

Does Google AI's new TSMixer live up to the hype [Breakdowns]
Does Google AI's new TSMixer live up to the hype [Breakdowns]
Can combining components from different architectures lead to the next frontier of TSF work.

Hey, it’s Devansh 👋👋
In my series Breakdowns, I go through complicated literature on Machine Learning to extract the most valuable insights. Expect concise, jargon-free, but still useful analysis aimed at helping you understand the intricacies of Cutting-Edge AI Research and the applications of Deep Learning at the highest level.
If you’d like to support my writing, consider becoming a premium subscriber to my sister publication Tech Made Simple to support my crippling chocolate milk addiction. Use the button below for a lifetime 50% discount (5 USD/month, or 50 USD/year).
p.s. you can learn more about the paid plan here.
PS- I’m only in Denver, CO for another month-1.5 months. If any of you are in the area and would like to meet up, shoot me a message/reply to this email. My social are at the end of this article.
Among all the recent developments in AI, there was one publication that gained some attention from people. In a recent blog post+paper, researchers from Google introduced a new architecture. According to their blog TSMixer: An all-MLP architecture for time series forecasting (and paper with the same name), “Time-Series Mixer (TSMixer), an advanced multivariate model that leverages linear model characteristics and performs well on long-term forecasting benchmarks. To the best of our knowledge, TSMixer is the first multivariate model that performs as well as state-of-the-art univariate models on long-term forecasting benchmarks, where we show that cross-variate information is less beneficial.”
In this article, I will be going over their publications to break down the problem that TSMixer attempts to solve, how this architecture is created, and how it holds up against architectures. I’m personally interested in this model's ability to take multiple types of information and factor that into inference. If it works, it will enable a new degree of performance in various high-impact fields like health and finance.
A note about this paper and the results
Before we get into the deets about the paper, there is just one disclaimer I wanted to cover. The researchers compare TSMixer to various Transformer models (which lose to TSMixer). This is a bit weird, since Transformers have never been great for TSF to begin with. This is a bit like claiming that the team you support will win the Premier League because they beat Man United or Chelsea. Brand value makes beating them sound exciting, until you realize that it is now basically a canon event. Think I’m exaggerating? Here is what the researchers of whether Transformers are useful for Time Series Forecasting had to say-
We introduce an embarrassingly simple linear model DLinear as a DMS forecasting baseline for comparison. Our results show that DLinear outperforms existing Transformer-based solutions on nine widely-used benchmarks in most cases, often by a large margin
I’m also not intimately familiar with all the research in TSF, so I can’t tell you whether the performance of TSMixer is worth getting hot and bothered about. But the ideas behind the architecture seemed interesting enough to at least talk about it. I would love to hear more from those of you that are more into Time Series Forecasting about how excited you are about the numbers hit by TSMixer. Is this as revolutionary as some people claim, does it have potential to be useful for the future, or is this just hype? I’d love to hear your thoughts.

With that out of the way, let’s start by answering a simple but important question- Why do Univariate Models wreck complex deep learning based multi-variate models?
Why univariate models beat multivariate models
This is one of the most interesting questions in Time Series Forecasting. It’s natural to assume that multivariate models should be more effective than univariate models due to their ability to leverage cross-variate information (more variables → greater depth of insights->better predictions). However, Transformer-based models can have been shown to be significantly worse than simple univariate temporal linear models on many commonly used forecasting benchmarks. The multivariate models seem to suffer from overfitting especially when the target time series is not correlated with other covariates (as an interesting tangent, we see something similar in deep learning for tabular data- trees beat deep learning because Deep Learning models tend to be influenced by unrelated/uninformative features).
This weakness of multivariate models leads to two interesting questions-
Does cross-variate information truly provide a benefit for time series forecasting?
When cross-variate information is not beneficial, can multivariate models still perform as well as univariate models?
The second is especially important when we consider that certain important forecasting use cases require handling very chaotic high-dimensional data. For example, I did a bit of supply chain risk forecasting. Here we had to rely on data from economic and social indicators to forecast safety risk. We had to do a lot of trial and error to identify useful indicators (and the inherent volatility of this meant that data drift was a killer). Models that are robust to uninformative cross-variates are more robust to the volatility- allowing for a more stable deployment (making everyone’s lives much easier).

