
How a Tiny AI Startup is beating OpenAI by Redefining Intelligence [Breakdowns]
Inside AXIOM by VERSES AI: The Cognitive Architecture That Runs 5000× Cheaper and 140× Faster than GPT.

It takes time to create work that’s clear, independent, and genuinely useful. If you’ve found value in this newsletter, consider becoming a paid subscriber. It helps me dive deeper into research, reach more people, stay free from ads/hidden agendas, and supports my crippling chocolate milk addiction. We run on a “pay what you can” model—so if you believe in the mission, there’s likely a plan that fits (over here).
Every subscription helps me stay independent, avoid clickbait, and focus on depth over noise, and I deeply appreciate everyone who chooses to support our cult.
PS – Supporting this work doesn’t have to come out of your pocket. If you read this as part of your professional development, you can use this email template to request reimbursement for your subscription.
Every month, the Chocolate Milk Cult reaches over a million Builders, Investors, Policy Makers, Leaders, and more. If you’d like to meet other members of our community, please fill out this contact form here (I will never sell your data nor will I make intros w/o your explicit permission)- https://forms.gle/Pi1pGLuS1FmzXoLr6
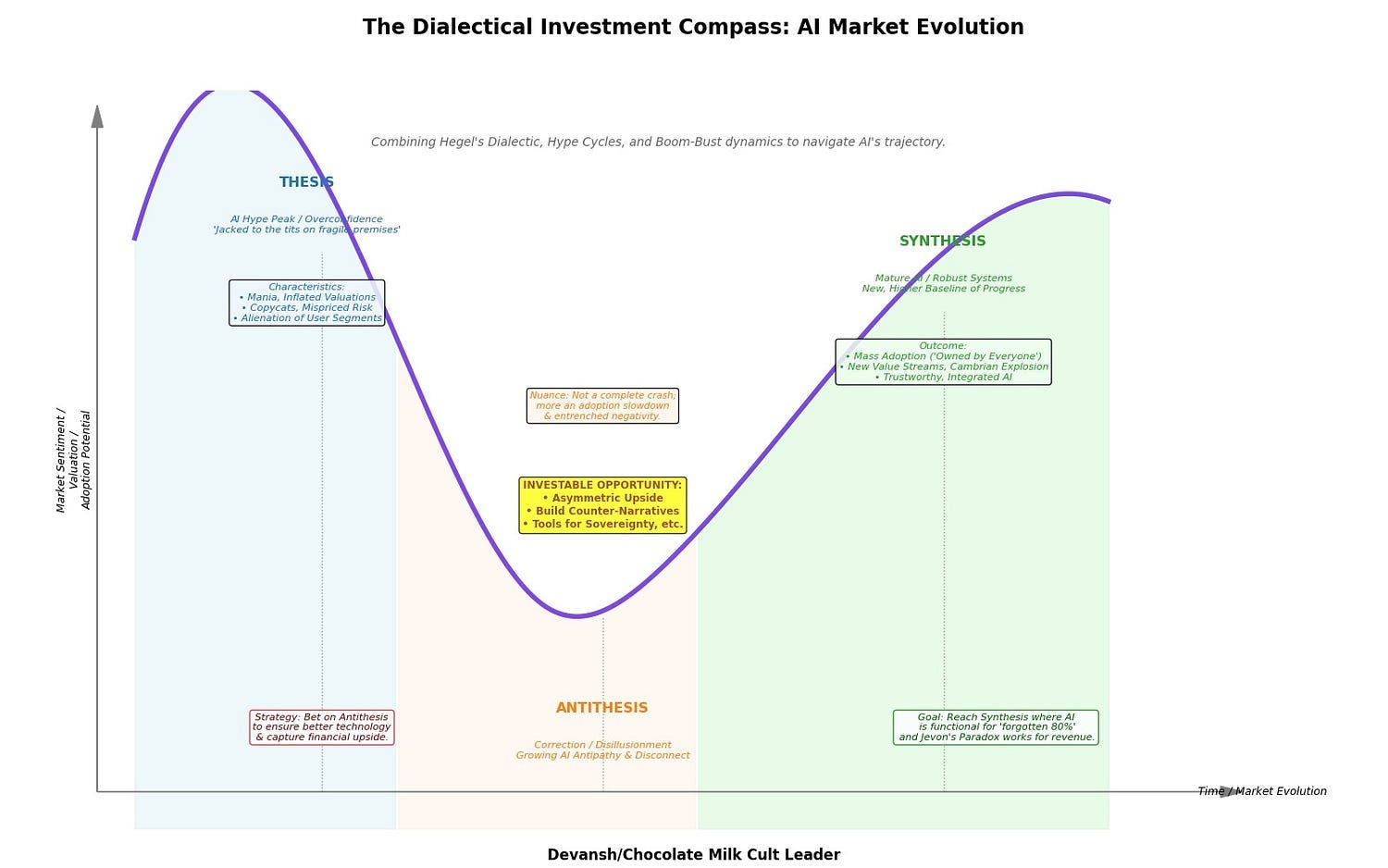
At this point, everyone is talking about “diminishing scaling laws” and how Generative AI is hitting walls. It can generate a photorealistic image of an astronaut riding a unicorn in the style of Togashi, yet will fail at generating a full glass of wine. It can go on and on about Hegel, but it can’t reliably perform the multi-step reasoning of a ten-year-old playing a board game. The broken clocks gleefully pointing to failures around counting the rs in words or solving simple puzzles do have a point — Generative AI has some severe limitations that stop it from being reliably “intelligent”.
And we can no longer donate our paychecks to Daddy Jensen by yeeting money into GPUs to scale up indefinitely. To quote Sundar Pichai, “the low-hanging fruit is gone”.

So where do we go from here? On one side, we have an army of Cheadles trying to slowly fix the limitations of the system one step at a time. This is how we get Agents, Tool Use, SLMs, Reasoning models, and most of the trendy terms that you pretend to understand. This approach tries to isolate the harmful aspects of LLMs and address them w/ other solutions that might be better suited to handle them. And it works.
On the other side, we got our Kaleshi Paristons, who like to upend society for shits and giggles. Today, we’ll be covering one such group called VERSES AI, a team w/ strong roots in physics and neuroscience. They are advancing a radical thesis, born from first principles of physics and biology: that intelligence is not the passive recognition of statistical patterns. It is an active, goal-directed process of building and testing a causal model of the world to relentlessly minimize prediction error.
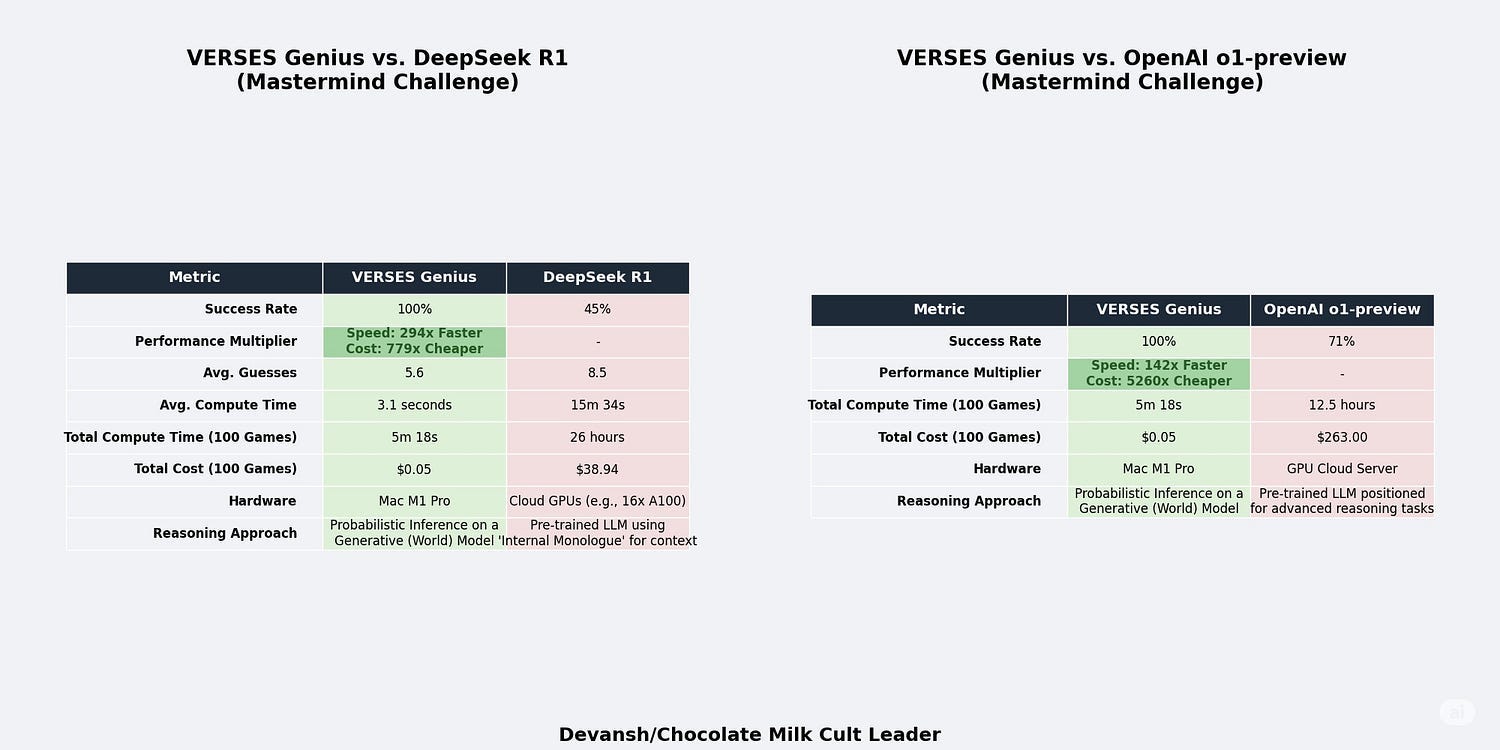
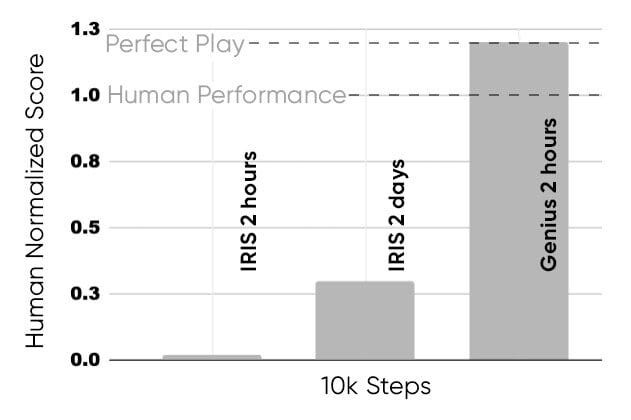
Big words, I know. We’ll break them down below. For now, we gawaars must satisfy ourselves with simpler numbers. In the code-breaking challenge, VERSES Genius proved to be 140 times faster and over 5,260 times cheaper than OpenAI’s o1-preview. Against DeepSeek R1, Genius demonstrated far greater reliability by achieving a 100% success rate compared to DeepSeek’s 45%, while also being nearly 300 times faster and 800 times more cost-effective. Some details are shared below —
Let’s look into how VERSES makes this happen and how their latest model, AXIOM, takes us even further, going from an impressive narrow use case to the ability to perform interactive reasoning and generalization across multiple games better than state-of-the-art deep RL models.
