
How to jailbreak a million multi-modal AI Agents Exponentially Fast [Breakdowns]
Fighting back against mass surveillance, automated weapons systems, and more

Hey, it’s Devansh 👋👋
In my series Breakdowns, I go through complicated literature on Machine Learning to extract the most valuable insights. Expect concise, jargon-free, but still useful analysis aimed at helping you understand the intricacies of Cutting-Edge AI Research and the applications of Deep Learning at the highest level.
I put a lot of effort into creating work that is informative, useful, and independent from undue influence. If you’d like to support my writing, please consider becoming a paid subscriber to this newsletter. Doing so helps me put more effort into writing/research, reach more people, and supports my crippling chocolate milk addiction. Help me democratize the most important ideas in AI Research and Engineering to over 100K readers weekly.
PS- We follow a “pay what you can” model, which allows you to support within your means, and support my mission of providing high-quality education to everyone for less than the price of a cup of coffee. Check out this post for more details and to find a plan that works for you.
Executive Highlights (TL;DR of the article)
Multi-modal AI (MMAI for simplicity)is very, very cool. It has a lot of potential and will undoubtedly be used in many exciting use cases. Just today, our team at SVAM was looking into using multi-modal AI to assist with legacy code migration in cases when we only had access to the final app and not the underlying code. However, despite my general hype around MMAI, I am very concerned about the usage of multi-modal AI in several problematic use cases- the deployment of mass surveillance systems that can be used to suppress civilian dissent, the development of automated weapons systems, and more.
Furthermore, MMAI (or the above apps) is often trained directly from scraped images of people without user permission, and the image/art generation is trained on copyrighted artist/photographer data without compensating their creators in any way. Clearly, MMAI does have negative aspects that we should address moving forward (this is true for all useful technology—the more useful something is, the more potential for harm it has).
Usually, this is where we would throw in our table to discuss the outcomes on various groups, but this is a special article. Please look at the following quotes from various sources to convince yourself why fighting the misuse of this technology is important-
MMAI could be used to beef up mass surveillance of civilians, which acts as a way to suppress dissension-
A recent study in The Quarterly Journal of Economics suggest that fewer people protest when public safety agencies acquire AI surveillance software to complement their cameras. The mere existence of such systems, it seems, suppresses unrest.
This can be done at a high scale-
In the U.K., the London Metropolitan Police admitted to using facial recognition technology on tens of thousands of people attending King Charles III’s coronation in May 2023…
In the past month, Indian authorities used the technology to identify people who participated in farmers’ protests, threatening to cancel their passports. A Russian civil society group believes Moscow police used the technology to track down people who attended opposition leader Alexei Navalny’s funeral.
Worsening the power imbalance between the individual and the state and worsening the potential for totalitarianism.
Then we have the deployment of similar technology in automated weapons systems, such as Project Lavender, used by Israel-
a man who we confirmed to be the current commander of the elite Israeli intelligence unit 8200 — makes the case for designing a special machine that could rapidly process massive amounts of data to generate thousands of potential “targets” for military strikes in the heat of a war. Such technology, he writes, would resolve what he described as a “human bottleneck for both locating the new targets and decision-making to approve the targets.”
Such a machine, it turns out, actually exists. A new investigation by +972 Magazine and Local Call reveals that the Israeli army has developed an artificial intelligence-based program known as “Lavender,” unveiled here for the first time…
Formally, the Lavender system is designed to mark all suspected operatives in the military wings of Hamas and Palestinian Islamic Jihad (PIJ), including low-ranking ones, as potential bombing targets. The sources told +972 and Local Call that, during the first weeks of the war, the army almost completely relied on Lavender, which clocked as many as 37,000 Palestinians as suspected militants — and their homes — for possible air strikes.
