


How DeepMind Built AI That Evolves Itself [Breakdowns]
From speeding up matrix multiplication to compiler optimization, Google AI's AlphaEvolve shows how discovery is becoming an engineered process.

It takes time to create work that’s clear, independent, and genuinely useful. If you’ve found value in this newsletter, consider becoming a paid subscriber. It helps me dive deeper into research, reach more people, stay free from ads/hidden agendas, and supports my crippling chocolate milk addiction. We run on a “pay what you can” model—so if you believe in the mission, there’s likely a plan that fits (over here).
Every subscription helps me stay independent, avoid clickbait, and focus on depth over noise, and I deeply appreciate everyone who chooses to support our cult.
PS – Supporting this work doesn’t have to come out of your pocket. If you read this as part of your professional development, you can use this email template to request reimbursement for your subscription.
Every month, the Chocolate Milk Cult reaches over a million Builders, Investors, Policy Makers, Leaders, and more. If you’d like to meet other members of our community, please fill out this contact form here (I will never sell your data nor will I make intros w/o your explicit permission)- https://forms.gle/Pi1pGLuS1FmzXoLr6
2 days ago, Google DeepMind dropped the publication- “AlphaEvolve: A Gemini-powered coding agent for designing advanced algorithms”. The process goes far beyond another Agentic System- it hints at what automated scientific discovery will become once we can use powerful Language Models to create reward signals, scoring functions, and an automated evaluator.
AlphaEvolve quietly solves a core challenge in AI R&D: how to turn raw model intelligence into iterative, verifiable improvement without human micromanagement. It doesn’t summarize code, it evolves it- mutating entire programs through a feedback loop of execution, evaluation, and selection.
The results are staggering-
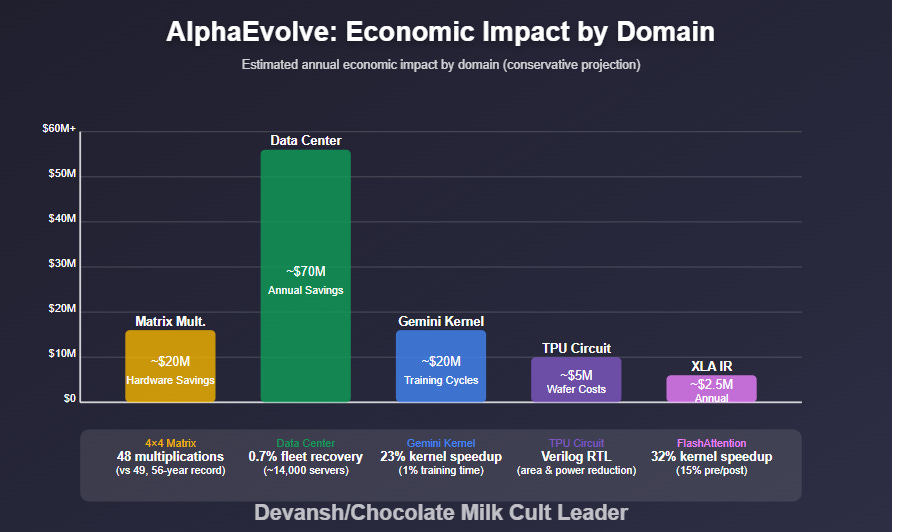
Matrix Multiplication (4×4 complex, 48 mults): AlphaEvolve broke a 56-year-old barrier in linear algebra by discovering a faster 4×4 matrix multiplication algorithm. A direct 2% gain seems niche, but across large-scale training and infrastructure, it could translate into $150K–$500K per model and $ 20 M+ in deferred hardware costs if widely adopted.
Mathematical Problems (Kissing Number, Erdős): AlphaEvolve matched or beat the state-of-the-art in ~20% of 50+ open mathematical problems, including improving the 11D kissing number. The immediate impact is intellectual, but the real signal is the emergence of AI as a collaborator in abstract theoretical research.
Google Data Center Scheduling (0.7% recovery): By evolving a better scheduling heuristic, AlphaEvolve reclaimed ~0.7% of compute across Google’s fleet, equal to 14,000 servers. That’s an estimated $42M–$70M per year in capacity savings, without touching hardware or deployment logic.
Gemini Kernel Optimization (1% training time cut): AlphaEvolve redesigned critical kernels for Gemini, achieving a 23% kernel speedup and reducing total training time by 1%. This saves $500K–$1M per training run, with additional multi-million-dollar impact across repeated fine-tuning cycles and compressed engineering timelines.
TPU Circuit Optimization (Verilog): AlphaEvolve optimized RTL-level Verilog to reduce area and power in TPU arithmetic units. Even a 0.5–1% gain here can save $5M+ in wafer costs and $150K–$300K annually in power, while accelerating hardware iteration and verification loops.
XLA IR Optimization (FlashAttention): By modifying compiler-generated IR code, AlphaEvolve achieved a 32% kernel and 15% pre/post speedup for FlashAttention. At Google’s scale, this can translate to $1M–$2.5M per year in inference savings and sets the precedent for AI-augmented compiler-level optimization.
(to check specific calculations and assumptions, you can see our appendix , which has a detailed breakdown of the methodology. Comments always welcome).
Given the wide-reaching implications of this, our usual table of impacts will not be particularly useful. However, I would like to mention that this heavily tilts the balance of scientific discovery towards rich organizations. This can have very worrying implications since it can severely increase inequality and worsen the balance of power b/w haves and have-nots. The key is not to go back, but to build counter-balance systems that improve accessibility and grassroots layer adoption. More on this to come.
In this breakdown, your favorite cult leader will dissect the mechanism to uncover how it works, why it matters, and where it’s going next. I’ll show you
How AlphaEvolve replaces brute-force AI search with LLM-driven mutation intelligence.
How it weaponizes test-time compute.
How it shifts the bottleneck from human insight to infrastructure.
And why this model-structured discovery guided by automated evaluation may soon become a default template for research, optimization, and invention.
If you work in AI, systems, research, or strategy, you need to understand this paper.
Because AlphaEvolve isn’t a product.
It’s a signal about the future of knowledge work. Considering the macro-economics, layoffs, and rise of automation, we can’t really sit this one out.