Executive Highlights (TL;DR of the Article)
Problem Statement: Deep learning agents, including LLMs and RL models, are brittle, opaque, compute-hungry, and incapable of true generalization. They simulate intelligence through statistical pattern-matching — not causal modeling, not goal-directed learning.
AXIOM’s Core Thesis: Intelligence is not learned via gradient descent over large datasets. It is built by minimizing prediction error through active world modeling. This is formalized through the Free Energy Principle — a physics-grounded theory of adaptive behavior — and implemented via Active Inference.
Architecture Summary:
sMM (Slot Mixture Model): Segments raw pixels into objects using Gaussian mixture models. Each object is a probabilistic hypothesis explaining part of the scene. This provides structure, interpretability, and sample efficiency.
iMM (Identity Mixture Model): Assigns type-level identity codes to each object (e.g., bomb, paddle). Enables generalization, shared dynamics, and robustness to perturbations (like color shifts).
tMM (Transition Mixture Model): Predicts object motion using a learned library of linear dynamics modes. Shared across all objects. Learns physics-like rules (e.g., bouncing, falling) without supervision.
rMM (Recurrent Mixture Model): Infers causal relationships and selects motion modes based on interaction context, action history, and reward signals. This is where temporal logic and state transitions live.
All modules are Markovian, probabilistic, and operate online — enabling fast, interpretable, and tractable belief updates.
Structural Intelligence:
Expansion: When existing components fail to explain data, new ones are created dynamically (new slots, new types, new modes).
Pruning (Bayesian Model Reduction): Redundant components are merged when doing so improves predictive power, allowing generalization from single events.
This makes AXIOM self-structuring — its complexity grows or contracts as needed, not arbitrarily.
Planning System:
Uses Model Predictive Control (MPC) to simulate multiple future action sequences.
Scores each based on Expected Free Energy: reward + information gain.
Refines policies using Cross Entropy Method (CEM) and executes only the first step, repeating the loop every frame.
Enables strategic, curiosity-driven action without relying on pre-learned policies or brute-force search.
Performance:
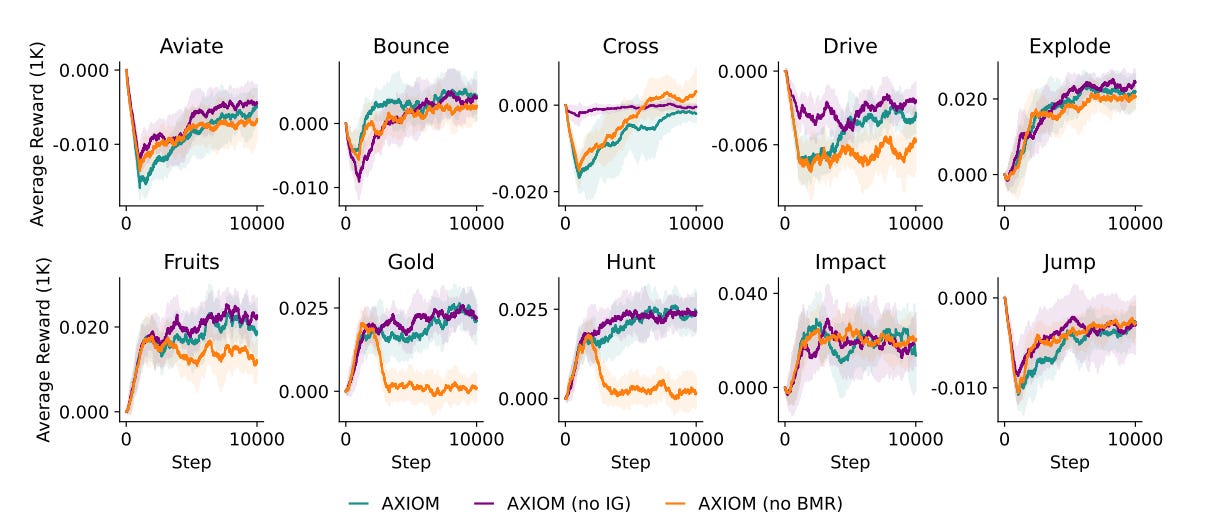
On the Gameworld 10k benchmark, AXIOM beats state-of-the-art deep RL systems using a fraction of the data, compute, and parameters.
Achieves human-level play within 10,000 frames, using a fully interpretable, modular model with only ~0.3–1.6M parameters.
Strategic Implications:
Doesn’t require GPU datacenters to train on massive datasets.
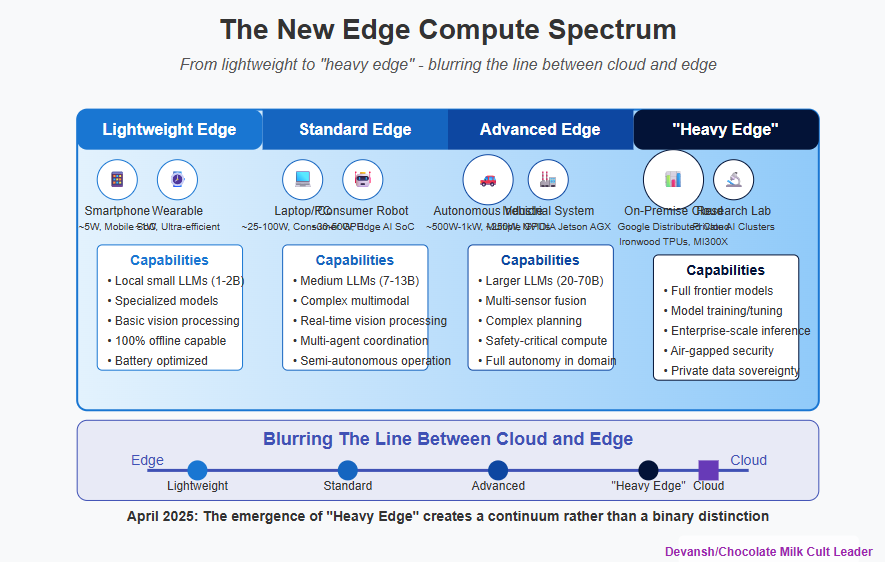
Runs in real time on edge hardware. While promising for all edge computing, I believe that VERSES’s approach is particularly well suited for Heavy Edge, where AI systems are run on powerful systems like NVIDIA Jetson AGX Thor or smaller compute servers with newer gen chips. These systems open up a whole new level of decentralization than before and many systems like traffic coordination, disaster rescue, network comms will benefit heavily from the increased intelligence available by having this be the “intelligence” layer behind the service.
Adaptable to environmental shifts with zero retraining.
Transparent by construction — no black box.
AXIOM is not a better version of deep learning. It’s a fully realized alternative: a cognitive architecture that builds understanding, infers cause, and rewires itself in response to the unknown. This is a new paradigm, one that models intelligence much more closely than neural networks. The importance of this is not to be underestimated.
Caption- In the video clip, we show how a robot decide to find its own way to get to the table because it can’t reach its target location without going around the sofa. By contrast, many traditional robotics approaches can’t “think” about alternative approaches, unless they have had specific training.
I put a lot of work into writing this newsletter. To do so, I rely on you for support. If a few more people choose to become paid subscribers, the Chocolate Milk Cult can continue to provide high-quality and accessible education and opportunities to anyone who needs it. If you think this mission is worth contributing to, please consider a premium subscription. You can do so for less than the cost of a Netflix Subscription (pay what you want here).

I provide various consulting and advisory services. If you‘d like to explore how we can work together, reach out to me through any of my socials over here or reply to this email.
Every month, the Chocolate Milk Cult reaches over a million Builders, Investors, Policy Makers, Leaders, and more. If you’d like to meet other members of our community, please fill out this contact form here (I will never sell your data nor will I make intros w/o your explicit permission)- https://forms.gle/Pi1pGLuS1FmzXoLr6
Section 2. The Free Energy Principle: Nature’s Law of Intelligence
Soooo, how does a small company deliver a beatdown of that magnitude to industry titans? They didn’t build a better GPU cluster. They started from a completely different blueprint for intelligence itself, one borrowed from biology and physics.
To understand it, you have to forget everything you know about deep learning. Stop thinking about backpropagation, gradients, and petabytes of training data. That’s the old religion. We will now only bow to one god, The Free Energy Principle. Let’s break it down.
