
Model Collapse by Synthetic Data is fake news [Investigations]
Addressing one of the Biggest Misunderstandings in Generative AI

Hey, it’s Devansh 👋👋
Some questions require a lot of nuance and research to answer (“Do LLMs understand Languages”, “How Do Batch Sizes Impact DL” etc.). In Investigations, I collate multiple research points to answer one over-arching question. The goal is to give you a great starting point for some of the most important questions in AI and Tech.
I put a lot of effort into creating work that is informative, useful, and independent from undue influence. If you’d like to support my writing, please consider becoming a paid subscriber to this newsletter. Doing so helps me put more effort into writing/research, reach more people, and supports my crippling chocolate milk addiction. Help me democratize the most important ideas in AI Research and Engineering to over 200K readers weekly. Many companies have a learning budget that you can expense this newsletter to. You can use the following for an email template to request reimbursement for your subscription.
PS- We follow a “pay what you can” model, which allows you to support within your means, and support my mission of providing high-quality technical education to everyone for less than the price of a cup of coffee. Check out this post for more details and to find a plan that works for you.
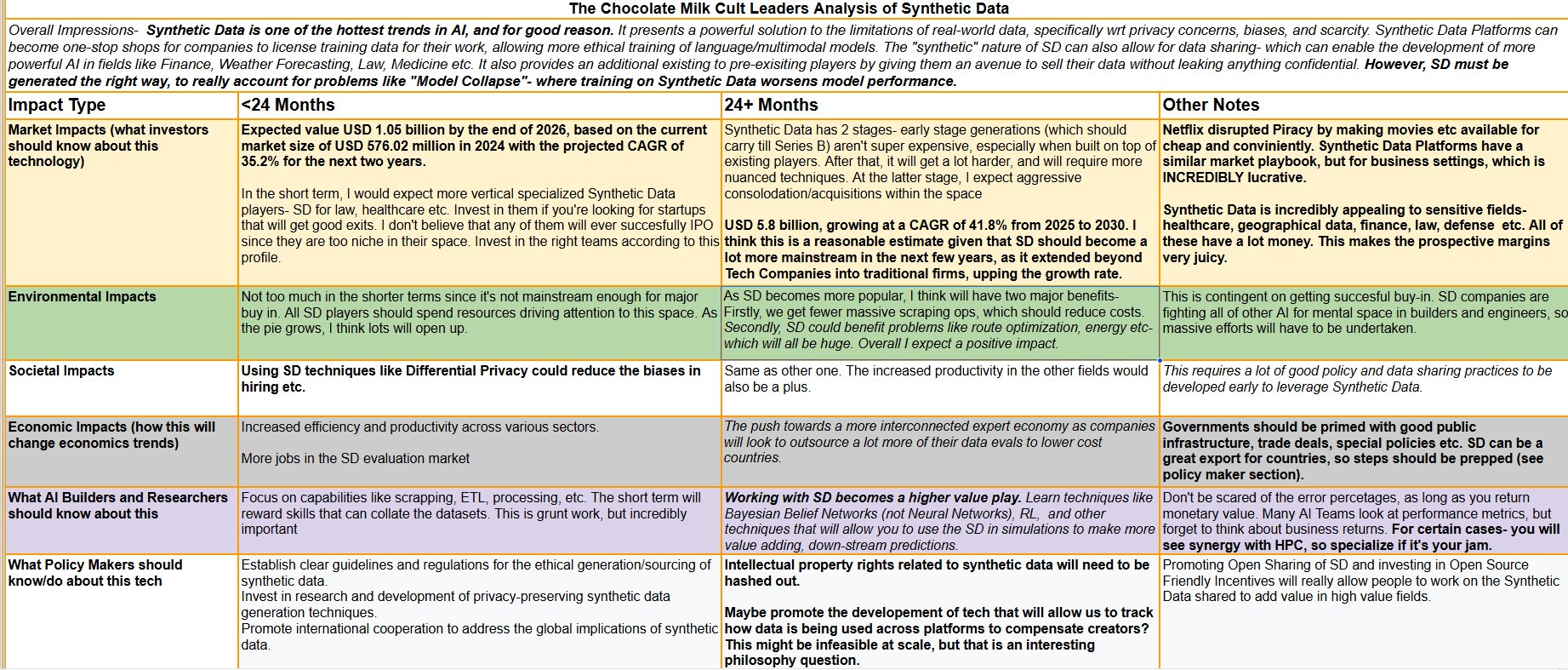
Synthetic Data is one of the hottest fields in AI. LLM companies need more data to improve their performance- both in general tasks (where Synthetic Data would be used to train LLMs to follow longer chains of “thought”- as is required from “reasoning models”) and in domain-specific tasks- where SD might be a powerful way to encode the inductive biases/best practices of a field without having to code them all in (this will likely not be enough for a full vertical play, but will at least form a differentiating base for other builders to pick a model).
