


How does Batch Size impact your model learning[Breakdowns]
Different aspects that you care about

Hey, it’s Devansh 👋👋
In my series Breakdowns, I go through complicated literature on Machine Learning to extract the most valuable insights. Expect concise, jargon-free, but still useful analysis aimed at helping you understand the intricacies of Cutting Edge AI Research and the applications of Deep Learning at the highest level.
If you’d like to support my writing, please consider buying and rating my 1 Dollar Ebook on Amazon or becoming a premium subscriber to my sister publication Tech Made Simple using the button below.
p.s. you can learn more about the paid plan here.
Batch Size is among the important hyperparameters in Machine Learning. It is the hyperparameter that defines the number of samples to work through before updating the internal model parameters. It can one of the crucial steps to making sure your models hit peak performance. It should not be surprising that there is a lot of research into how different Batch Sizes affect aspects of your ML pipelines. This article will summarize some of the relevant research when it comes to batch sizes and supervised learning. To get a complete picture of the process, we will look at how batch size affects performance, training costs, and generalization.
Training Performance/Loss
The primary metric that we care about, Batch Size has an interesting relationship with model loss. Going with the simplest approach, let’s compare the performance of models where the only thing that changes is the batch size.

Orange curves: batch size 64
Blue curves: batch size 256
Purple curves: batch size 1024
This makes it pretty clear that increasing batch size lowers performance. But it’s not so straightforward. When we increase batch size, we should also adjust the learning rate to compensate for this. When we do this, we get the following result
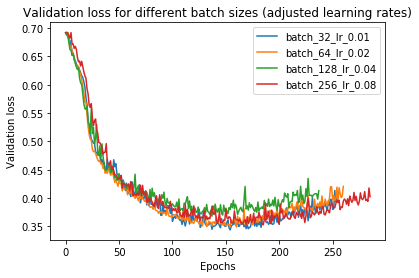
Here all the learning agents seem to have very similar results. In fact, it seems adding to the batch size reduces the validation loss. However, keep in mind that these performances are close enough that some deviation might be due to sample noise. So it’s not a good idea to read too deeply into this.
The authors of, “Don’t Decay the Learning Rate, Increase the Batch Size” add to this. They say that increasing batch size gives identical performance to the decaying learning rate (the industry standard). Following is a quote from the paper:
instead of decaying the learning rate, we increase the batch size during training. This strategy achieves near-identical model performance on the test set with the same number of training epochs but significantly fewer parameter updates. Our proposal does not require any fine-tuning as we follow pre-existing training schedules; when the learning rate drops by a factor of α, we instead increase the batch size by α
They show this hypothesis on several different network architectures with different learning rate schedules. This was a very comprehensive paper and I would suggest reading this paper. They came up with several steps that they used to severely cut down model training time without completely destroying performance.
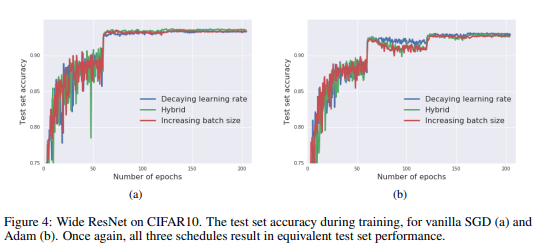
Verdict: No significant impact (as long as learning rate is adjusted accordingly).
Generalization
Generalization refers to a models ability to adapt to and perform when given new, unseen data. This is extremely important because it’s highly unlikely that your training data will have every possible kind of data distribution relevant to its application.

This is one of those areas where we see clear differences. There has been a lot of research into the difference in generalization between large and small batch training methods. The conventional wisdom states the following: increasing batch size drops the learners' ability to generalize. The authors of the paper, “On Large-Batch Training for Deep Learning: Generalization Gap and Sharp Minima”, claim that it is because Large Batch methods tend to result in models that get stuck in local minima. The idea is that smaller batches are more likely to push out local minima and find the Global Minima. If you want to read more about this paper it’s takeaways read this article.
However, it doesn’t end here. “Train longer, generalize better: closing the generalization gap in large batch training of neural networks” is a paper that attempts to tackle the generalization gap b/w the batch sizes. The authors make a simple claim:
Following this hypothesis we conducted experiments to show empirically that the “generalization gap” stems from the relatively small number of updates rather than the batch size, and can be completely eliminated by adapting the training regime used.
Here updates refers to the number of times a model is updated. This makes sense. If a model is using double the batch size, it will by definition go through the dataset with half the updates. Their paper is quite exciting for a simple reason. If we can do away with the generalization gap, without increasing the number of updates, we can save costs while seeing a great performance.