When it comes to Transformers specifically, there is another flaw that holds them back in Time Series Forecasting. Turns out Multi-Headed Self Attention turns from a blessing to a curse in TSF.
“More importantly, the main working power of the Transformer architecture is from its multi-head self-attention mechanism, which has a remarkable capability of extracting semantic correlations between paired elements in a long sequence (e.g., words in texts or 2D patches in images), and this procedure is permutation-invariant, i.e., regardless of the order. However, for time series analysis, we are mainly interested in modeling the temporal dynamics among a continuous set of points, wherein the order itself often plays the most crucial role.”
- Are Transformers effective for Time Series Forecasting
That does not look good for Transformers. So, what does do TSMixer to adapt to this?
TSMixer Architecture
In a nutshell, the authors describe the design philosophy for TSMixer as follows:
In our analysis, we show that under common assumptions of temporal patterns, linear models have naïve solutions to perfectly recover the time series or place bounds on the error, which means they are great solutions for learning static temporal patterns of univariate time series more effectively. In contrast, it is non-trivial to find similar solutions for attention mechanisms, as the weights applied to each time step are dynamic. Consequently, we develop a new architecture by replacing Transformer attention layers with linear layers. The resulting TSMixer model, which is similar to the computer vision MLP-Mixer method, alternates between applications of the multi-layer perceptron in different directions, which we call time-mixing and feature-mixing, respectively. The TSMixer architecture efficiently captures both temporal patterns and cross-variate information
Let’s investigate their changes in more detail. Turns out that, “their time-step-dependent characteristics render temporal linear models great candidates for learning temporal patterns under common assumptions.” So, the creators of TSMixer decide to beef up linear models with two cool steps-
Stacking temporal linear models with non-linearities (TMix-Only)- Nonlinearities are the secret to why Deep Learning Models can act as universal functional approximators, so this enables better modeling of complex relationships.
Introducing cross-variate feed-forward layers (TSMixer)- To work with cross-variate information. Cue the Joe Rogan reactions.
Visually speaking, the TSMixer Architecture looks like this-

For a more detailed look at this bad boy-
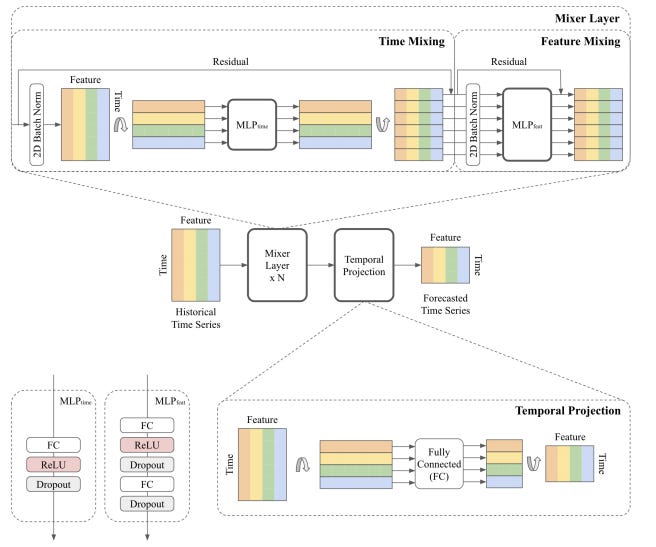
Looking at main architectural components in more detail, we have-
Time-mixing MLP: Time-mixing MLPs model temporal patterns in time series. They consist of a fully connected layer followed by an activation function and dropout. They transpose the input to apply the fully-connected layers along the time domain and shared by features. We employ a single-layer MLP, as demonstrated in Sec.3, where a simple linear model already proves to be a strong model for learning complex temporal patterns.
Feature-mixing MLP: Feature-mixing MLPs are shared by time steps and serve to leverage covariate information. Similar to Transformer-based models, we consider two-layer MLPs to learn complex feature transformations.
Temporal Projection: Temporal projection, identical to the linear models in Zeng et al. (2023), is a fully-connected layer applied on time domain. They not only learn the temporal patterns but also map the time series from the original input length L to the target forecast length T.
Residual Connections: We apply residual connections between each time-mixing and feature mixing layer. These connections allow the model to learn deeper architectures more efficiently and allow the model to effectively ignore unnecessary time-mixing and feature-mixing operations.
Normalization: Normalization is a common technique to improve deep learning model training. While the preference between batch normalization and layer normalization is task-dependent, Nie et al. (2023) demonstrates the advantages of batch normalization on common time series datasets. In contrast to typical normalization applied along the feature dimension, we apply 2D normalization on both time and feature dimensions due to the presence of time-mixing and feature-mixing operations.
This architecture is relatively simple, and can be extended to incorporate auxiliary information for deeper predictive power-