Let’s dance, shall we?
Executive Highlights (TL;DR of the Article)
AlphaEvolve is a coding agent built by DeepMind that goes far beyond standard LLM agents or code generators. It uses a structured system of LLM-driven mutation, automated evaluation, and evolutionary selection to iteratively improve programs over time. The result is a machine that doesn’t just generate code — it discovers.

Here’s what you need to know:
Architecture over Answers: AlphaEvolve marks a shift from one-shot code generation to continuous, feedback-grounded improvement. The system evolves solutions, guided by programmatic evaluators, not human preference. The LLM isn’t the solution- it’s a mutation engine that spawns Zerglings for new ideas.
Performance from Process: It achieves breakthroughs by design, not by accident. AlphaEvolve discovered a matrix multiplication algorithm that beat a 56-year-old record, optimized Google’s data center scheduling, redesigned kernel code for Gemini, and improved TPU circuits — all through structured search.

Ablation-Proven: Its performance isn’t the result of one clever trick or just a powerful model. Every component — evolution loop, prompt orchestration, meta-prompt learning, program database — is load-bearing. Removing any piece Kazushis the system and Osoto Garis the performance.
Strategy Encoded in Code: AlphaEvolve reframes what AI systems are for. It shifts the bottleneck from human ingenuity to our ability to define evaluation functions and run search. The strategic edge now lies in who can build and orchestrate these systems, not just who has the largest model.
What Comes Next: We’re just getting started. The next evolution includes:
Distillation: Embedding discoveries back into the model so future systems start smarter.
Hybridization: Combining AlphaEvolve with language-based hypothesis generation to enable full-stack scientific discovery.
Meta-Evolution: Letting the system refine its own strategies, learning how to improve itself.
Evaluator Expansion: Teaching LLMs to help define what counts as “better,” unlocking new domains for automated discovery.
The Bottom Line: AlphaEvolve doesn’t just find answers. It structures the process of finding better ones — at scale, across time, and increasingly without human oversight. Discovery is now a function of system design.
If that sounds like a lot, it is. But it’s also just the beginning.
Read on. This isn’t about one system. It’s about what comes after.
I put a lot of work into writing this newsletter. To do so, I rely on you for support. If a few more people choose to become paid subscribers, the Chocolate Milk Cult can continue to provide high-quality and accessible education and opportunities to anyone who needs it. If you think this mission is worth contributing to, please consider a premium subscription. You can do so for less than the cost of a Netflix Subscription (pay what you want here).

I provide various consulting and advisory services. If you‘d like to explore how we can work together, reach out to me through any of my socials over here or reply to this email.
II. Deconstructing AlphaEvolve: The Core Engine and Its Yield
AlphaEvolve is not a monolithic black box; it is an engineered system of interacting components, each selected for its strategic contribution to the overarching goal of automated, iterative discovery. Understanding these components and their interplay is crucial to grasping the system’s power and its significant improvement on more superficial “agentic” frameworks. I would even compare this to the step from “Chain of Thought” and other prompting techniques to the modern versions of reasoning models.
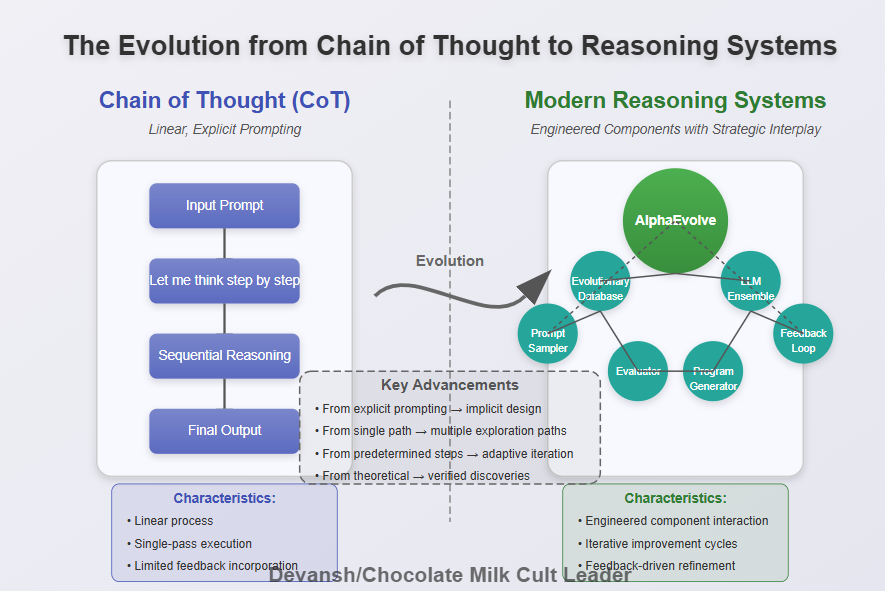
The components of the system are as follows-
A. The Evolution Algorithm Supremacy
The foundational principle of AlphaEvolve is evolution through natural selection, applied to programmatic solutions. This is a deliberate choice, moving far beyond single-shot code generation. Where simpler AI agents might offer a plausible but potentially suboptimal output, AlphaEvolve subjects its programs to a relentless cycle of variation, execution, and stringent selection based on empirical performance. This iterative pressure is designed to navigate vast, complex search spaces where optimal solutions are non-obvious and direct construction is intractable.
It’s worth understanding why this is so powerful-
When it comes to exploring diverse search spaces, EAs are in the GOAT conversations. They come with 3 powerful benefits-
Firstly, we got their flexibility. Since they don’t evaluate the gradient at a point, they don’t need differentiable functions. This is not to be overlooked. For a function to be differentiable, it needs to have a derivative at every point over the domain. This requires a regular function without bends, gaps, etc.
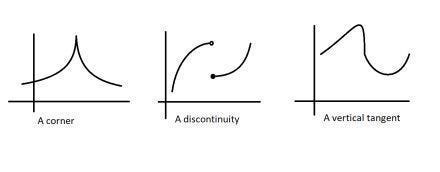
Next, EAs don’t care about the nature of these functions. They can work well on continuous and discrete functions. EAs can thus be (and have been)used to optimize for many real-world problems with fantastic results. For example, if you want to break automated government censors blocking the internet, you can use Evolutionary Algorithms to find attacks. Gradient-based techniques like Neural Networks fail here since attacks have to chain 4 basic commands (and thus the search space is discrete)-
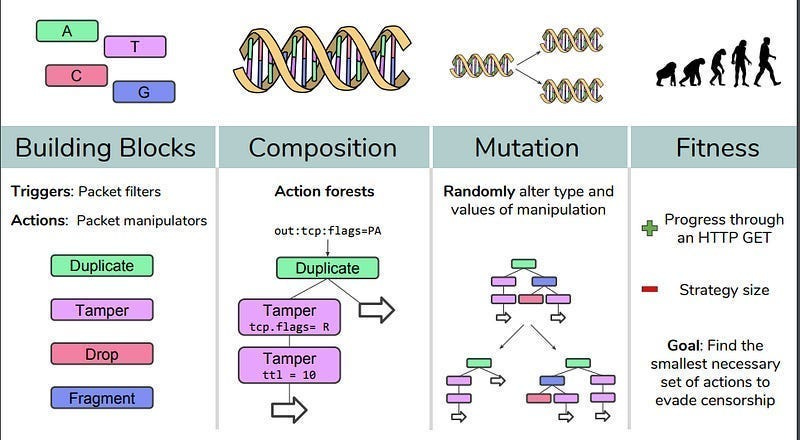
This is backed with some very powerful performance. The authors of the One Pixel Attack paper fool Deep Neural Networks trained to classify images by changing only one pixel in the image. The team uses Differential Evolution to optimize since DE “Can attack more types of DNNs (e.g. networks that are not differentiable or when the gradient calculation is difficult).” And the results speak for themselves. “On Kaggle CIFAR-10 dataset, being able to launch non-targeted attacks by only modifying one pixel on three common deep neural network structures with 68:71%, 71:66% and 63:53% success rates.”
Google’s AI blog, “AutoML-Zero: Evolving Code that Learns”, uses EAs to create Machine Learning algorithms. The way EAs chain together simple components is art-

