

Why Big Tech Companies should copy Xs Grok ASAP
Why Big Tech Companies should copy Xs Grok ASAP
Grok is the first hint at how LLMs might be made commercially viable

Over the last 2 weeks, I’ve had a lot of requests to focus a few articles on the industry/market impacts of major developments. Given all that went down this week, I figured this would be a good time to try things out. Lmk if you like such articles, and I’ll throw more of these into the rotation. Also, if you’re interested in community events/meetups, please drop your thoughts in the survey below-
Given all the noise being generated by OpenAIs Dev Day announcements (I gave my early impressions on the developments in this video), people have been overlooking Elon Musk’s announcement about Grok, X’s new AI Model. At first glance, it looks like yet another LLM, with the biggest talking point hovering around its sassy responses. In this article, I will go over why Grok is the blueprint for what Big Tech Companies should look at to boost profitability.
More specifically, we will cover the following ideas-
The Big Tech Dilemma: As I’ve alluded to multiple times, Big Tech companies have already started to maximize their total addressable markets in their primary niches. This is why they are investing so much money into their secondary fields.
How Grok could be the future- All major tech giants have extremely valuable data. For now, most monetization around the data revolves around advertising or product improvements. Grok provides another avenue for monetization, one that opens the door to a lot more people. However, the same principles can also be applied to any firm/business that has a lot of data that they wish to interact with (to build in-house solutions).
Technical Details Overview- We’ll cover some of the technical considerations to account for when developing systems like this.
The AI Doomer Hypocrisy- Elon Musk was one of the high-profile supporters of the AI Pause. Not even a year since he pushed for this pause, his company released Grok (which means they were developing this even as he spoke against LLM development). It’s important to remember that a lot of people raising alarm about AI Danger often have ulterior motives for their claims.
Let’s cover get right into this.
The Big Tech Dilemma
Towards the beginning of the Internet Age, there were lots of open markets for the taking. This meant that companies could come in and build their empires by specializing in different areas. Google took search, Meta took Social Media, Amazon E-Commerce, etc. At this stage, it was possible to please investors by simply showing strong growth in their niche. Things are different now. Having already cornered most of their total addressable markets, major tech companies need to expand into new avenues.
Companies have been spending furiously on demos, projects, lobbying, and acquisitions. We’re looking at an arms race with trillion-dollar incumbents competing with Startups flush with Venture Capital Money (and amongst themselves). This has led to a massive increase in spending- “Worldwide IT spending is projected to total $4.7 trillion in 2023, an increase of 4.3% from 2022, according to the latest forecast by Gartner, Inc. As CIOs continue to lose the competition for IT talent, they are shifting spending to technologies that enable automation and efficiency to drive growth at scale with fewer employees.”
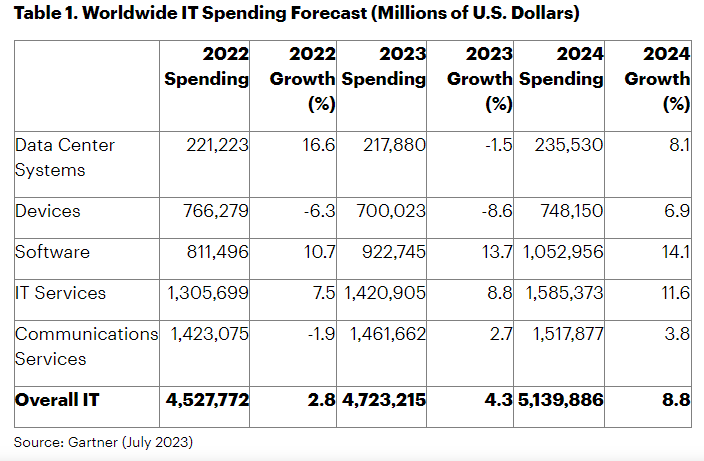
What does this have to do with Grok? Despite their hype, LLMs have so far fallen short of expectations. Over the last 2 years, people have been predicting massive shifts in the economy coming soon. That never materialized, with billions of Dollars being pushed into model development with no real results to speak of. Even models like GPT have struggled to integrate into major workflows. Grok is an indication of how Big Tech companies can leverage LLMs to generate an additional source of revenue in the near and medium terms.