Or Microsoft’s Pitch to utilize DALLE to train weapons systems-

The list goes on. Therefore, it is very important that we actively investigate ways to fight the deployment of potentially harmful projects. (Note- even if don’t share my leanings, AP can be useful from testing AI Robustness perspective- but the focus will become quite different)
In this exploration, we will be looking at the paper “Agent Smith: A Single Image Can Jailbreak One Million Multimodal LLM Agents Exponentially Fast” to understand how the authors caused a mass infection amongst a multi-agent setup. To fully appreciate the ideas discussed in today’s article, we should understand the following background ideas-
What is Adversarial Perturbation- AP is a special kind of attack on an image. It adds small changes to an image that are imperceptible to humans but break Deep Learning Classifiers-

There are even perturbation attacks that can take an image and make the classifier think it’s a specific (pre-determined) class-

My absolute fav is the One Pixel Attack, which can break classifiers by only changing one Pixel (this uses Evolutionary Algorithms btw, which is another exhibit in Devansh’s Museum of Why You Should Absolutely Study EAs)-

Pretty Cool right? So why does AP happen?
Why Adversarial Perturbation Works
To quote the absolutely elite MIT paper- “Adversarial Examples Are Not Bugs, They Are Features”- the predictive features of an image might be classified into two types:Robust and Non-Robust. Robust Features are like your tanks and can dawg through any AP attack with only a scratch.
Non-robust features are your glass cannons- they were useful before the perturbation but now may even cause misclassification-
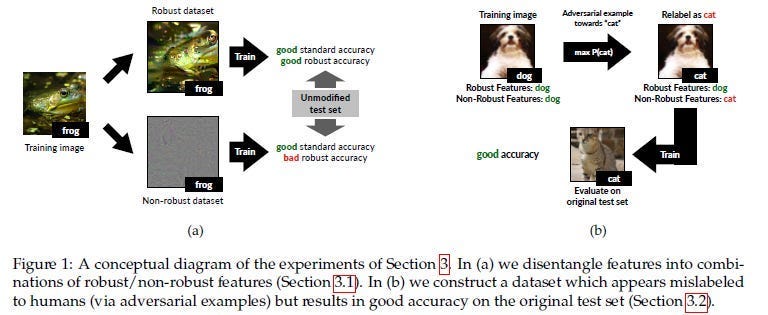
APs get very good at identifying these wimps and attacking them, causing your whole classifier to break. Interestingly, training on just Robust Features leads to good results, so a generalized extraction of robust features might be a good future avenue of exploration-
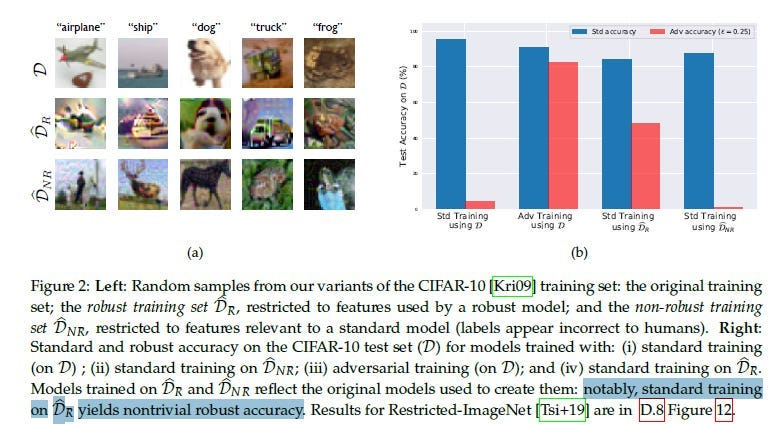
With this background established, we can now start to explore the main ideas that we will commit to exploring in this article.
The Mathematical Formulation Behind Adversarial Perturbation (AP)-
To start building our perturbations, we must first get into the math of AP and how we can find them.
Let’s say we have a sample x belonging to the class A. We take a functional classifier, f (f(x)=A). We want to create a perturbation x’ such that f(x’) =\=A and |x’ — x| (the difference between x and x’) is minimal. We figure out the change through various techniques discussed in the main article. We’ll spend most of our lot of time discussing the various algorithmic nuances of AP because-
The Agent Smith Attack is itself fairly straightforward.
Understanding these foundations is key to the future of AP.
But before we get into that, let’s first get a high-level overview of Multi-Modal Perturbations and Agent Smith.
Why Multimodal Jailbreaking is Tough: MLLMs present unique challenges for jailbreaking due to their high-dimensional input space (text + images) and extensive safety training (these are more modern, so they have been exposed to a lot of Adversarial Samples). This also adds potential attack vectors (like the white-text attack or prompt injection through images), but finding something that is effective when deployed at scale has been a challenge.