Every self-organizing system — cells, brains, maybe even economies — survives by minimizing surprise. Not the cute kind. We’re talking thermodynamic surprise: the gap between what the system expects to sense and what it actually senses. This gap is called the Free Energy of the system. Let it get too big for too long, and the system dies.
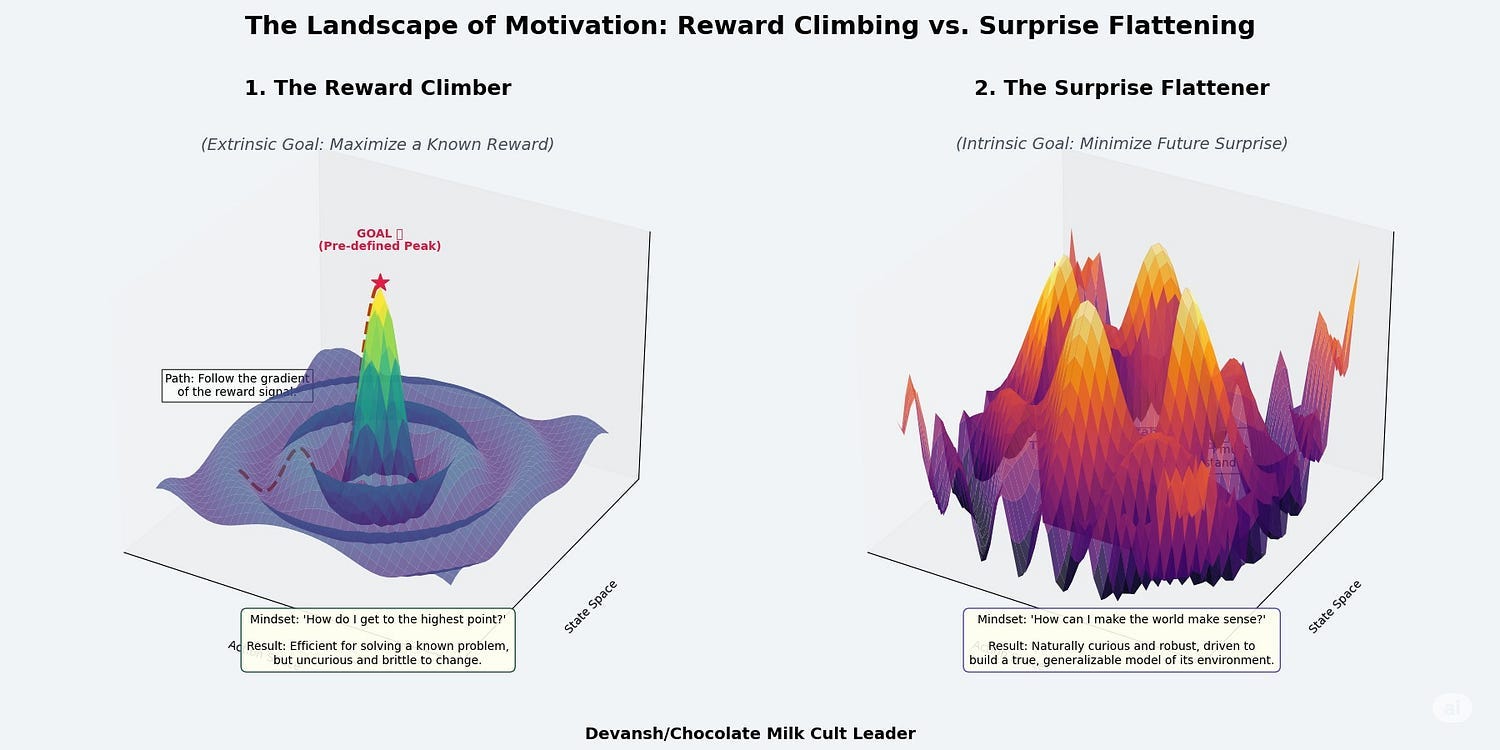
Think about why this makes sense before we proceed. A “surprise” (lots of free energy) is just a prediction error. It’s the gap between what your brain’s model of the world expects to happen and what your senses actually report. You expect the step to be there, but it isn’t. You expect the door to be unlocked, but it’s not. Surprise.
To keep surviving (and not look like an idiot), you have two ways to reduce this prediction error:
Change Your Mind (Perception): You can update your internal model to match reality better. “Arsenal will never win anything.” Your model is now more accurate.
Change the World (Action): You can perform an action to make reality conform to your model’s prediction. “I’m bored. Gambling, Cocaine, and Maximizing Shareholder Value sound like great ways to spend some time”.
It gets more interesting from here. When you think about it, perception and action are just two sides of the same coin: a continuous, aggressive feedback loop to ensure that your sorry internal model doesn’t follow you down the path of being a perpetual disappointment.
This sets our stage. Take a second to really internalize the principle, and then we will move on to its manifestation for VERSES.
What is Active Inference in AI
Active Inference is just the engineering that weaponizes this principle. Instead of training a network to memorize “this pattern = cat,” you build an agent that:
Maintains beliefs about hidden states in the world
Predicts what sensory data those states would produce
Compares predictions to actual sensations
Updates beliefs OR acts to reduce prediction error
Essentially, this is a model that never stops training. If we take that as an axiom, it should become clear why processes like backprop on trillion-param models become unviable. This method will also very quickly start to create richer representations of the world, something that even more sophisticated techniques like Knowledge Graphs don’t do well-
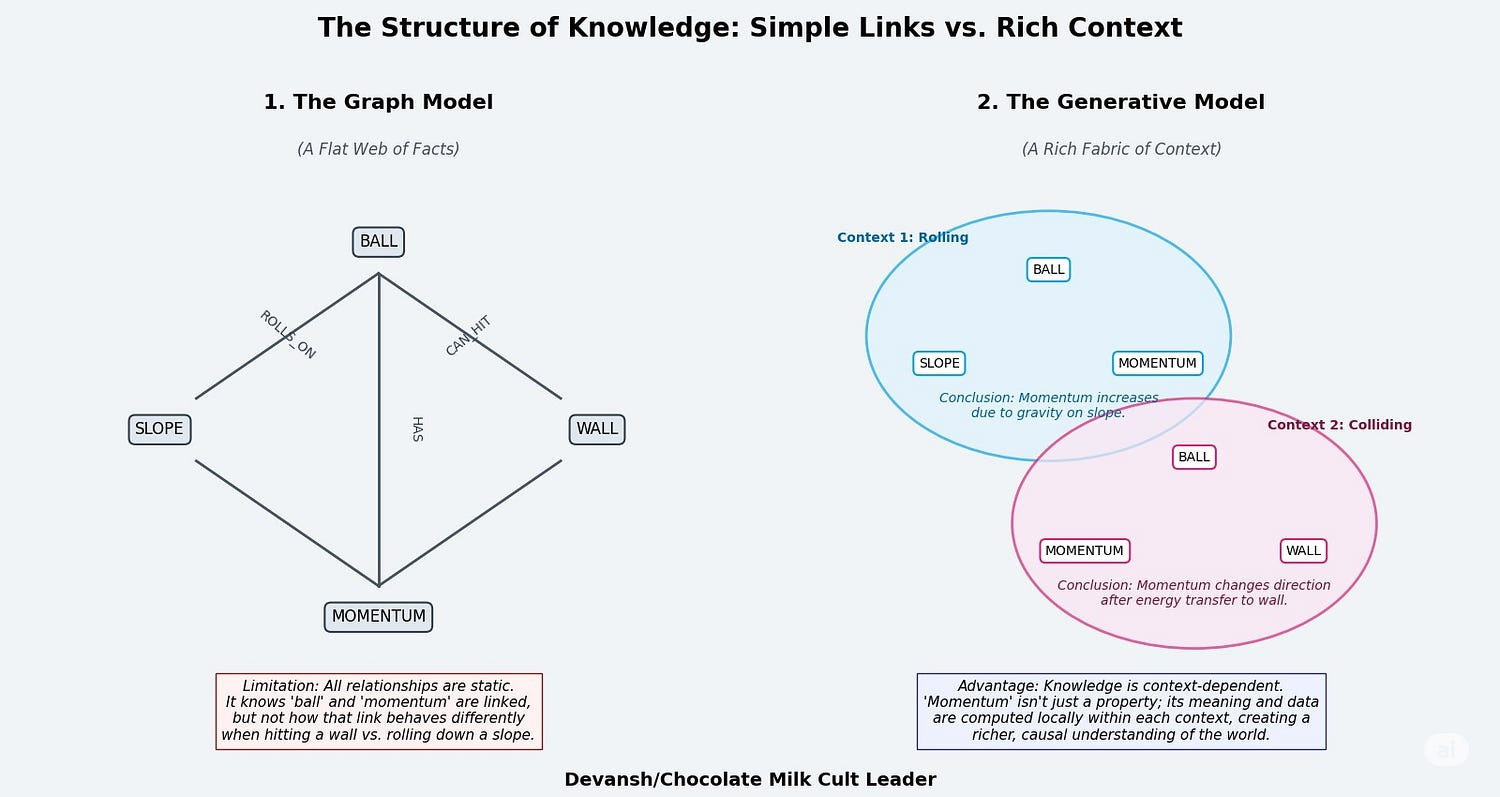
This design is also where true agency comes from. An LLM has no goals. It has no internal drive. It is a puppet waiting for a prompt. An Active Inference agent has a built-in, foundational purpose wired into its core: minimize future surprise. This intrinsic motivation forces it to explore, to test hypotheses, and to learn with ruthless efficiency, because in nature, wasting energy gets you killed.