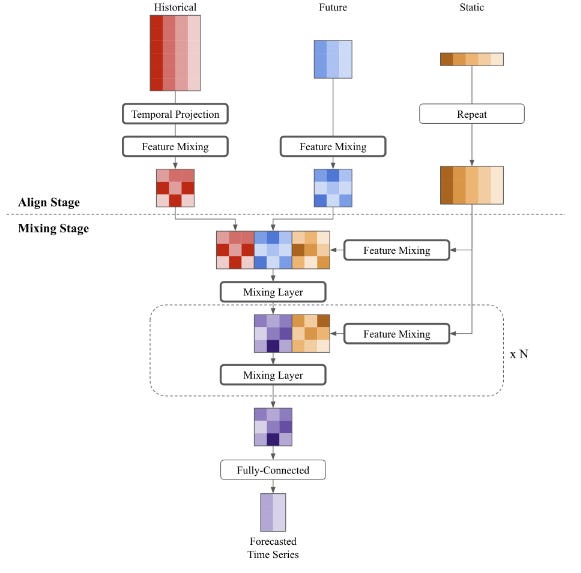
Now let’s get into the numbers to see how well TSMixer does. Is it all sizzle or does all the smoke come with a meaty helping of steak?
Results
The researchers run their experiments on the following datasets-
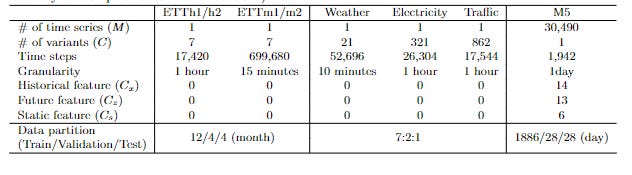
Across the experiments, we see TSMixer come in strong-
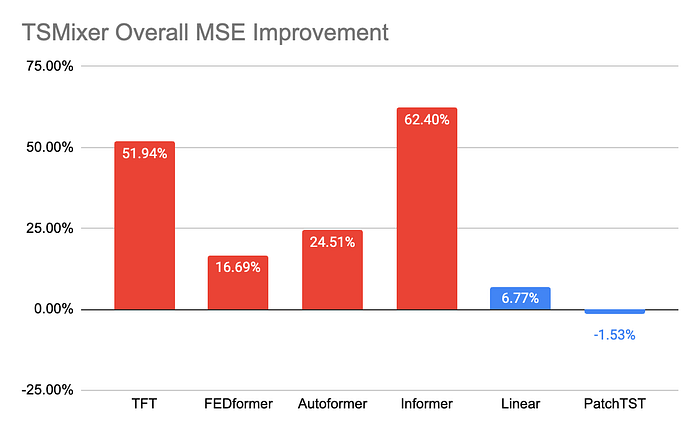
These are some impressive results. However, once again we must caveat to something here. To reiterate, beating Transformers in TSF is isomorphic to being the tallest member of the lollipop guild. The Linear Model used here seems to be taken from this paper. The authors of the paper called their model, ‘embarrassingly simple’ and the point of that paper was to show that Transformers are trash at TSF, not that this (the ‘embarrassingly simple’ model) model was good. So, I’m skeptical of these results proving much beyond TSMixer not being bad.

Just based on these results, I don’t see this being the game-changer that I saw some people describe this as. I think it gained a lot of its hype because it’s a Google publication and the people hyping it up didn’t look into the results in more detail (which would be a very LinkedIn thing to do). If you think that I’m missing something, lmk. I’m nowhere close to being an expert in TSF, so there is a chance that my noob brain has just missed something crucial.
That being said, I do appreciate the coolness of a multi-variate model holding its own against univariate models. This is a huge W for the model, and expanding upon this area of research might lead to huge upsides. As stated earlier, if we can crack a multi-variate model in TSF, we would be looking at some pretty cool improvements in AI.
Cross Promotion- Get smarter about AI, Tech, Business in less than 5 minutes with this newsletter + FREE course
AI Valley, one of the quality newsletters in AI, Tech, Business is giving out a FREE course for joining their newsletter this week. No need to pay your $ for some expensive course, this free course has got you covered.
But wait, there’s more. Not just that, they are also giving you AI Tool Tracker, and AI Funding Rounds Database with that. You’re getting ALL THIS…. and it’s not even Christmas Yet!
If you liked this article and wish to share it, please refer to the following guidelines.
That is it for this piece. I appreciate your time. As always, if you’re interested in working with me or checking out my other work, my links will be at the end of this email/post. If you like my writing, I would really appreciate an anonymous testimonial. You can drop it here. And if you found value in this write-up, I would appreciate you sharing it with more people. It is word-of-mouth referrals like yours that help me grow.

If you find AI Made Simple useful and would like to support my writing- please consider getting a premium subscription to my sister publication Tech Made Simple below. Supporting gives you access to a lot more content and enables me to continue writing. You can use the button below for a special discount for readers of AI Made Simple, which will give you a premium subscription at 50% off forever. This will cost you 400 INR (5 USD) monthly or 4000 INR (50 USD) per year.
Reach out to me
Use the links below to check out my other content, learn more about tutoring, reach out to me about projects, or just to say hi.
Small Snippets about Tech, AI and Machine Learning over here
AI Newsletter- https://artificialintelligencemadesimple.substack.com/
My grandma’s favorite Tech Newsletter- https://codinginterviewsmadesimple.substack.com/
Check out my other articles on Medium. : https://rb.gy/zn1aiu
My YouTube: https://rb.gy/88iwdd
Reach out to me on LinkedIn. Let’s connect: https://rb.gy/m5ok2y
My Instagram: https://rb.gy/gmvuy9
My Twitter: https://twitter.com/Machine01776819
Wow, your explanation of the differences between univariate and multivariate models was clear and accessible, even for someone who isn't an expert in this field. It's fascinating that even though multivariate models have access to more information, they still can't always outperform univariate models. Your explanation of the potential reasons why is very compelling, and it raises some intriguing questions. The first question you raised was about whether we can find ways to make multivariate models more effective without overfitting. The second question was about whether we should reconsider the value of univariate models, and whether there are cases where they're actually preferable.