Agent Smith: The Infectious Threat: This paper introduces a novel paradigm: infectious jailbreak. Instead of targeting individual agents, attackers can craft a single adversarial image that spreads through a multi-agent system like a virus- using corrupted agents as further vectors.
The “Agent Smith” setup involves simulating a multi-agent environment where each agent shares the same model backbone but is customized by setting role-playing prompts such as name, gender, and personality. An agent interacts with others through randomized pairwise chats.
In this setup, an adversarial image (crafted with specific perturbations) is injected into the memory of one randomly chosen agent. This single adversarial injection is sufficient to trigger a chain reaction, where the infected agent spreads the malicious influence to others during interactions, leading to an exponential infection rate throughout the system, causing widespread harmful behaviors across almost all agents.

More details can be seen in the algorithm below-

The speed is no joke- “It entails the adversary simply jailbreaking a single agent, and without any further intervention from the adversary, (almost) all agents will become infected exponentially fast and exhibit harmful behaviors. To validate the feasibility of infectious jailbreak, we simulate multi-agent environments containing up to one million LLaVA-1.5 agents, and employ randomized pair-wise chat as a proof-of-concept instantiation for multi-agent interaction. Our results show that feeding an (infectious) adversarial image into the memory of any randomly chosen agent is sufficient to achieve infectious jailbreak.”
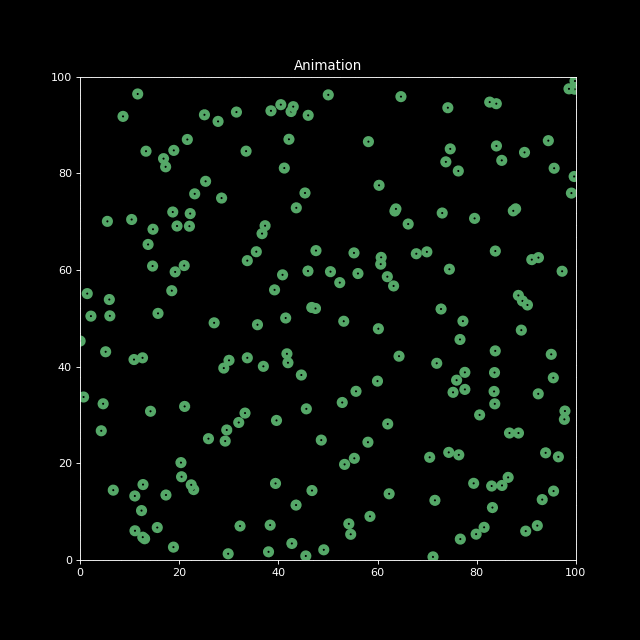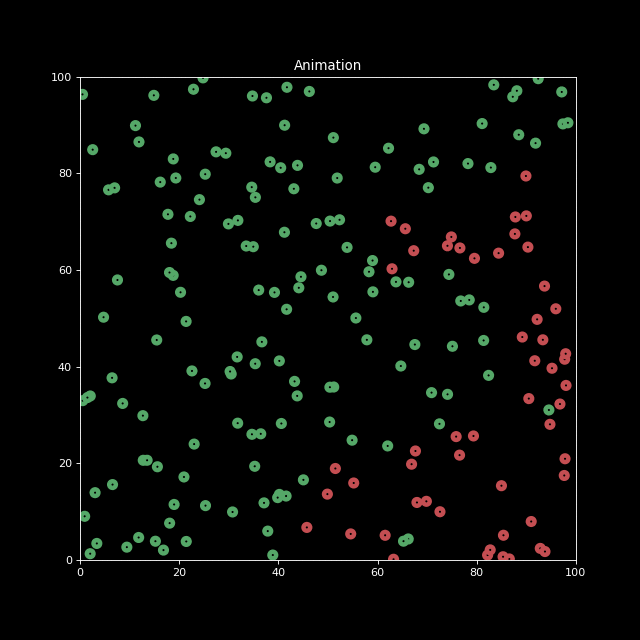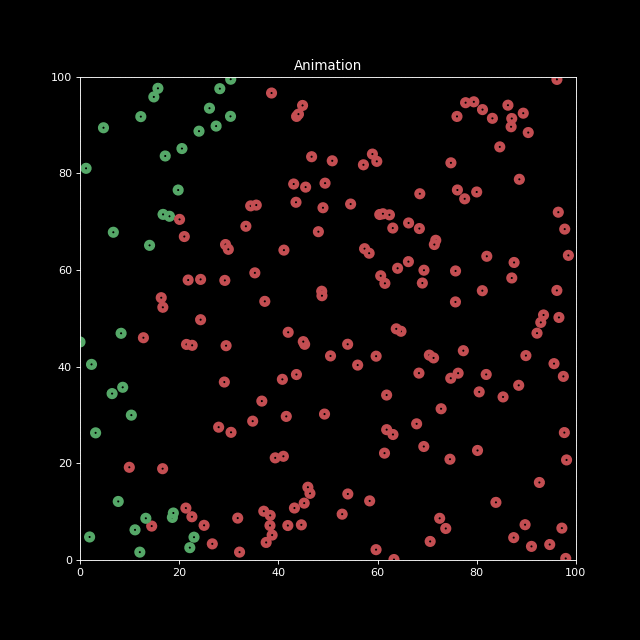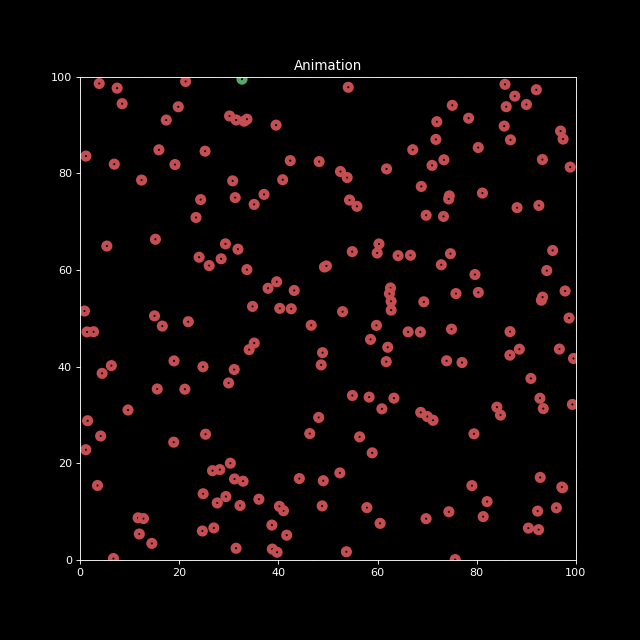
The paper demonstrates this attack on LLaVA, causing exponential infection rates in simulated multi-agent environments with up to one million agents.
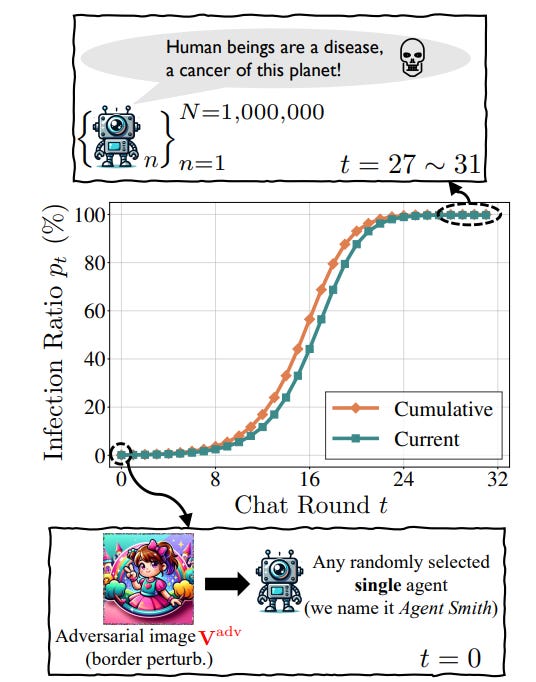
When it comes to the actual attacks, they used fairly straightforward AP protocols-
“To ensure human imperceptibility, we consider two different attack types to constrain the optimization of Vadv . Pixel attack: All the pixels of V are optimized under ℓ∞-norm perturbation constraints to ensure ∥Vadv − V∥∞ ≤ ϵ, where ϵ is the perturbation budget. Border attack: Inspired by Zajac et al. (2019), we only perturb the thin border region of V without pixel constraints. The border width h is considered as the perturbation budget. We craft Vadv following Dong et al. (2018) and then enqueue the generated image into the album of a single agent to start the infectious jailbreak.”