Let’s cover how next.
Grok and Data Sources
Grok has 2 notable features-
It is able to access Tweets to form the most recent opinions.
Its sarcastic personality (based on what I’ve seen, it’s not particularly funny. I’m fairly confident that simply putting a “Be sarcastic” prompt in other LLMs will lead to similar results).
The first is what we’re interested in. Not so much because this will dramatically improve Grok’s performance in answer generation (this will depend a lot on the topic on hand and the implementation details) but because this gives Grok the ability to interact with a dynamically shifting (and extremely valuable) dataset.
I want you to think about what LLMs actually enable you to do. As I’ve written about in my article on Prompt Engineering- LLMs provide us with an easy interface to interact with our data. Using LLMs allows everyone to interact with an underlying dataset (either directly through RAG or indirectly through an LLM) and pull out insights from it.
When I worked in Supply Chain Analysis, we toyed with using Twitter data as a way to extract sentiment around a particular area. At that stage, pulling all that information was a nightmare. With a tool like Grok, this changes the dynamic. Suddenly I can survey the sentiment en masse and pull insights easily. Grok acts as a very easy interface for me to access very valuable data.
This opens up different options for a business-
Selling access to data as is: Allows you to monetize engineers and providing APIs and tools would be a great way to hook open source contributors into your company's ecosystem. Chances are that we will see startups build their value offerings around this: creating a more stable revenue source
Selling data to reports and insights: Gives you access to financial folk, managers, and anyone else who needs either in-depth or panaromic insights into a topic. McKinsey and Co. make bank here, so there’s a strong monetization potential(the Management Consulting Business just in the USA was worth 366 Billion in 2022).
Selling consulting services- A lot of time is wasted to figure out the best post format, SEO tricks, advertising campaigns, etc. Companies would be more than happy to pay Google money to design their ad campaigns. Or let Amazon provide insights into what makes for successful e-commerce copywriting. I would happily pay LinkedIn, Instagram, and TikTok to help me create better posts because my results on there are tragic(afaik I’m the only creator in the world that gets more views on my writing than the aforementioned platforms that were made for virality. Sed life). Companies could utilize their already strong user profiling technologies to implement this at no additional cost to them.
Will these completely revolutionize companies? Probably not. However, the ideas mentioned have high margins, low operational costs, and can be implemented quickly. These can be valuable to soothe investor confidence until the next 10x breakout does happen.

Let’s say you’re a non-AI person in a big tech company that wants to lead the proof of concept for such an idea. Or you work in finance, law, or another high-impact field with a lot of in-house data. In either case, you’d need to build a compelling Information Retrieval Demo to get the ball rolling. Don’t worry, your boy gotchu there. We will now talk about Retrieval Augmented Generation, and what you should look out for to build your own RAG systems.

How to Build Better RAG Systems
Retrieval Augmented Generation gets a lot of attention these days. Most discussions around RAG revolve around Context Length (well-played to Anthropic and how they put themselves on the map by making that such a major discussion point). While that can be important, context length isn’t really the most important factor that holds back most RAG applications. The quality of generations depends on a lot more than just the context size. Even if the model theoretically has a higher context length, it doesn’t mean it will pull out relevant information: “Current language models often fail to incorporate long contexts efficiently during generation. We show that a major contributor to this issue are attention priors that are likely learned during pre-training: relevant information located earlier in context is attended to less on average.”