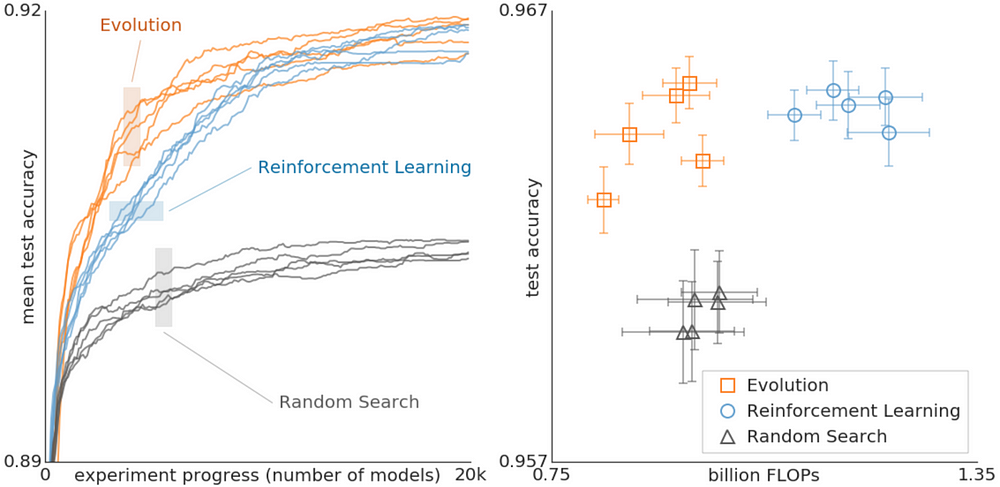
Another Google publication, “Using Evolutionary AutoML to Discover Neural Network Architectures” shows us that EAs can even outperform Reinforcement Learning on search-
The strength of AlphaEvolve’s evolutionary approach is clearest in its breakthrough on matrix multiplication. Through sustained, iterative refinement, it discovered a method to multiply 4×4 complex matrices using just 48 scalar multiplications — surpassing the 49-multiplication record held since Strassen’s 1969 algorithm. The raw gain is modest (~2%), but the method is not. It demonstrates that targeted evolutionary pressure can surface fundamental algorithmic improvements that decades of human effort have failed to uncover. If such results generalize, the downstream impact on AI training and scientific computing is substantial (see Appendix A.1).
This goes beyond code generation. It’s algorithmic invention. Evolutionary algorithms have traditionally been held back by the difficulty of creating objective functions, but this is going to be much easier w/ the usage of general-purpose language models, which can create excellent “first-pass evaluators” to be refined by domain experts. The implications of this shift, + capabilities like Deep Research, should not be overlooked.
B. The LLM as Sophisticated Mutator: Intelligent Variation at Scale
Traditional genetic programming mutates with brute operations: swap, delete, reverse, random constants. It’s like evolving with a box of Legos and no manual. AlphaEvolve swaps that out for a semantic mutator: a SOTA language model that reads the world’s code and knows what “looks right.”

This setup is predicated on an intelligent model selection strategy-
Gemini Flash acts as the wide-net explorer: cheap, fast, high-throughput. This is your Kante, who covers the field, does the volume work, and ensures that things are always running.
Gemini Pro plays the sniper: slower, more accurate, reserved for strategic forks. This is our Ozil- on the field for a few moments of brilliance that completely change the texture of the game.
Pro is well-regarded across the community (even if the recent patch did screw a lot up), but I think people don’t fully understand how good flash is. You likely don’t need a lot of intelligence for most tasks, and if you structure your problem well enough, Flash will be your best pick for ROI.
In the rush for ever-more intelligent models, it’s sometimes good to step back and ask ourselves, “How much intelligence is too much intelligence?”
Back to the setup, these models bond together to generate mutations with:
Syntactic validity
Semantic plausibility
Contextual awareness (via prompt history and evaluation feedback)
This is mutation with priors. Every code change is sampled from a high-dimensional distribution shaped by all known code behavior. That’s categorically more informed than token-swapping.
Fro the nature of these mutations, AlphaEvolve accepts both:
Full rewrites, for fresh candidates when local improvements stall.
Targeted diffs, for efficient patching when improvement paths are clear.
This distinction matters. Diffs are computationally cheap to validate and integrate. Full rewrites allow for paradigm shifts when incremental improvement hits a wall.
The LLM here is not the agent. It is the mutagen, directed by the system, graded by performance. It doesn’t “decide.” It mutates on command.
C. How the use of Automated Evaluation Grounds Discovery
LLMs hallucinate. AlphaEvolve doesn’t care. Why? Because it doesn’t ask the LLM to be right. It asks it to be useful.
That distinction is enforced by the h function — a strict, executable evaluation function defined by the user.
This function is the system’s truth oracle. It returns scalar scores: latency, accuracy, compression ratio, whatever defines success. If it can’t be machine-evaluated, it doesn’t count. I think I can hear Jack Welsh celebrating in the background.
Evaluation is:
Automatic — No human in the loop
Scalar — All feedback is compressible into hard numbers
Final — No appeal, no “close enough”
The implications are serious:
AlphaEvolve sidesteps hallucination entirely. If a code variant doesn’t improve the score, it dies.
It can only operate in domains where evaluation can be formalized. That includes math, systems optimization, hardware design, algorithm tuning. Not poetry, yet. As we try to extend this into more spaces, it might be worth thinking about how this will change the nature of what we consider “creative” and good.
To prevent costs from going out of control, we can rely on the following:
Evaluation cascades: Run cheap sanity checks before expensive tests
Parallel evaluation: High-throughput evaluation on distributed infra
Pruning: Kill weak variants early to focus compute on promising lines
The evaluator isn’t just a grader. It is the selective pressure of the system. Its design defines the direction of evolution.