This gives us several advantages-
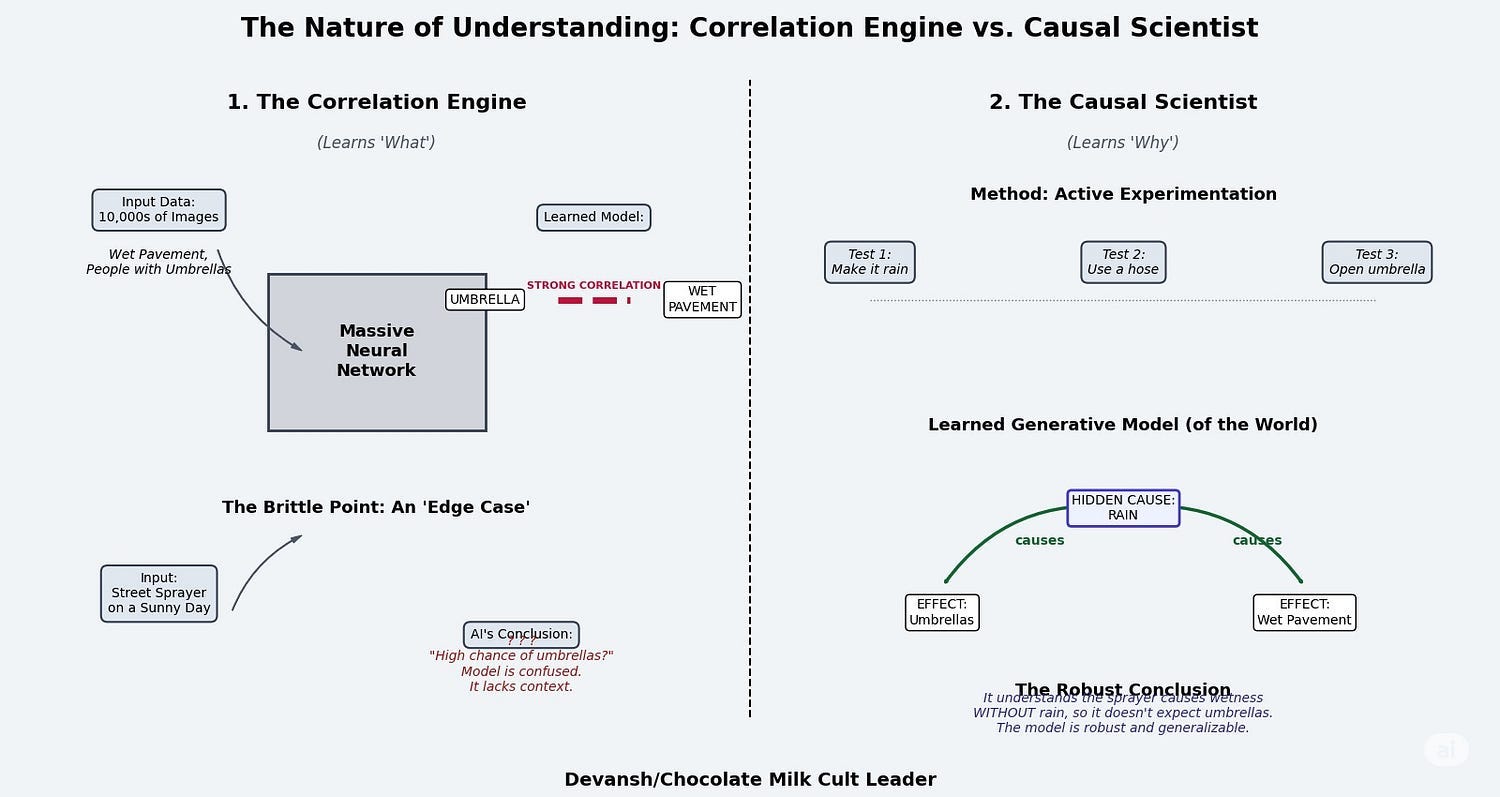
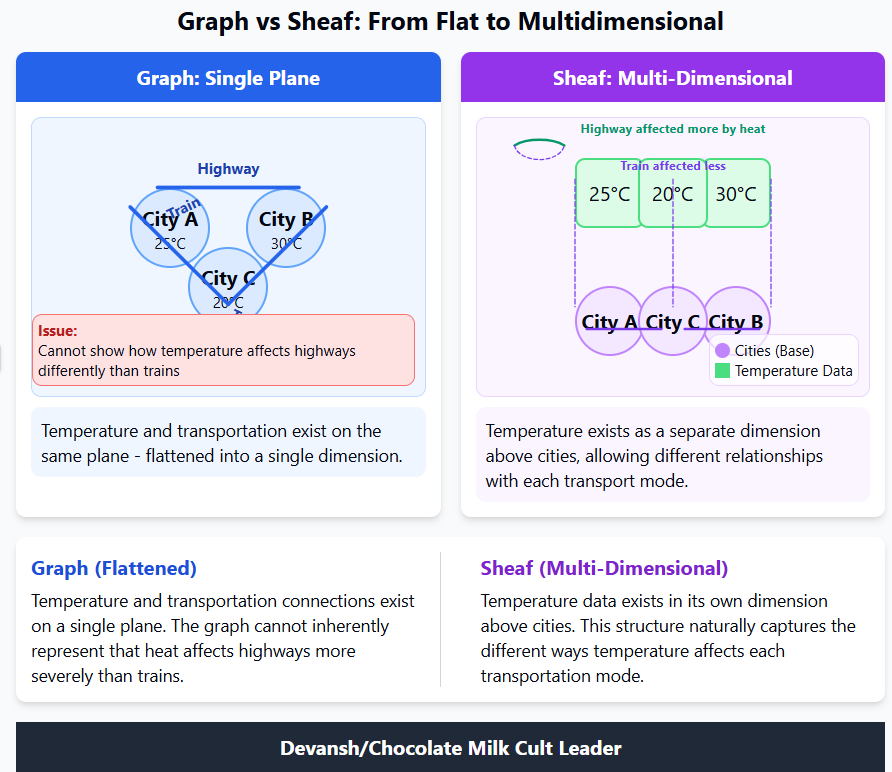
Causal Understanding: The agent learns “why,” not just “what.” It builds models of how things influence each other, not just correlation matrices. When it sees a ball roll, it learns about momentum and obstacles, not just pixel patterns. This processes creates inherently deeper relations and samples, allowing for more complex relationship modeling. Similar to show Sheafs have richer relationship modeling compared to Graphs.
Sample Efficiency: When you understand causation, you need way fewer examples. Like how you don’t need to see 10,000 chair variations to understand “thing you sit on.” VERSES’ agents learn Atari games thousands of game frames, not millions.
Actual Uncertainty: The agent maintains full probability distributions over its beliefs. When it says “70% confident,” that mathematically means something. Even when incorrect, the process of Active Inference means that the wrong prediction has more signal than analogous confidence predictions from Neural Networks, which are very delulu about their performance.
None of this comes free. The setup costs are high, and the ecosystem is still embryonic. VERSES had to build a no-code wrapper just to make it usable. But let’s not forget: the current paradigm isn’t ‘easy’ either. It just rides on trillions in sunk infrastructure. As that system nears its natural limits, we’d be stupid not to look for its antithesis. Active Inference isn’t just different — it’s leaner, more transparent, more decentralized. And if it works, it breaks everything
These ideas will serve as our “philosophical” underpinnings. Remember these well b/c the ideas we’re about to discuss can get very complex. Tying them back to these core principles will help us understand them better.
Aight, bois enough dilly-dallying. It’s time to break down the monster of the system that VERSES calls AXIOM — Active eXpanding Inference with Object-centric Models. As w/ a lot of AI Research, the team didn’t explain why they made certain guesses on why they chose to do something, so instead I’ll make that up. If you have more insight into this setup or alternative reasons, I’d love to hear to them.
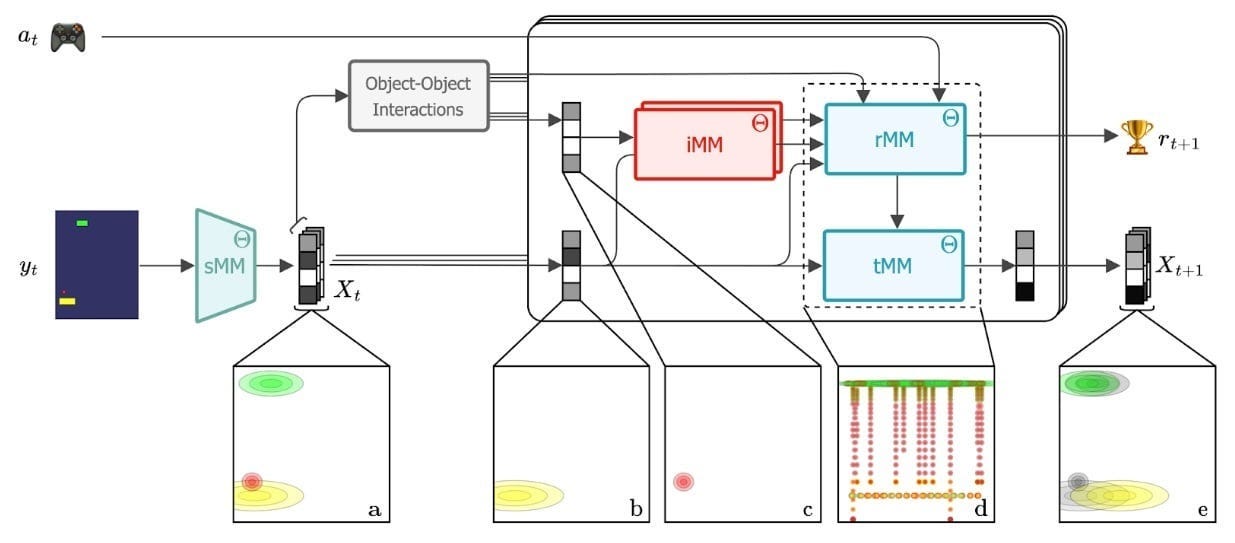
Section 3. AXIOM and How VERSES Delivers Intelligence
That image is… a lot, so get some water and we will take it down a peg, one idea at a time. I would normally quote the paper, but here is what it looks like-

I’m not cherry picking a mathy section. The next part is this-

and it goes on and on and on….