There is a simple reason for this- quality is hard to measure, but context size is not. Thus, we can make the latter a metric. It’s a great demonstration of Goodhart’s law
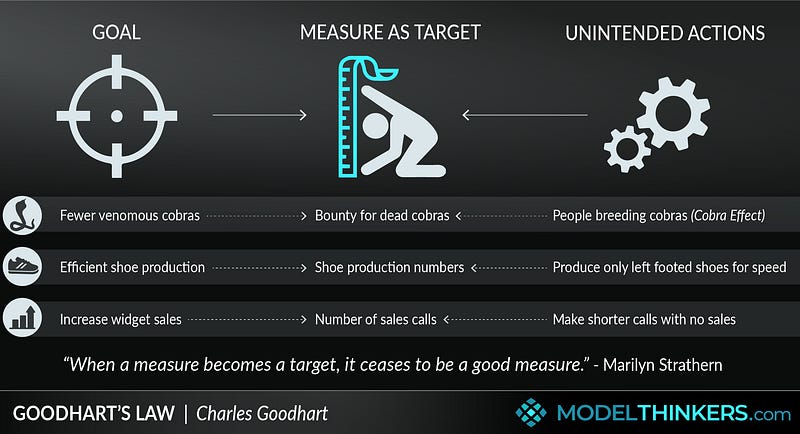
The difficulty with RAG is that it is inherently a very fuzzy task. It’s very hard to quantify what is a good generation (that’s one thing that RLHF does well). It’s also very context-dependent, with your use-case completely changing the dynamic of your system (some people want to use RAG for primarily information retrieval while others want RAG that’s more concerned with Generation).
However, based on my ~2.5 years of building these systems (yep I’m old) and given that my day job currently involves building a lot of RAG-based systems for various clients, I can give you a few overarching principles. Let’s cover them.
Principle 1: Put More Emphasis on Retrieval, Design, and Data Prep.
This might seem really obvious but one of the biggest things that hold back a lot of more advanced AI Projects is that they try to do too much with one system. This leads to a mess with the project, as we see developments with too many conflicting visions and goals. Rather than trying to build a complex system immediately; it’s better to build a simpler, streamlined system first and then layer complexity on it.
In the context of RAG, the information extraction element is much better defined than generation. Therefore, it makes sense to maximize the capabilities in that area, with a heavier emphasis on pulling the information out. When possible, my recommendation is to push the generation to dedicated services that take information and generate reports on it. This is more reliable, cheaper, and will let you utilize both deterministic and non-deterministic AI to their max.
Another overlooked area is Data Preparation. You’d be shocked at how well you can do by structuring your data to make it more searchable. By grouping relevant data together (even if it means duplication), you can better direct the search. Lastly, don’t sleep on the magic that basic design and user guidance can do for you. Let’s walk through an example there.
Say someone at Meta reads this piece and wants me to take a crack at building a Grok-like platform for the different industries in their industry reports shared earlier. Instead of trying to build a massive general model that will parse through all the data stores, I would have smaller models that are each restricted to data sources from their respective industries. This way, my operational costs are lower and the model doesn’t get confused regularly while also making testing and improvements easier (we have a more fine-grained insight into when our system does better/worse).
What about Cross-Industry Insights? There are 2 ways to spin this-
Upsell this as an additional service compiled from the information available.
Develop a separate report generation AI that will take your input data and generate reports on it (it doesn’t add much, just builds the reports from the input).
Either way, by separating our complex general model into dedicated retrievers and generators we allow ourselves to fine-tune the individual components much better. Think of this as the AI architecture version of the Separation of Concerns Principle.
Principle 2: Know Thyself
Before you throw tomatoes at me for uttering generic platitudes, hear me out. In a similar vein to what we discussed above, understanding what you need from your RAG system is important to designing it to fit your needs. Before you start developing an RAG system, you should have a very clear understanding of how it will operate and what problems it will solve. As Noel Noa from Blue Lock said, “Your plans can’t have an “I don’t Know” ”.
When it comes to open-domain question answering, there are two different approaches- The Retriever-Reader and Retriever-Generator frameworks. The Retriever-Reader framework retrieves documents and then reads them to extract a specific answer. In contrast, the Retriever-Generator framework retrieves documents to provide context and then generates an answer, possibly synthesizing information from multiple sources.