D. Prompt Orchestration & Meta-Evolution: Guiding and Refining the Generative Core
The LLMs within AlphaEvolve do not operate in a vacuum. They are guided by meticulously constructed prompts that provide rich context and direct their generative efforts. This “prompt orchestration” is a key lever for focusing the LLM’s capabilities. Prompts typically include:
Exemplars: High-performing programs from the evolutionary database, illustrating successful structures and patterns.
Performance Data: Evaluation scores of previous attempts, providing direct feedback on what has (and has not) worked.
Problem-Specific Context: Human-provided instructions, mathematical formulations, relevant literature excerpts, or domain knowledge.
System Instructions: Guidelines on how to propose changes, desired output formats (e.g., diffs: <<<<< SEARCH / ======= / >>>>> REPLACE for targeted edits, or full code blocks for substantial rewrites).
A particularly potent feature is meta-prompt evolution. Here, the LLM itself can be tasked with suggesting improvements to the prompts and instructional context it receives. This creates a recursive self-improvement loop where the system learns to formulate better questions and provide more effective guidance to its own generative components.

The nuanced prompts likely employed for tensor decomposition, for example, probably included implicit or explicit requests for near-integral solutions — a subtle but crucial bias that guided the LLM towards the kind of structured solutions that ultimately broke the matrix multiplication record. The ability to evolve and refine such sophisticated prompting strategies is a meta-level optimization that amplifies the system’s core discovery capabilities.
E. The Program Database: Strategic Archiving of Evolutionary Progress
AlphaEvolve maintains an “evolutionary database” that stores a curated set of previously generated programs along with their evaluation results. This is more than a simple replay buffer; it is a strategic archive designed to:
Preserve High-Performing Solutions: Obvious, but crucial for exploitation.
Maintain Diversity: Inspired by techniques like MAP-Elites and island-based evolutionary models, the database aims to store a diverse range of “good” solutions, not just the single best one, a principle we’ve covered many times in this newsletter. This helps avoid premature convergence on a local optimum and provides a richer set of exemplars for future prompt generation. Different “species” of solutions, excelling in different aspects or via different mechanisms, are preserved.

Inform Future Generations: Programs sampled from this database serve as inspiration and starting points for new mutations, effectively carrying successful genetic material forward.
The breadth of mathematical problems where AlphaEvolve demonstrated SOTA performance or improvements (matching in ~75% and surpassing in ~20% of over 50 problems) strongly suggests the utility of such a diverse knowledge base. Different problems likely benefited from different families of evolved search heuristics stored and resurfaced from this database, allowing the system to draw upon a wide array of previously successful “ideas.”
F. API, Integration, and Multi-Metric Optimization: Pragmatic Power
For practical application, AlphaEvolve incorporates design choices that facilitate its use in real-world contexts:
Targeted Evolution via API: The use of simple comment markers (# EVOLVE-BLOCK-START, # EVOLVE-BLOCK-END) allows AlphaEvolve to focus its evolutionary efforts on specific, designated sections within larger, existing codebases. The surrounding, non-evolved code acts as a stable scaffold, enabling integration with complex systems without requiring a complete rewrite.