Here we see that once the authors used an adapted training regime, the large batch size learners caught up to the smaller batch sizes. They summarise their results in the following table:
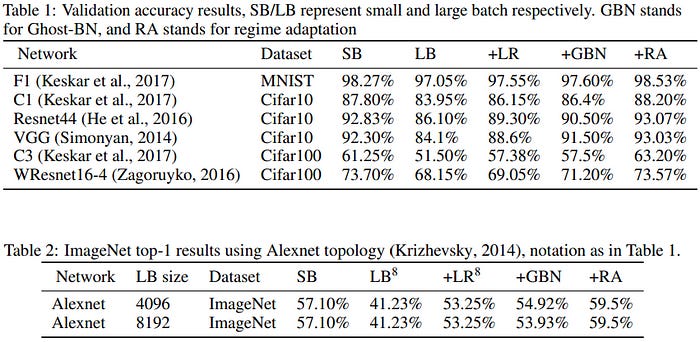
This is obviously quite exciting. If we can remove/significantly reduce the generalization gap in the methods, without increasing the costs significantly, the implications are massive. If you want a breakdown of this paper, let me know in the comments/texts. I will add this paper to my list.
Verdict: Larger Batch → Weak Generalization. But this can be fixed.
Costs
This is where the Large Batch methods flip the script. Since they require a lower number of updates, they tend to pull ahead when it comes to computing power. The authors of “Don’t Decay LR…” were able to reduce their training time to 30 minutes using this as one of their bases of optimization.
But this is not the only thing that makes a difference. In my breakdown of the phenomenal report, “Scaling TensorFlow to 300 million predictions per second”, we saw that using Larger Batch sizes enabled the team to halve their computational costs. Especially when it comes to Big Data (like the one that the team was dealing with), such factors really blow up.
So why did big training batches lead to lower computational costs? There’s a cost associated with moving batches from RAM/disk to memory. Using larger batches = less moving around of your data = less training time.
-From that breakdown
The costs side is fortunately relatively straightforward.
Verdict: Larger Batches → Fewer updates + shifting data → lower computational costs.
Closing
We see that Batch Sizes are extremely important in the model training process. This is why in most cases, you will see models trained with different batch sizes. It’s very hard to know off the bat what the perfect batch size for your needs is. However, there are some trends that you can use to save time. If costs are important, LB might be your thing. SB might help when you care about Generalization and need to throw something up quickly.
Remember that we’re only looking at supervised learning in this article. Things can change for other methods (like contrastive learning). Contrastive Learning seems to benefit a lot from larger batches + more epochs (we did the breakdown here).
That is it for this piece. I appreciate your time. As always, if you’re interested in reaching out to me or checking out my other work, links will be at the end of this email/post. If you like my writing, I would really appreciate an anonymous testimonial. You can drop it here. And if you found value in this write-up, I would appreciate you sharing it with more people. It is word-of-mouth referrals like yours that help me grow.

Reach out to me
Use the links below to check out my other content, learn more about tutoring, reach out to me about projects, or just to say hi.
Small Snippets about Tech, AI and Machine Learning over here
AI Newsletter- https://artificialintelligencemadesimple.substack.com/
My grandma’s favorite Tech Newsletter- https://codinginterviewsmadesimple.substack.com/
Check out my other articles on Medium. : https://rb.gy/zn1aiu
My YouTube: https://rb.gy/88iwdd
Reach out to me on LinkedIn. Let’s connect: https://rb.gy/m5ok2y
My Instagram: https://rb.gy/gmvuy9
My Twitter: https://twitter.com/Machine01776819