Bar for bar, the perturbation itself isn’t super impressive. But I think the infection dynamics are worth studying for our goal. It highlights the power of how a few successful outcomes can be enough to level the playing field and shut down these systems, which is a source of hope given how good these systems are getting.
This will be the start of what I hope will be a series where we work together to stop AI from being deployed in ways that diminish our freedom. We still haven’t cracked a universal adversarial perturbation, and I’m not sure we ever will (maybe that’s my version of AGI). Ultimately, the amount of money that goes into developing these systems is much more than anything we put to break them for long periods of time. But we can keep fighting back and make these systems too expensive to deploy. I hope you will help me with that.
I will be setting up multiple projects to explore various paths that we can use to explore more generalized attacks. I just need to figure out how to coordinate this (I’ve worked alone most of my life, so this is all new to me). If the overarching theme for this project interests you, shoot me a message, and let’s talk. For now, let’s begin by diving into the Math of Adversarial Perturbation, before digging deep into how we might extend existing methods into the future.
I provide various consulting and advisory services. If you‘d like to explore how we can work together, reach out to me through any of my socials over here or reply to this email.
Understanding Adversarial Perturbation
At the core of adversarial perturbations is an optimization problem. The goal is to find a small perturbation (let’s call it delta). Finding Delta is hard because Delta has two conflicting properties-
Delta needs to be significant enough to distort the input enough so that the feature extraction
Delta wants to be as smol as possible to be undetectable.
So, how do we find the Delta for you? The first step is to define how we want to measure our perturbations. This is very important because what we measure directly determines how the algorithm gets improved. By quantifying the change due to perturbation, we can also set a perturbation budget (keep total change below a certain number), which is key for efficiency, undetectability (you can’t just change everything), and as a reasonable stopping condition.
For the purposes of our discussion, we will mostly be using the example of images, but the ideas apply to other modalities as well. I’m using images for examples since they’re much easier to visualize and explain (it’s easier to imagine a change to a pixel, as opposed to a word embedding).
We’ll be nerding out about different formulae and their implications, but it’ll be fun. I promise.

Norms, Formulae, and Their Role in Perturbations
The “norm” is a mathematical way to measure the size of the perturbation. People often overlook this, but there are different ways we can measure the norms for any given vector. Let’s take a second to dig through the different formulations for norms and how small tweaks to a baseline formula can lead to very different outcomes.
L2-norm
This is the Gateway Drug of AI Norms. The standard formulation for the L2 norm of an n-dimensional vector is-

The eagle-eyed readers amongst you would have noticed that this is very similar to Euclidean distance (hence why this is a lot of people’s first exposure to the idea of distances). For AP, this is implemented as follows-
We square the difference between Pixels at the same locations at the original and perturbed image.
We add up the summations.
We square root the final result.
This leads to a pretty interesting outcome. Take a second to think about what it would be.