Multi-Metric Optimization: The system is not restricted to optimizing a single scalar objective. It can evolve programs that perform well across multiple, potentially competing, evaluation metrics. This is crucial for real-world problems where “goodness” is often multi-faceted (e.g., speed vs. accuracy vs. resource consumption).
In other words, AlphaEvolve is opinionated but composable. You define the boundary conditions. It evolves within them.
With a system this intricate, a good question to ask would be “is this, assembly truly necessary, or is its performance attributable to just one or two silver-bullet components, perhaps even the power of the latest LLMs alone?” The creators of AE, commendably, did not leave this to speculation. They subjected AlphaEvolve to a series of rigorous ablation studies, systematically disabling key functionalities to measure their individual contributions.
And that is exactly what we will discuss next.
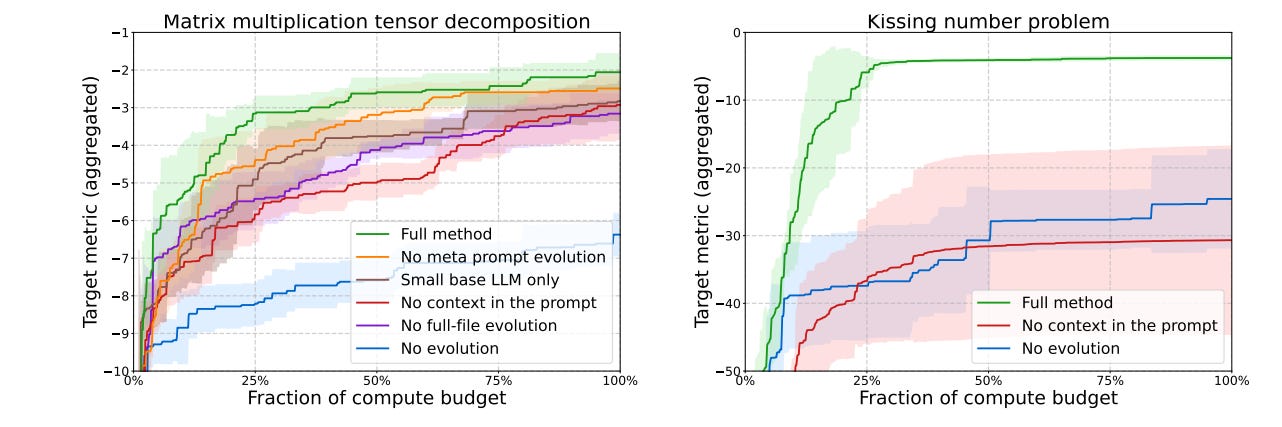
Ablation Studies: No Halfway Crooks in AlphaEvolve
“Figure 8 shows the results of the all-inclusive AlphaEvolve approach as well as the various alternatives listed above. As can be seen, each of the components is responsible for a significant improvement in the results”
Let’s take a look at what each component brings to the table-
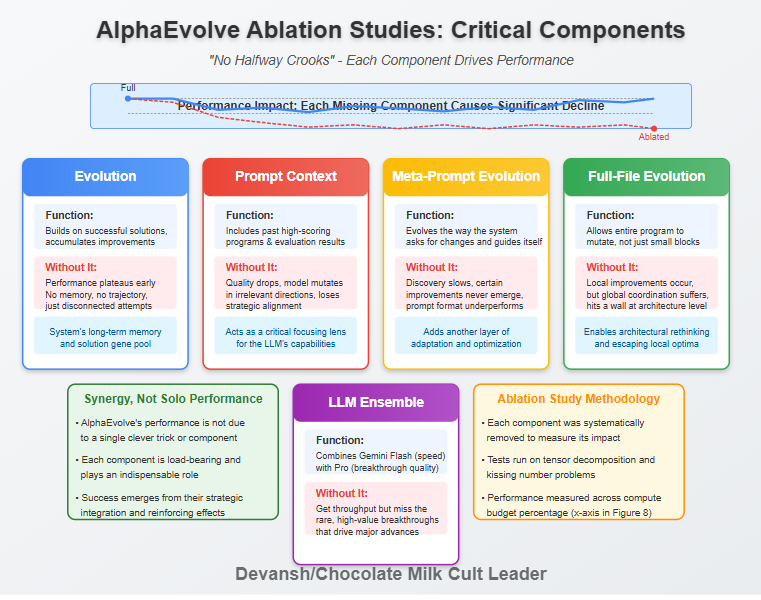
A. No Evolution: Static LLM Sampling Fails Fast
Test: Instead of evolving from prior solutions, the system repeatedly prompts the LLM with the same base program.
Result: Performance plateaus early. Improvements stall. Diversity collapses. The system can’t climb because it’s not building on what worked. There’s no memory, no lineage, no trajectory.
Interpretation: Simply having a powerful LLM repeatedly “try again” on a static starting point is insufficient for complex discovery. The LLM, for all its pattern-matching prowess, lacks the persistent, directed memory and selective pressure that the evolutionary loop provides. Without evolution, there is no accumulation of “good ideas,” no hill-climbing in the solution landscape. It’s simply taking disconnected shots in the dark.
In systems terms- even if the LLM is strong (has a strong base performance); the lack of “error function” means that future improvements are neutered. Our system took inspiration from your life and peaked in very young.
The evolutionary database, acting as the system’s long-term memory and gene pool, is clearly not optional.
B. No Prompt Context: Blind Mutation Is Still Blind
Test: LLMs are prompted without including past high-scoring programs or evaluation results.
Result: Quality drops. The model mutates in irrelevant directions. Semantic correctness remains, but strategic alignment disappears.
Interpretation: This highlights the LLM’s nature as a conditioned generator. While it possesses vast general knowledge from its pre-training, its ability to apply that knowledge effectively to a specific, novel problem is heavily dependent on the quality and richness of the immediate context provided. Without examples of what “good” looks like for this particular task, or feedback on prior attempts, the LLM is navigating with a far less accurate map. The rich context supplied by AlphaEvolve’s prompt orchestrator acts as a critical focusing lens.
C. No Meta-Prompt Evolution: Stagnation in Instruction Quality
Test: System uses fixed, human-written prompts instead of evolving the way it asks for changes.
Result: Discovery slows. Certain improvements never emerge. Prompt format that works for one domain underperforms in another.
Interpretation: This is a subtle but strategically vital finding. Allowing the system to learn how to prompt itself better introduces another layer of adaptation and optimization. I’d love to see how this plays in the future, and how we can build systems to evolve thinking/guidance in different ways (perhaps systems where users can stop the “thinking” part of reasoning models and inject feedback to create thought trees).
D. No Full-File Evolution: Overfitting to Local Fixes
Test: Only one function or small block is allowed to mutate, instead of the full program file.
Result: Local improvements occur, but global coordination suffers. Performance hits a wall when architectural rethinking is needed.
Interpretation: Small-scale mutation without architectural permission leads to local optima lock-in. Full-file evolution is what lets the system step out of the rut and change the shape of the hill it’s climbing. As we covered here, Incrementalism has limits. Real discovery sometimes requires reframing the problem, not patching it.

E. Small-Only LLMs: Volume Without Breakthrough
Test: Replace Gemini Flash + Pro ensemble with a single small model (e.g., Flash-only).
Result: You get throughput. You don’t get breakthroughs. Flash is strong at exploring, but can’t generate the rare, high-value inflections.
Interpretation: If I have to explain to you why powerful models matter for high-complexity tasks, you probably shouldn’t be reading this.
All in all, the ablation studies paint a clear picture. AlphaEvolve’s remarkable performance is not an accident of a single clever trick or an overpowered LLM going super-duper saiyan. It is the emergent result of a well-architected system where all parts play indispensable and synergistic roles. Each component is load-bearing.
With the internal architecture validated and its components proven essential, we can now turn to the larger strategic implications of AlphaEvolve as a doctrine. This is more than just an optimized system; it’s a new operational model for discovery and innovation.
Sound like a bit much? Allow me to justify.
Strategic Calculus: What AlphaEvolve Means for the World.
AlphaEvolve is not the destination. It’s a proof of concept for a new kind of operational logic: one where discovery itself is systematized, repeatable, and architecturally scalable.
A. From Code Generation to Code Evolution: A Shift in AI’s Role
AlphaEvolve marks a clean break from the “one-shot generation” paradigm. Prior tools asked the LLM to generate something good enough. AlphaEvolve instead treats generation as the first mutation in an evolutionary chain.