So instead we’re going to use our own words.
Section 3.A: Architecting Perception with The Slot Mixture Model (sMM)
Before an agent can reason, plan, or act, it must see. It must impose structure on raw sensory data. It must carve the world into discrete, persistent entities that can be tracked, predicted, and eventually controlled. This is where all intelligence begins: in object-centric perception.
The Slot Mixture Model (sMM) is AXIOM’s solution to this foundational challenge. It’s the system’s perceptual cortex, built not with convolutions or transformers, but with an unsupervised probabilistic competition for explanatory power. There are no labels, no gradients, no pretraining. Just a stream of pixels and a Bayesian imperative: explain what you see; or be replaced.
The Core Insight: Intelligence Requires Objects
AXIOM goes beyond pixels. It makes a fundamental bet about the nature of reality: What you see on screen is generated by a small number of coherent, persistent objects moving and interacting over time. It treats the visual world as a mixture of these hidden causes.
Deconstructing the sMM’s Intellectual Machinery
To understand the sMM, we must understand its two core mathematical tools.
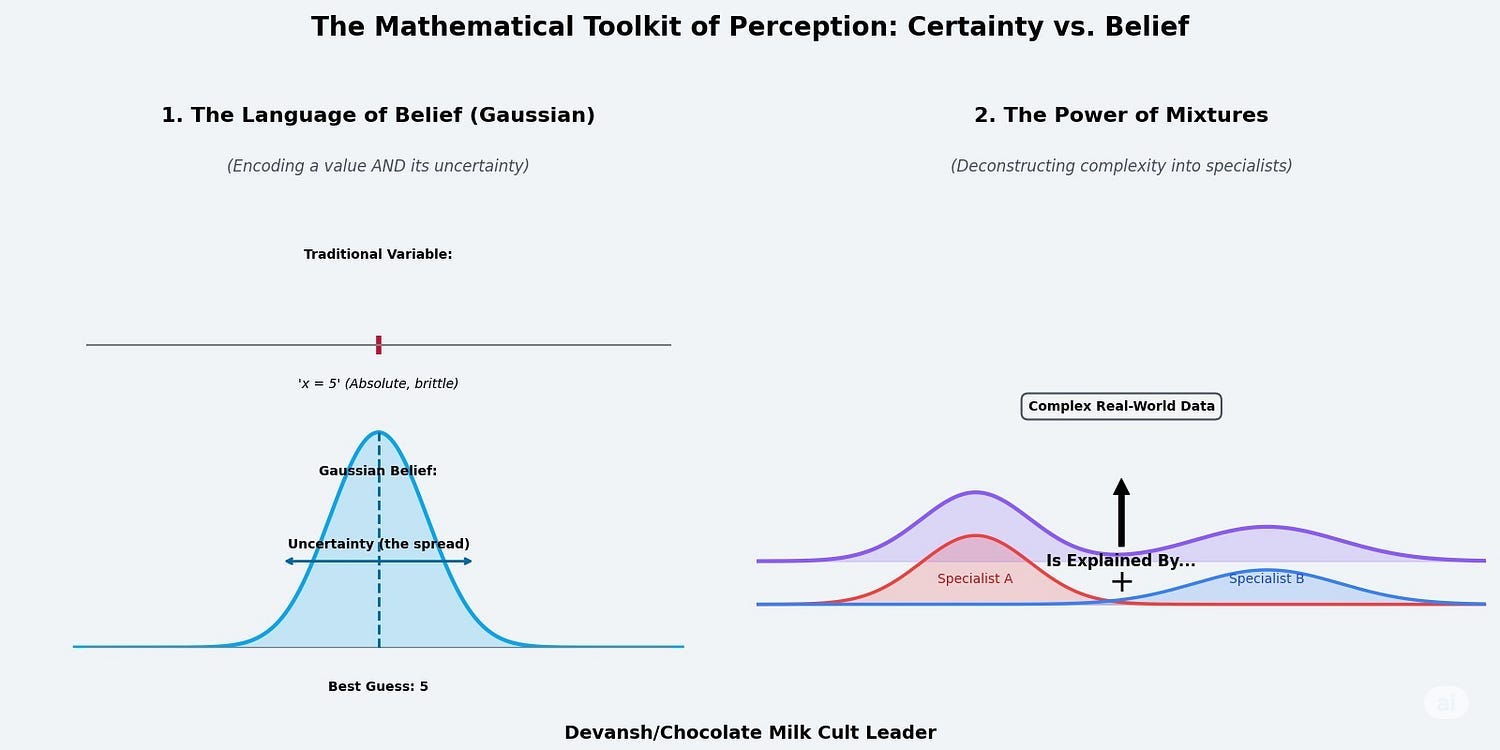
The Gaussian Distribution: The Language of Focused Belief: A Gaussian/Normal, or “bell curve,” is the mathematical embodiment of a precise but uncertain belief. A traditional variable says x = 5. It is absolute. A Gaussian variable says, “My best guess is that x is 5 (the peak of the curve), but I acknowledge it could be 4.9 or 5.1 with some probability. It’s very unlikely to be 2 or 8.” It encodes not just a value, but a central tendency and a degree of uncertainty (the width of the curve).
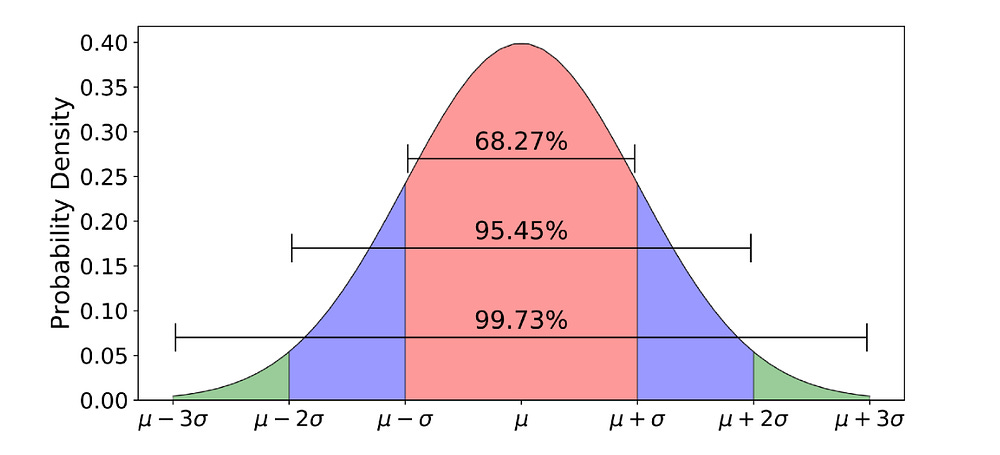
Gaussians are the native language of any system that has to make predictions based on incomplete information (all IRL systems). In AXIOM, a “slot” (the representation of an object) is fundamentally a set of Gaussian distributions describing its believed properties: its position, color, shape, etc.
The Mixture Model: The Power of Competitive Specialization.
A Mixture Model is an elegant solution to complexity. Imagine multiple probability distributions (like bell curves) mixed together. A MM can represent complex shapes for real-world data that isn’t perfectly described by a single type of distribution. It works on the assumption that any general distribution can be broken down into a mixture of normal distributions. For eg. this distribution

can be represented as the sum of the following distributions
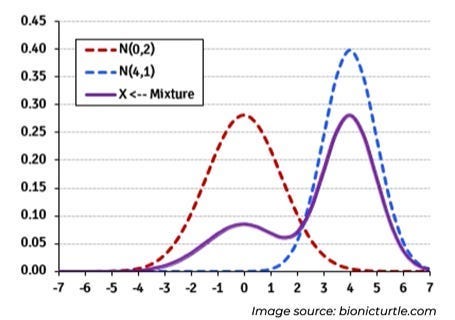
You can see how this would be useful when dealing with very complex/layered distributions.
Combine these two ideas, and you get the Gaussian Mixture Model (GMM): a team of specialists where each specialist’s model is a Gaussian distribution.
Next, we will talk about how this works in practice.
The sMM in Action: A Generative Battle for Pixels
AXIOM receives a frame: say a 210×160 RGB image. It reshapes this into a list of ~33,600 pixels, each encoded as a 5D vector:
Red, Green, Blue values
x, y position (normalized spatial coordinates)
Now comes the slot competition.
Each object slot in AXIOM contains a structured continuous latent vector with interpretable features: position, color, velocity, shape, and an unused counter.
The Slot Mixture Model (sMM) uses a subset of these — position, color, and shape — to explain pixel observations via a Gaussian mixture. The other features (like velocity and unused counter) are used downstream in dynamics modeling and gating, not by the sMM itself.
Each slot uses these beliefs (which are technically Gaussian distributions) to generate a prediction: “If I exist, this is what the pixels caused by me should look like.”
For example, Slot A might be defined by these beliefs:
Position: “I’m 80% certain I’m in the top-left quadrant.”
Color: “I’m 95% certain I am reddish-brown.”
Shape: “I’m 90% certain I am vaguely spherical.”
Slot B will hold its own, different set of beliefs.
Now, the generative battle begins. The sMM takes its hypothetical objects and projects them back into the image space.
“If a reddish, spherical Object A exists in the top left, and another Object B exists over there… what should the whole image look like?”
The sMM then compares these predictions against the actual image. For each pixel, it evaluates which slot’s prediction was a better match. The pixels in the top-left are well-explained by Slot A’s reddish, spherical prediction — so Slot A is assigned higher responsibility for those pixels.
(Important note- Each pixel isn’t hard-assigned to a single slot. Instead, the sMM infers a soft responsibility distribution over slots — reflecting which hypotheses best explain that pixel, and by how much)
The result is a soft, complete segmentation of the scene: every pixel is assigned probabilistic responsibility across all slots, transforming raw pixels into a structured interpretation grounded in object-centric hypotheses.