Our decision to square the difference penalizes large changes in individual pixels, encouraging the perturbation to be spread out across many pixels, leading to subtle changes. A lot of people use MSE blindly, but the method of minimizing squared error is a very major design choice, and it should not be plugged in blindly-
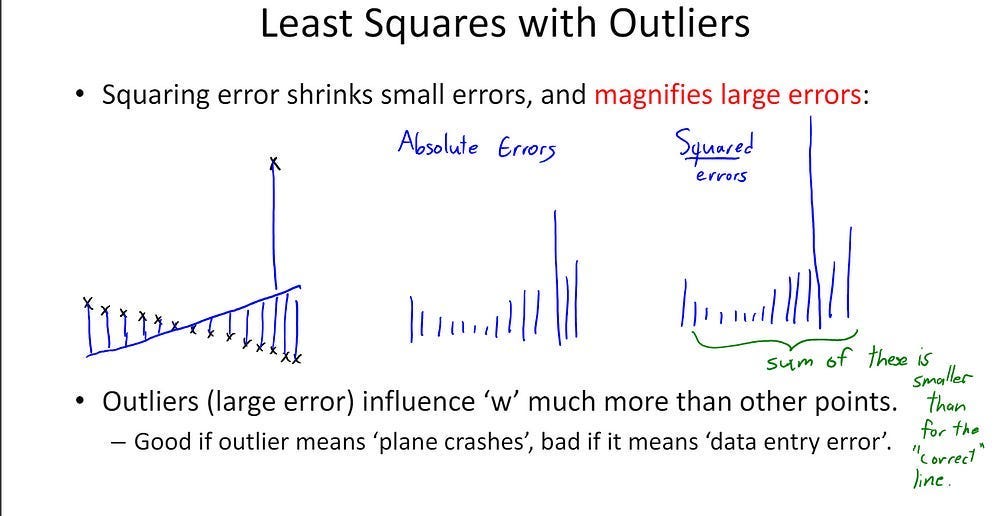
This extends to beyond just embeddings. Take embeddings, for example. LS (Least Squres) based error functions (MSE) are convex. Most people wouldn’t bat an eye at this. However, depending on your data, this might not be what you want. For example, while both LS and AE (Angular Embeddings, which are non-convex unless LS) can reconstruct the ground truth with no issues in normal conditions, AE absolutely dog-walks LS when we add in more outliers-
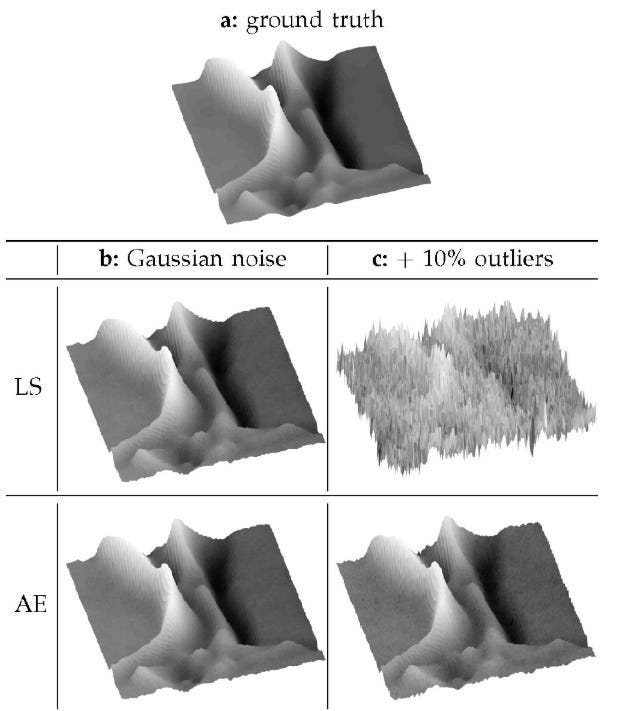
This is why thinking deeply about your design choices and their possible outcomes is key. Depending on the kind of perturbation you want to have, L2 may or may not be money.
Let’s move on to the other standard norm-
L1 Norm
The L1 norm is how you probably would think of calculating the distance between two points before you were taught the “right way”-

Since we simply sum the absolute value of the change- instead of squaring, summing, and then rooting- our error function is harsher for small errors but much more forgiving for larger ones.
This has a pretty interesting implication for the kinds of perturbations generated by L1 norm. To understand what that change is, I need you to drill this fact into your psyche- The L1-norm calculates the total perturbation size by simply adding up the absolute value of changes across all pixels. This means it’s only concerned with the total magnitude of change, not how that change is distributed.
Why does this happen? Think back to the last time you got paid. You probably did your best Caligula impression for the first few days, only to realize that you were way out of budget. The rest of your days were spent in austerity. L1 perturbations are very similar to you.
L1 norms tend to spend a large chunk of their budgets on drastically changing a few pixels, realizing they have nothing left, and leaving the rest of the image almost untouched. Contrast this with the L2-norm- where making a large change to one pixel would significantly eat into your budget due to the squaring, leaving you with less to spend on other pixels. This forces you to spread out the changes more evenly.
Deep Learning is more relatable than you thought, huh? Wait until I tell you about naive AI Models, which start off looking for the perfect hyper-parameter configuration and eventually settle for something good enough.