This changes the LLM’s role from oracle to operator:
It doesn’t try to be “right.”
It tries to be iteratively useful — generating candidates under a selective regime.
This shift brings three cascading advantages:
Cumulative learning at the system level (not the model level)
Error tolerance — bad generations are just data, not failure
Scalable exploration across high-dimensional design spaces
LLMs become mutation engines, not solution providers. This is not “prompt engineering” as conventionally understood; it’s system engineering where the LLM is a powerful but ultimately subordinate component.

B. The Blueprint for Automated Discovery: Generalizability and Constraints
AlphaEvolve offers a general pattern. If a domain has:
A code-based representation of potential solutions
A machine-gradeable evaluation function
…then it is tractable for automated, scalable optimization.
This includes:
Mathematical object construction
Algorithm design
Systems tuning (schedulers, kernels, compilers)
Circuit-level hardware code
Synthetic biology protocols (eventually)
But the constraint is real: no eval function, no evolution. If the problem can’t be scored well, it can’t be optimized.
Hence, the next arms race is not in building better agents — it’s in building better evaluation environments. These environments define what kinds of knowledge can be industrialized. This also means that data collection platforms will see a boom, but this will disproportionately flow towards the platforms that have richer blends of annotation. This should not be overlooked.

C. The Self-Improvement Trajectory: AI Optimizing AI
One of AlphaEvolve’s most consequential moves was using its own optimization loop to improve:
Kernels used in LLM training
TPU components that power model inference
Compiler outputs that define runtime behavior
This isn’t marketing spin. Even a 1% improvement per iteration, when directed at infrastructure, becomes compounding throughput. Unlike model scaling, which hits cost ceilings, this loop reduces the cost of intelligence over time.
This is the real asymmetry: Not who has the best model, but who has the best self-improving system. This can be the resurgence of alternative ideas like Self-Organizing Intelligence, which imo is criminally underrated-
D. Redefining Test-Time Compute: From Inference to Iterative Optimization
AlphaEvolve redefines what “test-time” means.
Historically:
Training = learning
Inference = deployment
AlphaEvolve introduces a third mode:
Discovery = live optimization
You don’t just run the model. You deploy it into a feedback-rich loop where compute is spent not on serving answers, but on evolving better ones.
This implies a shift in how we value and deploy computational resources. Instead of solely focusing on minimizing inference latency for user-facing applications, there’s immense value in dedicating substantial compute to these offline, evolutionary search processes if they can yield breakthroughs that offer persistent, widespread benefits (like a faster matrix multiplication algorithm or a more efficient data center). It weaponizes what would otherwise be idle or less strategically employed compute cycles for high-stakes discovery.
E. The Shifting Bottleneck: From Human Cognition to Capacity
As systems like AlphaEvolve mature, the bottleneck moves.
It’s no longer:
“Can we come up with a good idea?”
“Can we write the right code?”
“Can we prompt the LLM the right way?”
It becomes:
“Do we have a good evaluation function?”
“Can we afford the compute to run 10,000 evaluations?”
“Can we scale infrastructure to accommodate iterative experimentation?”
“How do we read through all the signals and quickly identify the right paths?”
The human’s role narrows — but it sharpens:
Define objectives
Shape the evaluator
Interpret discovered outputs
Decide what discoveries get distilled back into base models
Inject feedback back into the system (for the future).
This is in-line with the larger trend where execution is becoming more commoditized (internet, global labor, and now AI all making it easier), so decision making becomes more valuable (suddenly the impact of a few good or bad decisions compounds massively since automated systems will iterate on them).
This new doctrine, however, is not a static endpoint. AlphaEvolve itself, and the principles it embodies, are undoubtedly poised for further evolution. Understanding its current strategic posture is merely the prelude to anticipating its next, likely more disruptive, moves.
The Next Evolutionary Step: Distillation, Hybridization, and Meta-Evolution
AlphaEvolve isn’t static. Its current architecture is just the scaffolding for what comes next. If you understand it only as it exists today, you’ll miss its real significance: it’s a seed for recursive systems that evolve not only solutions, but the machinery of evolution itself.
AlphaEvolve is a good illustration of the idea that discovery, like intelligence, can be made infrastructure-bound. And once that boundary is formalized, it can be recursively expanded.
Once understand that, we must look beyond the present to logical extensions of the system’s own principles — steps that, if not pursued by you, will be pursued by someone else.
A. Distillation: Embedding Discovered Wisdom into Foundational Models
At present, AlphaEvolve produces high-performing outputs: code, heuristics, and optimized algorithms. These outputs are stored, deployed, or reused — but remain external artifacts. The next step is to close the loop through distillation: systematically folding the knowledge encoded in these evolved solutions back into the training or fine-tuning cycles of foundational LLMs.
The Concept: Systematically incorporating the knowledge embodied in these high-performing evolved programs (e.g., new algorithmic structures, optimized heuristics, effective code patterns) back into the training datasets or fine-tuning processes of the next generation of foundational LLMs (like Gemini).
The Strategic Value: This closes a crucial loop. Instead of each AlphaEvolve run being a one-off discovery event, the insights gained become part of the “genetic makeup” of the base models themselves. This would mean future LLMs start with a higher baseline understanding of efficient and effective programmatic solutions. It’s a mechanism for making the entire AI ecosystem smarter, not just individual evolved programs. The result: future AlphaEvolve instances, powered by these distilled-knowledge LLMs, would begin their search from a more advanced starting point, potentially accelerating discovery even further. This is how generational improvements in AI will compound.
B. Hybrid Systems: Marrying Code-Grounded Evolution with Abstract Hypothesis Generation
AlphaEvolve thrives in well-scoped environments — where problems can be expressed as code, and success can be precisely evaluated. But most upstream scientific activity doesn’t begin in code. It begins in vague hypotheses, loosely-structured questions, or high-level system models. Discovery starts messy.
The bridge is hybridization. Imagine a layered architecture: a natural language-driven hypothesis engine proposes scientific or strategic ideas; a formulation layer converts those into executable representations with defined evaluation criteria; and AlphaEvolve then enters, executing structured searches over that formalized space. Results loop back, updating the hypothesis layer, refining direction, proposing new lines of attack.
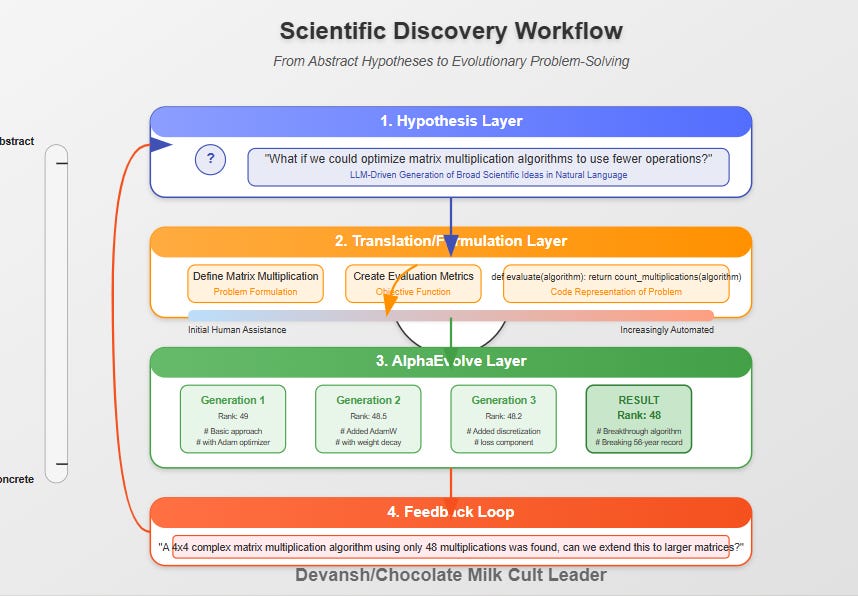
The Workflow Envisioned:
A “Hypothesis Layer” (potentially LLM-driven) proposes broad scientific ideas or experimental directions in natural language.
A “Translation/Formulation Layer” works (perhaps with human assistance initially, then increasingly automated) to convert these abstract hypotheses into concrete, machine-testable problems, defining code representations and evaluation functions.
AlphaEvolve (or a similar engine) then takes over, evolving programmatic solutions or searching for evidence within the formulated problem space.
Results are fed back to the Hypothesis Layer to refine or generate new high-level ideas.
The Strategic Value: This bridges the gap between conceptual innovation and empirical validation. It would allow AI to participate more fully in the entire scientific discovery pipeline, from idea inception to concrete solution, dramatically expanding the scope of problems amenable to automated approaches.
C. Meta-Evolution: The System Learning to Evolve Better
AlphaEvolve already evolves programs. But the strategies governing that evolution — the sampling heuristics, mutation policies, Flash/Pro orchestration, parent selection rules — are largely fixed. That’s an artificial ceiling. And lifting it is straightforward.
Meta-evolution is the next frontier: evolving not just solutions, but the mechanisms of solution generation. The system begins learning when to apply full rewrites versus diffs, how to balance exploration against exploitation, and how to restructure its program database to surface the right historical solutions at the right time. Even the evolutionary loop itself — how often to sample, when to discard, how to prioritize — can become a search space.
Studying this system would be massive for systemizing scientific discovery, allowing us to develop frameworks and starting templates for cutting-edge research.
D. Expanding the Evaluator: LLMs as Architects of Objective Functions
The current critical constraint for AlphaEvolve is the need for a human-defined, machine-executable evaluation function (h). As mentioned earlier, this is where the next major frontier likely lies.
LLMs are increasingly capable of scaffolding approximate evaluators from sparse, noisy, or even natural language inputs. A domain expert can describe what matters in vague terms, and the model can produce an initial, code-executable version of it. It won’t be perfect, but it’s a foothold. From there, it can be refined by humans — or even iteratively evolved by another system loop.
Longer term, models can be trained to infer evaluators directly from datasets, by observing what “better” and “worse” solutions look like over time. With enough examples, the evaluator becomes learned, not specified.