This entire process — hypothesize causes, generate predicted effects, compare with reality, assign responsibility — leads to two profound consequences:
Ludicrous Efficiency: AXIOM is not learning pixel patterns. It is learning the parameters of a handful of Gaussians. As the paper states, this operates “without the computational expense of gradient-based optimization.” AXIOM learns a new game from just 10,000 interaction steps because it’s learning a compact model of the world’s underlying structure, not a bloated map of its surface features. The model size is 400x smaller because the problem it is solving is fundamentally simpler and more correct.
Inherent Plasticity: What happens when a new, unforeseen object appears? The paper reveals the sMM is built using a “truncated stick-breaking prior.” In plain language, this means the model has a built-in mechanism for deciding when none of its existing specialists can adequately explain a new piece of data. When this happens, it has the authority to instantiate a new slot on the fly. It says, “None of my existing K objects can explain this new red thing. I hypothesize the existence of a (K+1)th object and will now model it.” This gives the system the ability to dynamically grow its own complexity to match its environment.
The sMM is the foundation of AXIOM’s worldview. It delivers a clean, structured, object-centric universe upon which true reasoning can begin.
Section 3.2 Engineering Time, Memory, and Causality
The sMM provides the nouns — a clean, structured universe of objects. This is a monumental first step, but it is static. It’s a snapshot. To be intelligent, an agent must move from perception to process — from what is to what happens. It needs verbs. It needs grammar. It needs to model process.
After all, how else will it answer questions like is this red circle a harmless fruit, or a falling bomb? Does this square bounce or roll? What happens when this triangle collides with a wall? These questions can’t be answered by raw position or pixel color alone. They require type-level understanding — a generalizable label that links appearance to expected behavior.
Let’s understand the importance of this.
The Motivation: Why Identity Matters
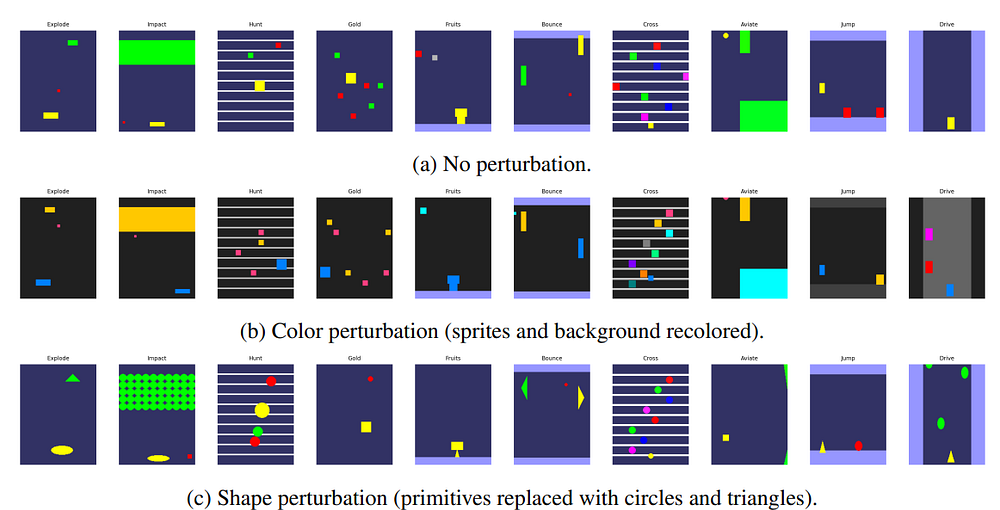
Let’s say you’ve learned that red spheres bounce and green cubes explode. Now a new red sphere appears on screen. If your system treats this as a completely new object — one requiring fresh motion learning and reward mapping — you’ve thrown away everything you already knew.
Worse: what happens when the red sphere turns blue mid-game due to a visual glitch or lighting shift? Should it be treated as an entirely new object?
This is what naive models do. They overfit to instance-level features and break under slight perturbation.
AXIOM doesn’t fall into this trap. It uses iMM to create identity codes: compact, generalizable labels that cluster objects with similar structural properties. These identity labels allow the agent to:
Reuse learned dynamics and reward models across instances
Remap perturbed objects to known categories
Reason abstractly about “type of thing” rather than “exact thing”
This is not hardcoded logic. It is probabilistic memory, learned from the world itself.
To accomplish its remarkable intelligence, Axiom operates on a simple but powerful premise about the nature of time that we must understand before going onward.
Understanding The Markovian Process
A Markovian Process is a type of stochastic (random) process where the future state of a system depends only on its current state, not on its entire history. The “memorylessness” of the process simplifies its modeling-
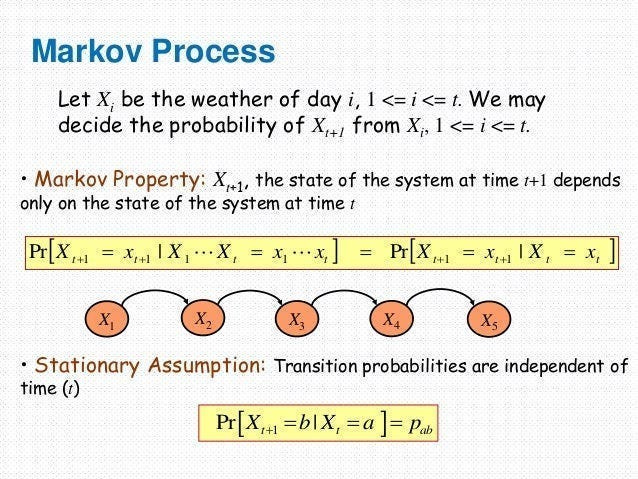
Imagine a Mario Game. As long as two different game instances have identical coins, powerups, health bars, locations, timers, and other stats- the journey you took to get to that point is irrelevant. Where you go/what you can do from that point on is also fixed, making those two points functionally identical- even if you took very different journeys to get there.
Markovian Processes are very cool b/c a lot of extremely complicated processes can be simplified into MPs.

From this foundation, we build Markov Decision Processes (MDPs) — the mathematical framework behind reinforcement learning. MDPs extend Markov Processes by adding 3 crucial elements:
Actions: An agent can make choices that influence state transitions
Rewards: Each state-action pair yields a reward signal
Discount Factor: Future rewards are worth less than immediate ones
This is the operating system AXIOM runs on. The modules that follow the sMM are an engineering stack designed to learn the rules of transition from State_t to State_t+1.
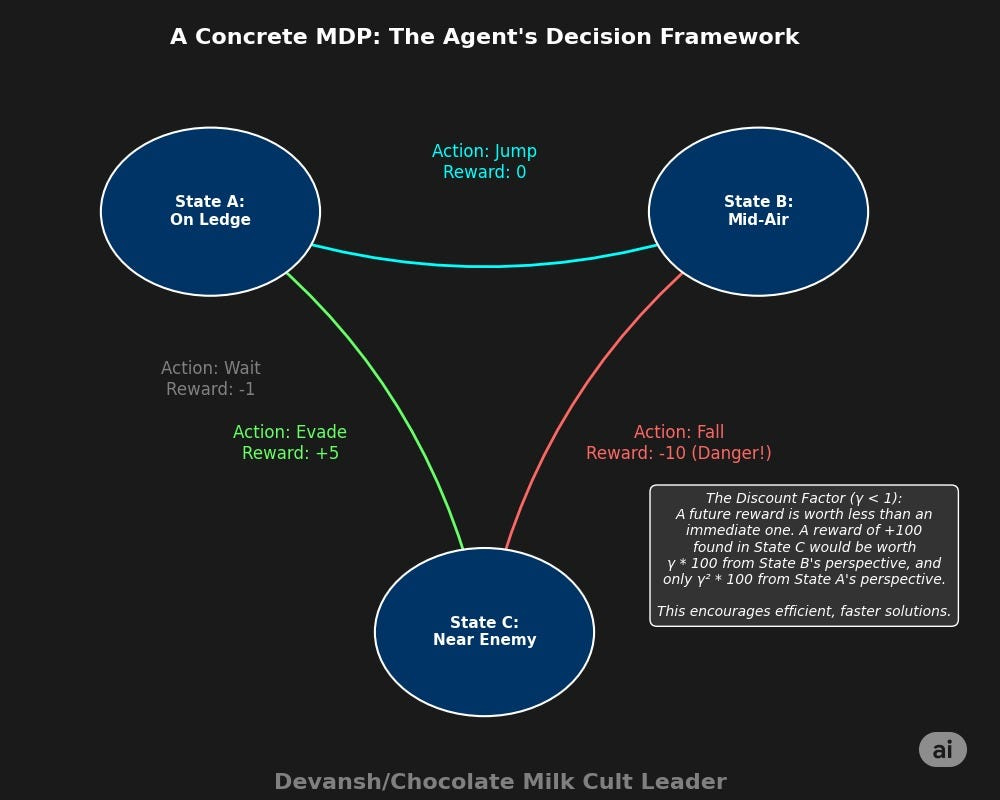
Having understood the foundations, the various AI blocks becoming a bit clearer.