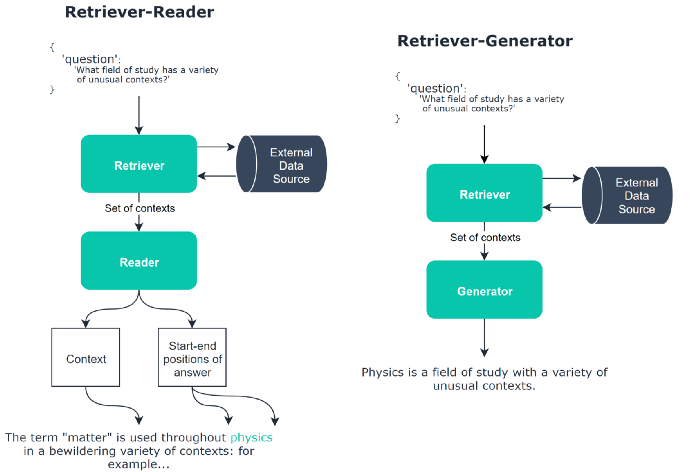
For precise, fact-based questions where answers can be pinpointed in texts, the Retriever-Reader is better. The Retriever-Generator is better for questions that benefit from amalgamating information or when generating answers that may not be directly extractable.
Knowing how you want your systems to work will guide you to the right approach.
Principle 3: Prioritize Visualization and Multi-modality
You want your systems to be useful to people. Generally speaking, more visualizations are directly proportional to better reception. Developing the ability to plot charts and graphs is a great way to make your RAG system better (as mentioned earlier, you could have dedicated routines to take in data and plot it, no fancy generators required). Visualizing the outputs and the process looks cool and improves system transparency.
In a more general sense, multi-modal capabilities are super important. Building systems that can ingest, process and output a combination of text, tabular, and image data will make them more useful. These can be done over time, but are very important. One thing my experiments with GPT-4 have shown is that it is far above in the processing side of things. Using that to train your own model/directly into your systems is not a bad strategy. Especially for the early stages, when deployment is more important than efficiency.
Principle 4: Prevent Data Leaks and Injections
This is fairly straightforward. When building LLM-based interfaces, there’s always a risk that an adversarial user might be able to use prompts to either download your data or inject new (false/harmful) data into your sources. Unfortunately, I haven’t come across any great solutions here. The best performers are relatively dumb methods-
Limit the transmission to ensure that people don’t pull all your data.
Configure permissions so that any interface/method of communication can only share so much.
Use anonymization/encryption to reduce harm with data leaks.
Reject all data injections by the user by simply not allowing AI to make changes to your underlying data sources.
If I come up with a universally secure method for preventing this, you will definitely be hearing about it. Till then, you’ll have to make do with these.
If you are looking to build RAG systems (or with any ML Consulting), reach out and we can talk shop.
I want to end this on a quick note on something very ironic (but serious) about Musk releasing Grok.
The AI Doomer Hypocrisy
I know it feels like ages ago, but you might remember the very prominent AI Open Letter calling for a pause on the development of powerful AI models. Amongst that letter’s most ardent supporters was Elon Musk. This letter was published on March 22nd. This means that the release of Grok is not even 8 months from that letter. Given how much time it takes to train LLMs, this implies that a lot of the model training was likely taking place as Musk was calling for this pause.
I’m not a huge fan of beating dead horses, but this has to be said: many high-profile AI Doomers are grifters. They refuse to engage in good-faith discussions, address research/critiques of their stances, and spend their time harping about sensationalist existential risks. We’ve seen “experts” like Gary Marcus rely on extreme strawmanning, Big Tech companies funnel heaps into lobbying against open-source, and recently MS president Brad Smith claim things like “GPT is as Open as Llama”. MS has also leaned hard on pushing government regulation to stifle open source.

Notice how their regulation involves things like creating licensing for models, creating a registry of ‘high-risk’ systems, and investing in their own (very biased) academic research as opposed to third-party parties that would help expose fragilities in the systems.