These trajectories — distillation, hybridization, meta-evolution, and AI-augmented evaluation — are not mutually exclusive. They are likely to intertwine, creating an even more potent and adaptive engine for discovery and innovation. The implications of such an acceleration, where the tools of discovery themselves are subject to rapid, automated improvement, form the core of our concluding assessment.
Conclusion: The Inescapable Trajectory
If there’s one thing I’ve learned from history’s great businesses, it’s that the derivative (speed) and the second derivate (change of speed) of learning are the most important variables to success.
AlphaEvolve makes one thing clear: the locus of innovation has shifted. It no longer resides in talent, intuition, or isolated insight — it resides in systems.
Systems that iterate. Systems that learn from feedback. Systems that retain, recombine, and improve.
AlphaEvolve is one such system — an architecture that doesn’t just find answers, but builds momentum. And in a world moving this fast, momentum beats genius.
Discovery is now infrastructure.
And infrastructure always wins.
Thank you for being here, and I hope you have a wonderful day.
Can’t believe noone has automated taxes yet,
Dev <3
If you liked this article and wish to share it, please refer to the following guidelines.
That is it for this piece. I appreciate your time. As always, if you’re interested in working with me or checking out my other work, my links will be at the end of this email/post. And if you found value in this write-up, I would appreciate you sharing it with more people. It is word-of-mouth referrals like yours that help me grow. The best way to share testimonials is to share articles and tag me in your post so I can see/share it.

