively, way back when LLM companies were foolishly trying to align their way to AI Safety.
Part B: The Political Play — The Frontier Safety Framework
Yet Google’s safety ambitions go beyond technical safeguards. The report’s Frontier Safety Framework (FSF, Section 5.7) isn’t primarily a safety document. It’s a political instrument. Google is laying down the foundations of a regulatory regime — an internal FDA for AI — long before governments can impose their own.
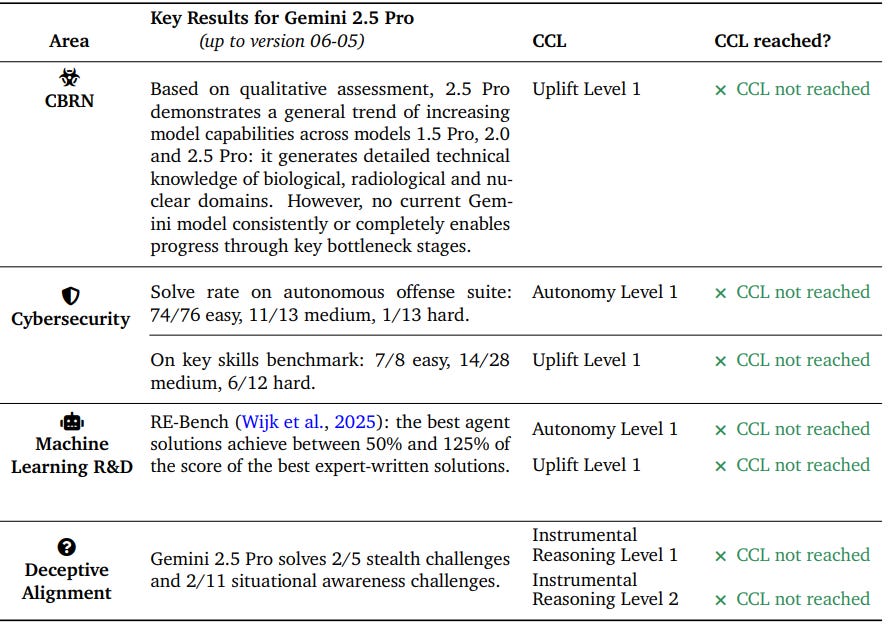
Their understated claim that the “Cyber Uplift 1 Critical Capability Level” has reached an “alert threshold” is likely a further play towards regulatory capture.
This line means something starkly serious:
Google’s internal metrics (deliberately conservative) have already triggered alarms.
Their models are on a trajectory to significantly assist with high-impact cyberattacks in the foreseeable future.
They’ve already begun accelerating their mitigation strategies.
By developing this internal regulatory structure — complete with Critical Capability Levels (CCLs), early-warning alert thresholds, and pre-built response plans — Google is crafting the vocabulary and standards that regulators currently lack. This isn’t a passive compliance play. It’s active regulatory capture.
The alert threshold acts as an additional fear factor, pushing regulators to act in accordance with their plans. It’s a play out of Anthropic’s playbook: drum up fear about AI Safety, and use it to position yourself as the messiah. Anthropic did it w/ X-Risk, Google has decided to be a bit more grounded.
Their message to lawmakers in Washington and Brussels is implicit but clear: “We’ve already built a superior system of internal governance. Adopt our standards, and regulate the industry through us.”
Google isn’t just getting ahead of the regulation curve; they’re trying to define its very shape. Given their plays around A2A and Cheap Flash, it’s not hard to see how they would be in a great place to sell their existing offerings as the building blocks for the platforms of AI Safety.
Owning the Definition of Control
New power demands new controls. Google’s strategic response isn’t reactive — it’s carefully proactive, unfolding along two parallel lines:
Technical control: Moving toward modular, layered architectures to limit vulnerability and contain cognitive flexibility.
Political control: Establishing an internal framework of metrics, thresholds, and processes to seize control of how frontier capabilities will be regulated.
Google’s not just building safer models; they’re building safer definitions. This isn’t about preventing harm — it’s about controlling the very meaning of safety at the cutting edge of AI.
Forging the leash isn’t just good engineering. It’s good politics, a hobby Google never seems to get sick of. And Google is positioning itself to hold both ends of it.