MS built their whole platform from Open Source (Linux) and now wants to control it to stifle competition. Half the people championing AI Safety don’t care about Safety- they just want control. We saw a similar playbook happen with academic research- greedy journals stole and privatized public research. Now everyone has to pay heavily to access research. It’s on us to fight back and stop them from centralizing power.
If you liked this article and wish to share it, please refer to the following guidelines.
That is it for this piece. I appreciate your time. As always, if you’re interested in working with me or checking out my other work, my links will be at the end of this email/post. And if you found value in this write-up, I would appreciate you sharing it with more people. It is word-of-mouth referrals like yours that help me grow.
If you find AI Made Simple useful and would like to support my writing- please consider becoming a premium member of my cult by subscribing below. Subscribing gives you access to a lot more content and enables me to continue writing. This will cost you 400 INR (5 USD) monthly or 4000 INR (50 USD) per year and comes with a 60-day, complete refund policy. Understand the newest developments and develop your understanding of the most important ideas, all for the price of a cup of coffee.
Reach out to me
Use the links below to check out my other content, learn more about tutoring, reach out to me about projects, or just to say hi.
Small Snippets about Tech, AI and Machine Learning over here
AI Newsletter- https://artificialintelligencemadesimple.substack.com/
My grandma’s favorite Tech Newsletter- https://codinginterviewsmadesimple.substack.com/
Check out my other articles on Medium. : https://rb.gy/zn1aiu
My YouTube: https://rb.gy/88iwdd
Reach out to me on LinkedIn. Let’s connect: https://rb.gy/m5ok2y
My Instagram: https://rb.gy/gmvuy9
My Twitter: https://twitter.com/Machine01776819
I don't think Gary Marcus is a grifter. I'm more skeptical of regulation than he is, but that aside, I think he makes lots of good observations about the limitations of Deep Learning models.
Well done (as usual), Devansh. I just want to add a small factoid that strikes me as unusual, and which may suggest Elon has been playing “the long con” with LLMs from the get-go. First, nobody who knows Musk believes he ever worries, or has ever worried, even for one hour, that AI is a danger to anything but Tesla’s FSD aspirations. IT’S ALL KIBUKI THETER!
And here’s the factoid I believe adds “some” credibility to thus view:
-When I purchased my 2018 Model 3, I was astonished at how incredibly good the car’s voice recognition (“V-R”) system worked. There was, and remains, ZERO comparison to Alexa, Siri, or GoogleVoice - it blows them all out of the water. I had to ask myself, “why isn’t Tesla making billions just by licensing the V-R to the other big tech companies?
DUH! He’s probably sitting on the best AI that exists, and before he offers to sell any of it, he’s having the last laugh by scamming Altman into “thinking” he (Altman) took over OpenAI and “threw Elon out”.
Right, like the man-child Altman is even capable of building workable GPTs. He’s not - Chat-GPT, especially the numbered versions, are really close to useless, and yet now, Altman is running around like “Chicken Little” warning the world about “Alt-Net” taking over the earth. MARKETING 101…HA HA!!! So Musk invents the transformer model (this is true, btw), but leaves only the dumb half at OpenAI and uses the “smart” system for V-R in his products (EVs).
Then he covinces idiot-boy Altman to run around hyping the “existential threat of AI”, hoping to create regulatory capture for side-stepping indemnity issues, which benefits who the most? TESLA, for FSD. BRILLIANT!
If my “conspiracy theory” is correct, then within one year, Grok (which likely existed by 2016, but has been trading on data the entire time) comes out and blows away all other GPTs. Musk not only gets richer (like he cares, anyways), but in one fell swoop:
- becomes indistinguishable market leader in GPTs
- all but puts Google and especially OpenAI+MS out of the AI market for another 10 years,
and, best of all,
- admits AI is just another form of social media, is no threat to anybody, and OWNS the biggest market of them all; AI THAT ACTUALLY WORKS (at least a little).
Like I said…BRILLIANT!!!