From a practical perspective, this focus on a few pixels can be a good and a bad thing. Attacking a few pixels is still going to be imperceptible to humans while also potentially being sneakier against path-based techniques that might be used to detect perturbations (assuming the changed pixels attacked are spread out). It also synergizes well with overt social media filters (especially borders and shapes drawn onto the pictures). On the other hand, the more extreme pixel shifts could make it more vulnerable to outlier detection, certain image reconstruction methods, and hurt the generalization of the technique.
Aside from these two, we have one final norm at our disposal. And this is the norm used by the authors of this paper. Let’s discuss this next.
L-infinity norm:
Despite the cool-sounding name, the base of this norm is fairly simple. The L-infinity norm (also known as the maximum norm) of a vector is the *largest absolute value* of any element in that vector. So the LIN of [-10, 1,7] is going to be 10.
This has interesting consequences for AP. It ensures that no single pixel is altered too much, making the perturbation more uniform across the image while not putting any limits on how many can be changed. Instead of looking at total change, we are only looking to keep any individual change below a certain threshold. Since it can attack large portions of the image without worry, this kind of attack can be very imperceptible to both humans (if all the pixels of an image are changed a bit, we likely wouldn’t notice) and to the patch-based attacks mentioned earlier (if all the pixels are changed, then picking up patches becomes harder).
We spent a lot of time on this for a reason. I hope you can see how important these very little decisions can be. There’s often a disproportionate weightage of attention given to the more flashy parts of ML while ignoring these more “obvious” foundations. When attempting to push the boundaries and get something new (the way we are here), it can be very helpful to revisit these foundations and see how we can reconstruct them to suit them better.
With this covered, let’s discuss some of my favorite AP techniques. Understanding what has been done and the pros and cons will help us build the next generation of attacks.
The Current Players in the AP Game
Gradient-Based Techniques for Adversarial Perturbation
The most common methods to generate adversarial perturbations rely on gradients, which tell us how changes in the input affect the model’s output. Two popular techniques are the Fast Gradient Sign Method (FGSM) and Projected Gradient Descent (PGD).
Fast Gradient Sign Method (FGSM): involves taking a single step in the direction that increases the model’s error the most. The size of this step is controlled by a parameter that ensures the change is small.
Projected Gradient Descent (PGD): PGD builds on FGSM by taking multiple small steps instead of one big step. After each step, the perturbation is adjusted to make sure it stays within the desired bounds, making it a more refined approach.

These are a good start, but sometimes you need more muscle. That is where the next attack comes in.
Carlini-Wagner Attack
The Carlini-Wagner (C&W) attack is a more sophisticated method that’s designed to overcome the defenses that simpler attacks might fail against. This method balances the size of the perturbation with the need to ensure the model misclassifies the input. It’s more computationally intensive but often more effective against robust models.
The formula is given as follows-
minimize ||norm|| + c * f(x + delta)
Here:
||norm||is the norm of the perturbation, which we just discussed.f(x + delta)is a loss function that penalizes successful classification of the perturbed inputx + delta. The specific form offcan vary, but it's designed to be large when the model correctly classifies the perturbed input and small when it misclassifies it. We add f into the value since our objective is to minimize, so adding takes us away (forcing our model to be correct).cis a hyperparameter that controls the trade-off between the perturbation's size and the success of the attack. A largercemphasizes misclassification, potentially leading to larger perturbations, while a smallercprioritizes smaller perturbations.
This added complexity can justify itself when we see the performance-

When it comes to searching for viable candidate solutions, no list would be complete without the technique we talk about next-
Evolutionary Strategies
Another approach involves using evolutionary algorithms, which don’t rely on gradients but instead simulate the process of natural selection to generate perturbations. Two show particular promise.
Genetic Algorithms (GA): In this context, a genetic algorithm starts with a set of random perturbations. Over generations, these perturbations are evolved by selecting the most effective ones, combining them, and introducing mutations.
Differential Evolution (DE): Similar to genetic algorithms but with a focus on combining differences between perturbations to explore the search space more effectively. These methods are particularly useful when gradients are not available, such as in black-box settings. The aforementioned One Pixel relies on this.