Reach out to me
Use the links below to check out my other content, learn more about tutoring, reach out to me about projects, or just to say hi.
Small Snippets about Tech, AI and Machine Learning over here
AI Newsletter- https://artificialintelligencemadesimple.substack.com/
My grandma’s favorite Tech Newsletter- https://codinginterviewsmadesimple.substack.com/
My (imaginary) sister’s favorite MLOps Podcast-
Check out my other articles on Medium. : https://rb.gy/zn1aiu
My YouTube: https://rb.gy/88iwdd
Reach out to me on LinkedIn. Let’s connect: https://rb.gy/m5ok2y
My Instagram: https://rb.gy/gmvuy9
My Twitter: https://twitter.com/Machine01776819
Appendix: Detailed Back-of-the-Envelope Impact Estimations for AlphaEvolve Breakthroughs
This appendix provides a granular breakdown of AlphaEvolve’s key achievements and their potential impact. These are high-level estimations meant to illustrate orders of magnitude and strategic implications, not precise accounting. Assumptions are stated explicitly.
A.1. Matrix Multiplication (4×4 Complex, 48 vs. 49 Multiplications)
Core Algorithmic Gain
Previous SOTA (Strassen-derived): 49 scalar multiplications
AlphaEvolve Discovery: 48 scalar multiplications
Improvement: 1 multiplication → ~2.04% reduction for this operation
Assumptions for Broader Impact
Ubiquity: Matrix multiplication dominates workloads in AI, HPC, graphics, signal processing
Compounding: AlphaEvolve improved 14 matrix configurations, indicating potential generalizability
Deployment: Requires integration into core libraries (cuBLAS, JAX, LAPACK) or compiler backends
Dominant TCO Factor: Compute costs (hardware, energy, cooling) are significant across AI/HPC
Estimated Commercial & Computational Impact
Scenario 1: Frontier AI Model Training
Training cost: $50M–$100M
Matrix multiplications: ~30–50% of FLOPs
Average performance gain from AI-discovered algorithms: 0.5–1.0%
Effective workload reduction:
0.5% × 30–50% = 0.15–0.25% of training cost
1.0% × 30–50% = 0.30–0.50% of training cost
Cost savings:
$50M run → $75K–$250K
$100M run → $150K–$500K
Scenario 2: Hyperscale Data Center Power
1M accelerators @ 250W average load = 250 MW
Utilization at 50% = 1,095,000 MWh/year
Electricity cost: $0.07/kWh → $76.65M/year
Savings:
0.5% gain → $383K/year
1.0% gain → $767K/year
Hardware Amortization Savings
1% fewer accelerators @ $2000/year amortized cost
Saved machines: 10,000
Cost savings: $20 million/year
Strategic Implications
Demonstrates LLMs can discover fundamental algorithmic improvements
Opens pathway to systematically raise computational efficiency floor
Competitive advantage in training throughput, energy efficiency, and cost
A.2. Open Mathematical Problems (e.g., Kissing Number in 11D: 592 → 593)
Core Scientific Gain
New constructions/improved bounds for theoretical problems
Kissing Number (11D): 593 non-overlapping unit spheres (previous best: 592)
Assumptions
Indirect application: Pure math often yields long-delayed utility
Conceptual impact: Advances frameworks for future proofs and constructions
Primitive design: Some problems relate to coding theory, signal processing, materials science
Estimated Long-Term Impact
Scientific acceleration: AI speeds up progress in difficult theoretical domains
Coding theory connection: Kissing numbers relate to packing density → affects error-correcting codes
A single-point gain may not shift practice
But consistent AI discovery across dimensions could improve design targets for communications/data storage
Sociological Shift
Collaboration with Terence Tao signals AI integration into core mathematical workflows
Normalizes AI as a theorem-construction tool, not just a solver or assistant
What skills become important for this? How does this change our perception of what it means to know something?
A.3. Google Infrastructure Optimization
A.3.1. Data Center Scheduling (Borg)
0.7% of compute fleet reclaimed
Assumptions:
2M machines affected
Annual per-server cost: $3,000–$5,000
Estimated Savings:
Servers reclaimed: 2,000,000 × 0.007 = 14,000
Annual value:
$3K/server → $42M/year
$5K/server → $70M/year
Additional Value:
Faster job turnaround → reduced queuing delays; better customer retention?
Higher utilization for cloud workloads → revenue uplift potential
A.3.2. Gemini Kernel Engineering
23% kernel speedup → 1% training time reduction
Assumptions:
Training cost: $50M–$100M
Number of runs per model generation: 5–10
Direct Savings:
Per run:
$50M → $500K
$100M → $1M
Per model cycle: $2.5M–$10M saved across multiple runs
Engineering Velocity:
Manual tuning saved: ~2.75 months
Engineer cost @ $500K/year → ~$114K per kernel
Strategic Advantage:
Accelerated R&D and iteration loop
Enables AlphaEvolve to optimize systems that improve AlphaEvolve
A.3.3. TPU Circuit Optimization (Verilog)
Assumptions:
Area reduction: 0.5–1.0%
Power reduction: 0.5–1.0%
1M TPUs deployed
Arithmetic unit power: 50W average
Wafer cost: $10,000
Yield: ~500 dies/wafer
Manufacturing Savings:
Extra 2–3 dies/wafer = ~$50 savings
100,000 wafers = $5M saved
Power Savings:
Annual power = 438,000 MWh
Power cost: $30.66M
Savings:
0.5% → ~$153K/year
1.0% → ~$306K/year
Strategic Value:
Early optimization in RTL reduces total design-test cycle time
LLMs now reaching hardware design primitives
A.3.4. XLA Compiler IR Optimization
32% kernel speedup; 15% pre/postprocessing gain
Assumptions:
1B inference queries/day
Attention ops = 100ms per query
FlashAttention accounts for 5–10% of time
Savings:
5ms saved/query → 5M seconds/day = 1,389 compute-hours/day
Compute cost = $2–$5/hour
Daily saving = $2,778–$6,945
Annual saving = $1.01M–$2.53M
Broader Gains:
Better user latency → UX uplift
Higher serving throughput → deferred infra expansion
If integrated into XLA: all Google JAX/TensorFlow workloads benefit
Closing Reflection
Across these domains — algorithm design, mathematics, and system infrastructure — AlphaEvolve shows that small percentage gains, applied at scale, are not marginal. They’re multipliers of economic efficiency, engineering velocity, and strategic advantage.
In AI and infrastructure at hyperscale, 1% is not small.
It’s the new competitive margin.
The hardware costs are rescued and scientific discovery happens quicker ? Is that the punchline? Thanks for sharing 🌞
This is an awesome explanation. Thank you for the detail!
I've been wondering how long it would take a lab to come out with an evolutionary algorithm because they've gotta all be working on them. This feels like another paradigm shift.