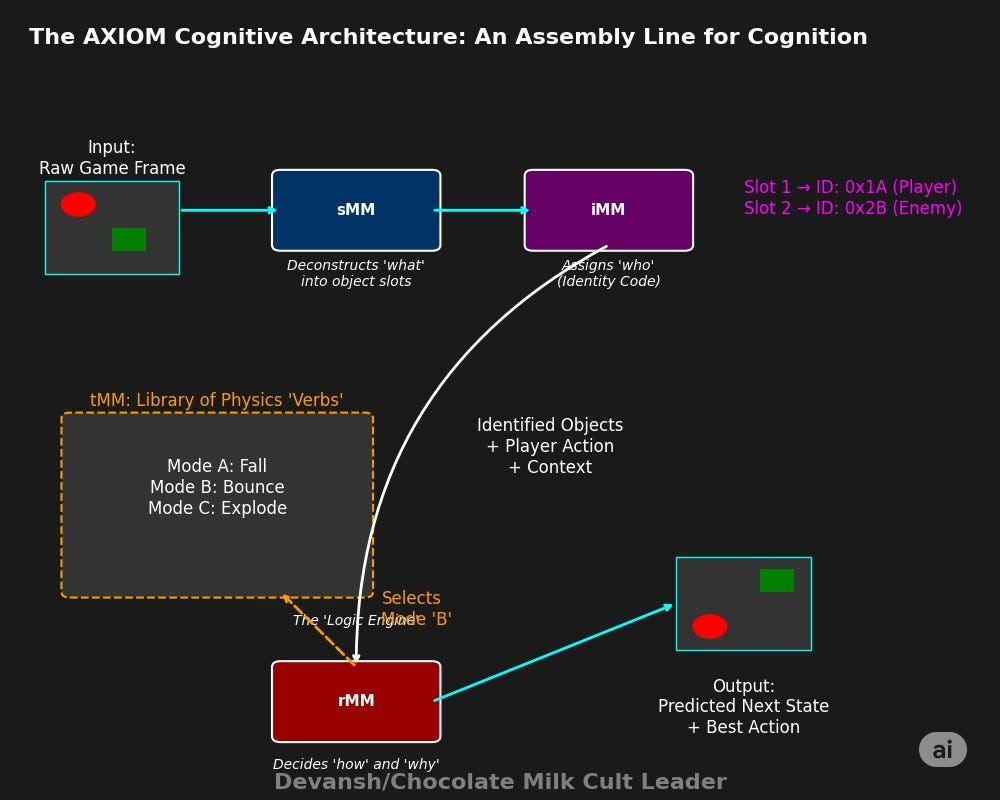
1. Identity & Memory (The iMM — Identity Mixture Model)
The Problem It Solves: In a Markovian flow, the “present state” must include not just what objects exist, but which object is which over time. Is the red ball you see now the same red ball you saw two seconds ago, even if it was briefly hidden behind a wall? This is the problem of object permanence and identity.
The Mechanism: The iMM functions as AXIOM’s memory cortex. The AXIOM paper explains that it analyzes the continuous features of each object slot (its color, its shape) and assigns it a discrete “identity code.” This allows it to learn “type-specific” dynamics. So, instead of learning one model for “red ball #1” and another for “red ball #2,” it learns a single, highly generalizable model for the type “red ball” (which is how we classify things too).
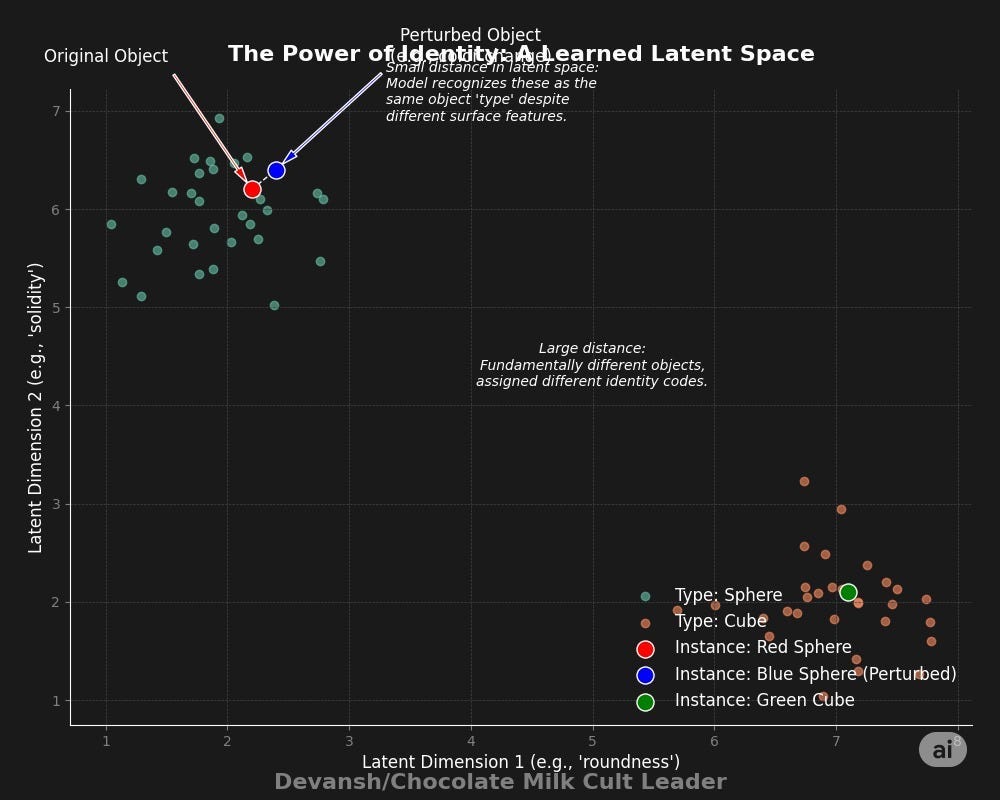
The perturbation experiments prove this works: when an object’s color is changed mid-game, the iMM, once it adapts, can remap the object back to its original identity based on its persistent shape, allowing the agent to instantly recover its old knowledge about how that object should behave.

2. Dynamics & Prediction (The tMM — Transition Mixture Model)
The Problem It Solves: Once an object is identified, how does it move? What are the fundamental “verbs” of this physical world?
The Mechanism: The tMM is AXIOM’s physics engine, but one it builds itself. The paper describes it as a “switching linear dynamical system” (SLDS), which is a way of saying it learns a shared library of motion prototypes. Think of it as discovering the basic physical laws of its environment: mode_1 = ‘is_falling’, mode_2 = ‘is_bouncing’, mode_3 = ‘is_stationary’.
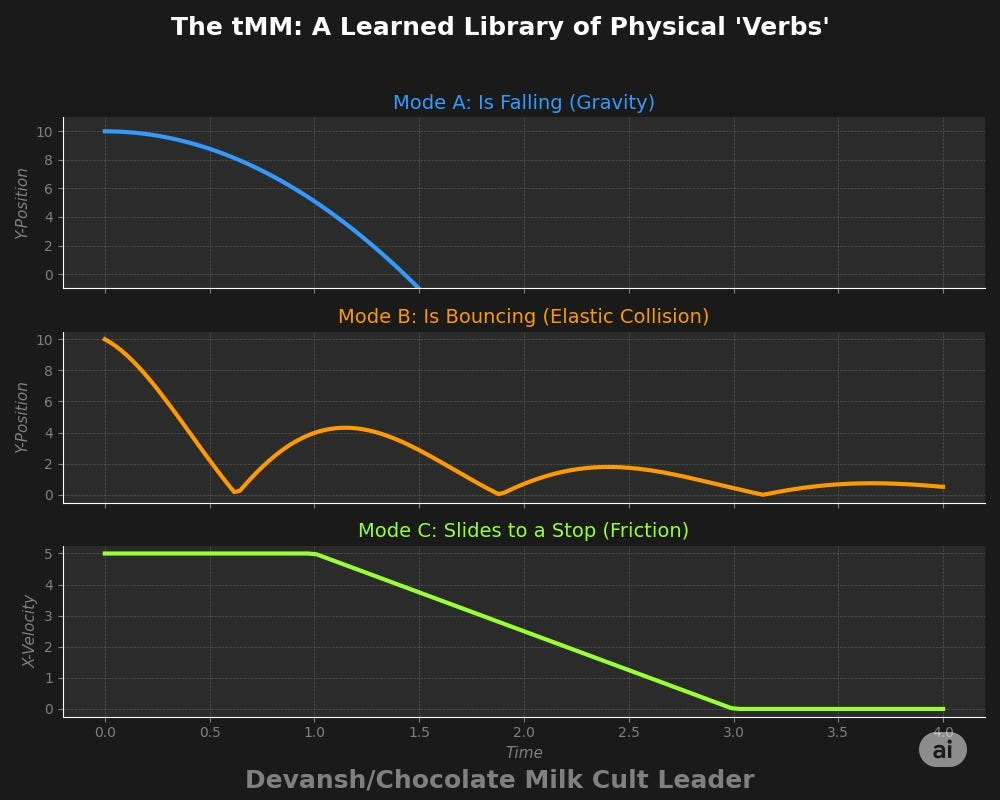
Each “mode” is a simple mathematical rule describing a transition from state_t to state_t+1. Because this library of verbs is learned once and shared across all objects, the model doesn’t need to relearn the concept of “falling” for every new thing it encounters. Both the utility in computational efficiency and real-world analogies should be fairly clear here.
3. Logic & Context (The rMM — Recurrent Mixture Model)
The Problem It Solves: This is the executive brain, the prefrontal cortex of the machine. It looks at the full picture and decides which verb from the tMM applies right now. A ball in mid-air is falling, but the instant it hits the floor, its mode must switch to bouncing. What governs this switch? Context.
The Mechanism: The rMM is the logic engine that makes the critical state-transition decision. It is the most sophisticated module in the stack. The paper details that the rMM infers the correct tMM mode by conditioning its decision on everything that matters:
The object’s own current state (position, velocity).
Its interaction with the nearest object (distance, identity).
The action the player just took.
The reward that was just received
It learns the deep, contextual, causal syntax of the game: “Given the present state where my_action = jump AND distance_to_enemy < X AND enemy_type = spiky, then the most probable transition to the next state is one governed by the dying dynamic.”
B/c this uses a generative mixture model instead of a NN/other AI for modeling, the joint distribution that it creates has more “range”, allowing it to generalize motion patterns, adapt to new environments, and even grow new motion hypotheses on the fly when needed.