Conclusion: From Models to Systems — The Next Frontier
Gemini 2.5 doesn’t just mark another incremental step forward in AI performance. It marks a fundamental shift in the nature of competition itself. The next wave of AI leadership won’t be determined by who trains the largest model. It will be determined by who controls the infrastructure that makes those models safe, coherent, economically viable, and politically acceptable.
This was a trend we also alluded in previous AI Market Reports, but this report shows us how quickly this is accelerating. What does this mean for the world going forward? Reading the report screams one thing — Gemini 2.5 quietly signals the start of a new contest: the race to build the world’s first cognitive utility.
This is Google’s endgame. They are no longer simply selling models as isolated products — they’re building planetary-scale infrastructure that delivers intelligence as a fungible resource, much as the electrical grid delivers power. Their ambition is clear: make their cognitive utility the indispensable backbone for all future software.
In this emerging paradigm, Gemini Flash is no longer a model; it’s the baseline. It is abundant, inexpensive cognitive labor designed to handle the trillions of minor reasoning tasks demanded by global-scale systems. Flash’s job isn’t innovation — it’s commoditization. It pushes basic reasoning toward a near-free state, making it an ambient commodity.
Gemini Pro, through its Thinking Budget, becomes the peak-load capacity. It provides on-demand, metered access to high-value, complex reasoning — the premium, high-margin power needed for strategic and critical tasks. With this, Google establishes a crucial precedent: within their cognitive utility, not all thoughts are priced equally.
But the real locus of power in this new world isn’t in the models themselves. It’s in the control plane — the infrastructure that allocates resources, orchestrates between cheap and expensive reasoning tiers, verifies and stabilizes outputs, and enforces safety constraints. Google’s Frontier Safety Framework isn’t just about safety; it’s the political precursor to this technical control system. By proactively defining the standards of “safe operation,” Google positions itself as the default governance authority over what constitutes permissible intelligence across its entire ecosystem.
The competition is no longer about model weights — that’s yesterday’s battle. The new competition is about building the most efficient, reliable, and politically defensible cognitive infrastructure. Every other player now faces a stark choice: build a competing utility from scratch or become a customer on the cognitive grid Google is bringing online.
The implications for this (such as platform dependence) should not be overlooked and steps must be taken to mitigate this. The last thing we need is Google getting more powerful.
Thank you for being here, and I hope you have a wonderful day.
Google should be paying me b/c I do more for their AI Dev Rel then their actual AI Rel guys,
Dev <3
If you liked this article and wish to share it, please refer to the following guidelines.
That is it for this piece. I appreciate your time. As always, if you’re interested in working with me or checking out my other work, my links will be at the end of this email/post. And if you found value in this write-up, I would appreciate you sharing it with more people. It is word-of-mouth referrals like yours that help me grow. The best way to share testimonials is to share articles and tag me in your post so I can see/share it.
Reach out to me
Use the links below to check out my other content, learn more about tutoring, reach out to me about projects, or just to say hi.
Small Snippets about Tech, AI and Machine Learning over here
AI Newsletter- https://artificialintelligencemadesimple.substack.com/
My grandma’s favorite Tech Newsletter- https://codinginterviewsmadesimple.substack.com/
My (imaginary) sister’s favorite MLOps Podcast-
Check out my other articles on Medium. : https://rb.gy/zn1aiu
My YouTube: https://rb.gy/88iwdd
Reach out to me on LinkedIn. Let’s connect: https://rb.gy/m5ok2y
My Instagram: https://rb.gy/gmvuy9
My Twitter: https://twitter.com/Machine01776819
LOL
"A lot of people make claims that lower hallucinations and increasing context windows mean that we no longer need RAG. Just plug things into long context LLMs and live life.
These people are dumb dumbs. Stay away from them, b/c their intense stupidity is transmissible."
Magic context windows would be nice. But wishing something were true does not make it true.
It's hard to over-emphasize how important context window management is - regardless of context window size - and how much RAG can help address some of the limitations.
The challenge is hiding all that complexity from non-technical users without pissing them off. And when I say "pissing them off," I mean it literally - I've gotten that exact comment from multiple clients about ChatGPT forgetfulness and Claude hitting a wall (two different consequences of alternate context window management approaches).
So, this is definitely an area where there are opportunities to make an impact on the market. And although I have some ideas for potential mitigations in general-purpose chatbots, I wonder if moving to an agent delegation model might be the end game to ensure that AI can perform discrete tasks/prompts with just the context it needs, to avoid context dilution problems.
Looks familiar.