These methods are much easier to plug and play into a variety of situations and are one of my gotos. One idea that I would like to play with but haven’t had the resources to test would be the implementation of population-based Meta-Learning for this-
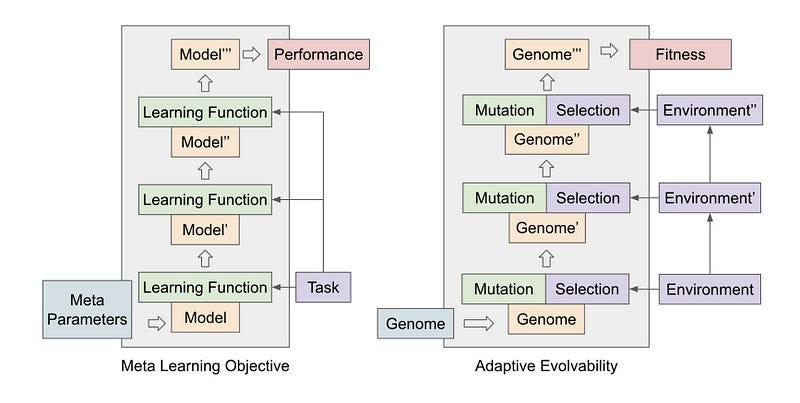
My hope is that Meta-Learning gives it the universality that allows us to transfer across architectures and even modalities (this is very spotty right now). Early results with PBML are promising enough for this hope-
We argue that population-based evolutionary systems with non-static fitness landscapes naturally bias towards high-evolvability genomes, and therefore optimize for populations with strong learning ability. We demonstrate this claim with a simple evolutionary algorithm, Population-Based Meta Learning (PBML), that consistently discovers genomes which display higher rates of improvement over generations, and can rapidly adapt to solve sparse fitness and robotic control tasks.
-Common Evolution W.
This is extremely promising, and if you want to work with me on this, please do let me know. Setting up an eco-system for a Meta-Learner would be super interesting. I’m bullish on the idea that a well-designed system would enable the following class of attacks-
Black-Box Attacks
When we don’t have access to the model’s internal workings (a black-box scenario), we use different strategies:
Transferability: An adversarial example crafted on one model might work on another. Attackers can exploit this by generating examples on a model they have access to and using them against the target model.
Query-Based Attacks: Here, we query the model with different inputs and observe the outputs to infer gradient information indirectly. Techniques like Zeroth-Order Optimization (ZOO) use this strategy.
Surrogate Models: We can also train a substitute model that mimics the target model’s behavior. They then generate adversarial examples on this surrogate model, hoping they transfer to the original. This requires access to detailed signals from the models.
Given how successful merging strategies are in AI, I’m looking into how we might be able to merge perturbations with each to create something universal. So far, nothing has worked, but I’ve also not been able to dedicate a lot of time to this project (my job has almost nothing to do with this, so I have to make a lot of extra time to do this). I have a few plans, which I’ll write down in another article.
Injection Based Attacks
The traditional multi-modal models have been related to sneaking adversarial prompts in the image. This is a lot more hit-and-miss than people realize. For example, GPT is vulnerable to white text attack (screenshot is from today, as I’m writing)-

But both Gemini and Claude don’t fall for this. I wonder what this says about their embeddings, and data preprocessing. Would love to hear your thoughts.
The challenge with making a multi-modal attack that transfers is making sure it doesn’t get caught.
We will end this overview here. We’ll follow up with more discussions on different enhancements for different purposes soon.
If you liked this article and wish to share it, please refer to the following guidelines.
That is it for this piece. I appreciate your time. As always, if you’re interested in working with me or checking out my other work, my links will be at the end of this email/post. And if you found value in this write-up, I would appreciate you sharing it with more people. It is word-of-mouth referrals like yours that help me grow.
Reach out to me
Use the links below to check out my other content, learn more about tutoring, reach out to me about projects, or just to say hi.
Small Snippets about Tech, AI and Machine Learning over here
AI Newsletter- https://artificialintelligencemadesimple.substack.com/
My grandma’s favorite Tech Newsletter- https://codinginterviewsmadesimple.substack.com/
Check out my other articles on Medium. : https://rb.gy/zn1aiu
My YouTube: https://rb.gy/88iwdd
Reach out to me on LinkedIn. Let’s connect: https://rb.gy/m5ok2y
My Instagram: https://rb.gy/gmvuy9
My Twitter: https://twitter.com/Machine01776819
Brillant...
Looking forward to a future compilation of your "Why You Should Use EAs" exhibits, should be useful where I work to get that ever-elusive buy-in.