The Inevitable Consequence: This explicit, causal reasoning is why VERSES Genius achieves 100% accuracy on the Mastermind challenge. Because the rMM has constructed an actual logical model of the game’s rules and can flawlessly execute its Markovian state transition, something that the more unreliable LLMs are incapable of.
This hierarchical stack — from iMM to tMM to rMM — is a functional assembly line for cognition. It takes the object-centric world from the sMM and subjects it to the logic of time, building a predictive, causal model of its environment from the ground up.
Section 3.3: Structural Intelligence — Growth, Compression, and Control
AXIOM doesn’t just run a fixed model. It grows a brain. It rewires itself. It decides what new knowledge to absorb and what old complexity to discard. And it uses that evolving model to simulate possible futures — then selects actions that minimize future surprise.
Neural networks grow by stacking layers. Transformers scale by adding billions of parameters. AXIOM grows by accumulating structure — new components only when needed, compressed when redundant, all in service of one goal: Model the world precisely enough to act inside it.
That process has three pieces:
Expansion — When the world changes
Pruning — When the world simplifies
Planning — When the world demands action
Let’s break them down.
1. Expansion: Learning What Doesn’t Fit
Every mixture model in the system — sMM, iMM, tMM, rMM — is designed to expand itself as needed. This is operationalized through a stick-breaking prior — a Bayesian mechanism that allows the system to weigh:
“Can I explain this input using existing components?”
“Or do I need to invent a new one?”
This applies across the architecture:
A new visual pattern that doesn’t fit existing object slots? → sMM grows a new slot.
A new combination of color + shape not matching known types? → iMM adds a new identity.
A new trajectory of movement unseen before? → tMM spawns a new dynamics mode.
A new interaction with unfamiliar outcomes? → rMM adds a new causal cluster.
But growth is not triggered by “newness” alone. It’s triggered when the predictive error of existing components is too high — when the system is consistently surprised.
This is the antidote to neural overfitting. It’s why AXIOM can adapt in 10,000 steps where LLM-based agents still flail.
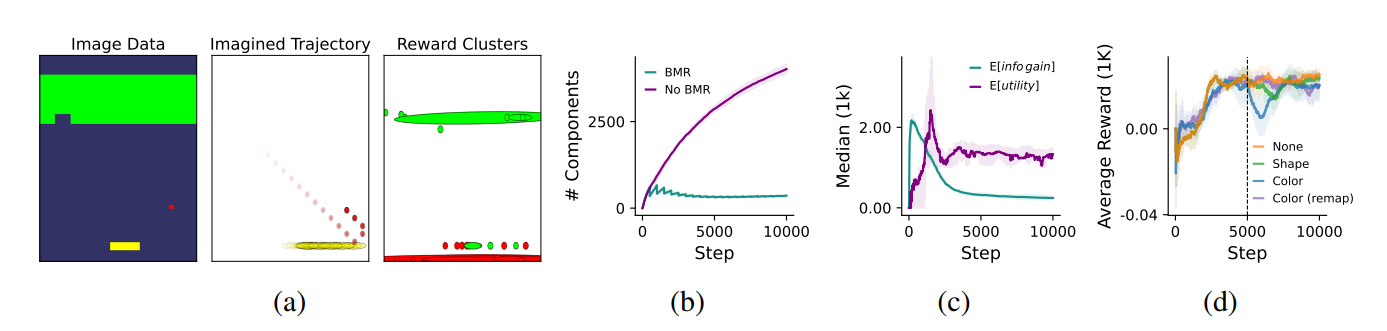
2. Pruning: Compressing What’s Redundant
Growth brings power. But ungoverned growth is entropy.
To stay efficient and generalizable, AXIOM periodically prunes its model using a process called Bayesian Model Reduction (BMR). It does this every few hundred frames — just enough time to accumulate experience, not so much that it forgets why it grew.
The goal is simple: Merge similar components only if doing so improves the model’s ability to explain the future. Here’s how it works:
It samples real experience from recent gameplay.
It selects pairs of components in the rMM (e.g., “Causal Cluster A” and “Causal Cluster B”).
It simulates what would happen if those components were merged — does the combined model predict rewards and transitions better or worse?
If the merged version performs better — or is just as good but simpler — it replaces the originals.
Take an example. It might try merging “getting hurt when red ball #1 hits the floor” and “getting hurt when blue square #2 hits the floor” into a single rule of “things hitting the floor are punished”. If this ups performance, the merge is accepted.
This allows AXIOM to:
Generalize from a small number of events (“Every time I hit this bottom wall, I die” → One reusable rule). It will also have a more accurate understanding of it’s confidence/capabilities/certainty, enabling intelligent training.
Prevent drift by discarding outdated complexity
Stay small without sacrificing expressiveness
Since the system simplifies itself only when the simplified explanation has greater explanatory power, it avoids the randomness associated with gradient-based regularization.
3. Planning: Choosing Action with Simulated Futures
Now we get to the payoff: what AXIOM does with all this structure.
While traditional RL agents fumble through exploration or rely on precomputed value functions, AXIOM plans its actions by simulating futures and choosing the one that best balances reward and understanding. Our agent tries to minimize the expected value of the free energy of the system through intelligent policy selection.
Roll out multiple hypothetical sequences of actions (policies)
For each one, simulate how the world will evolve under the current model
Score each trajectory on two fronts:
Expected reward (will I get points?)
Information gain (how much will I learn?)
Pick the policy that reduces both surprise and ignorance
Technically, this is done using a variant of Model Predictive Control (MPC). AXIOM samples action sequences, rolls them out in its internal world model, and iteratively refines its policy distribution over time using Cross Entropy Method-style updates.
Because the model is Markovian and fully factorized, this planning is fast, tractable, and local — no GPU farms, no replay buffers.
Why This Is Structurally Different from Deep RL
RL agents memorize reward associations and hope the environment doesn’t change too much.
AXIOM does the opposite:
If the world changes, it rewires itself.
If the world repeats, it compresses and generalizes.
If the world is unknown, it tests hypotheses and learns what matters.
All of this makes it a natural fit with Edge Computing (and it’s no surprise that VERSES is being piloted in Abu Dhabi’s smart city initiative).
Conclusion: Toward Systems That Think
The last decade of AI has been dominated by a single intuition: scale the model, scale the dataset, and the behavior will follow. And it worked — until it didn’t. We got fluent simulators of language and vision. But we didn’t get agency. We didn’t get understanding. We didn’t get systems that could adapt in real-time, generalize causally, and reason under uncertainty.
AXIOM does all three.
This isn’t because of a clever trick or a new loss function. It’s because the system was built from a different substrate. It doesn’t memorize reward associations. It models the world. It doesn’t rely on hand-tuned heuristics. It restructures itself. And it doesn’t wait for surprise. It predicts, tests, and updates in every frame.
I’ve been playing with the idea that intelligence might not be a function of LLM size but mathematical structure. Perhaps, God is a Fractal.
Weird tangents aside, it’s quite ironic that all our investments in AI have not created a commensurate impact on our understanding of intelligence. Alternative paths like the one followed by VERSES can fix that. By rethinking our assumptions on what it means for systems to be intelligent, one hopes that we learn a bit about ourselves and what it means to be intelligent. Especially when the paradigm is biologically inspired and auditable.
Check VERSES out and let me know what you think of their approach.
Thank you for being here, and I hope you have a wonderful day.
Whose your favorite HxH character? (mine is Hisoka),
Dev <3
If you liked this article and wish to share it, please refer to the following guidelines.
That is it for this piece. I appreciate your time. As always, if you’re interested in working with me or checking out my other work, my links will be at the end of this email/post. And if you found value in this write-up, I would appreciate you sharing it with more people. It is word-of-mouth referrals like yours that help me grow. The best way to share testimonials is to share articles and tag me in your post so I can see/share it.

Reach out to me
Use the links below to check out my other content, learn more about tutoring, reach out to me about projects, or just to say hi.
Small Snippets about Tech, AI and Machine Learning over here
AI Newsletter- https://artificialintelligencemadesimple.substack.com/
My grandma’s favorite Tech Newsletter- https://codinginterviewsmadesimple.substack.com/
My (imaginary) sister’s favorite MLOps Podcast-
Check out my other articles on Medium. : https://rb.gy/zn1aiu
My YouTube: https://rb.gy/88iwdd
Reach out to me on LinkedIn. Let’s connect: https://rb.gy/m5ok2y
My Instagram: https://rb.gy/gmvuy9
My Twitter: https://twitter.com/Machine01776819
Thank you very much for this detailed and technically rich overview.
I usually explore Active Inference and the Free Energy Principle through podcast interviews with Karl Friston, which tend to focus on the more philosophical and abstract dimensions of the topic. That’s why I find it genuinely fascinating to see that these abstract and often hard-to-grasp explanations of what mind and intelligence are might soon be brought to life through technology.
If this truly turns out to be the case, then what Verses is working on might not just be another advancement, it could mark the beginning of an entirely new era in our understanding and development of intelligence.
Thanks for this - fantastic breakdown.
It's so nice to finally see an approach that better models actual intelligence by having an internal world-model rather than just probabilistic generation. The implications and potential are pretty massive.
For example, if you were to apply the AXIOM approach to language (which seems possible - words and sentences as objects, grammar as verbs, etc.), it might mostly or completely eliminate hallucinations. But it might not work as well as LLMs for many genAI tasks because the goal to minimize surprise means it would likely not have much variation/creativity. But it might provide a valid alternative for RAG, where creativity is often not the desired result.
Anyway, speculation aside, it appears there's a current limitation in how AXIOM learns:
"Our work is limited by the fact that the core priors are themselves engineered rather than discovered autonomously. Future work will focus on developing methods to automatically infer such core priors from data, which should allow our approach to be applied to more complex domains."
So, before AXIOM can begin learning about the world, you have to build a base world model which acts as the prior, and then it builds on that.
It will be extremely interesting to see what kinds of novel and bespoke applications open up when it can begin learning completely from scratch.