This performance is reflected in the commercial forecasts for the platform. Estimates place the Synthetic Data Generation market between 400–576 Million USD in 2024, with a CAGR (Compound Annual Growth Rate) of 35–41% over the decade, depending on your sources. In my opinion, the CAGR can be further expanded into two components-
In the early stages, I expect a lower growth rate of around 35% (to understand how I get to specific numbers, please refer to the caption of the table of impacts that will be shared). Synthetic Data isn’t mainstream outside of Tech, so it will limit major growth avenues from a limited quantity of buyers.
In the later stages, I expect higher-end growth (even outside of the forecasts) of 41.8% as more “non-tech” fields become more familiar with Sd and its offerings.
My bullishness on SD is based on two components: it appeals to extremely lucrative industries, and it is an extremely monopolistic market in the long-run- allowing winning firms to massively benefit from platform economics and economies of scale. SD-related techniques, like Differential Privacy and Privacy-Preserving Substitutions (both great for debiasing your input, which is key before using Deep Learning in fields like Resume Evals and Credit Scoring), can be offered as standalone offerings, providing low-cost acquisition funnels for providers to get in customers that can be upsold into more high-margin services later
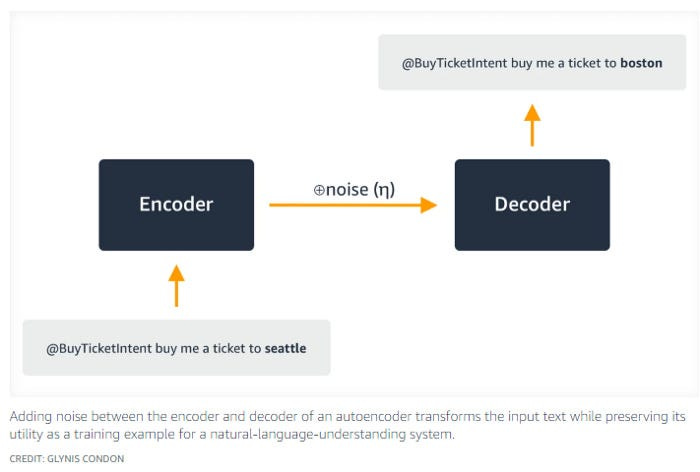
All in all, Synthetic Data appeals to many different cases and will be a huge player in the upcoming generation of ML. A more detailed of it’s impacts from various angles is given below-
However, SD was first introduced to many people in a negative limelight due to the discussion around Model Collapse, where Language Models seem to degrade heavily in performance when trained on AI-generated data. While the research and it’s findings are technically true, I think the discussion misses an important nuance that actually handles the baseline cause of Model Collapse. This is something I’ve been meaning to address for a long time. Yesterday, I came across the following meme-

And decided that I’d procrastinated enough. In the following article, we will do a deep dive into Model Collapse, why it happens, and how people can address it to generate Synthetic Data that doesn’t make LLMs crash out like Arman Tsarukyan’s future title aspirations (I’m not over that fight being pulled last minute).
Executive Highlights (TL;DR)
Background: Why Synthetic Data is worth Billions
Before we get into the whole thing, it’s worthwhile to briefly discuss why Synthetic Data can be such a game-changer. This will help us contextualize why investments into better SD generation is going to be valuable-
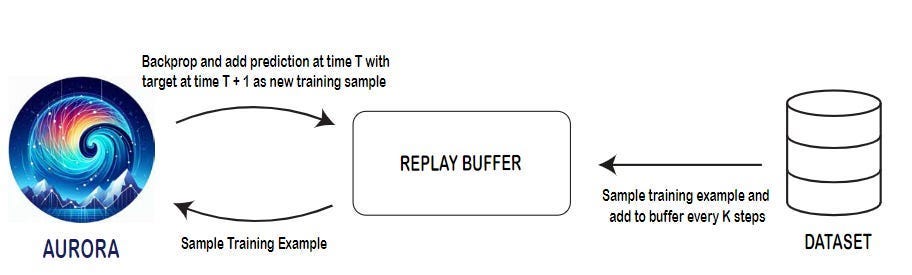
Well-developed synthetic data enables training AI models on rare or impossible scenarios to capture in real datasets- extreme weather events, physical handicaps, or equipment failures, etc- helping build more robust and comprehensive systems that can handle edge cases effectively. This is why many weather models, such as Microsoft’s exceptional Aurora, use a variant of Synthetic Data (where they build chains of predictions and train on that, quite similarly to how I imagine “reasoning models” would do things) to get better at long term forecasts (forecasting across a time horizon, requiring multiple sub-inferences), instead of one-shot predictions (optimizing to get one inference right, the principle of current Auto Rregressive systems, including LLMs)-
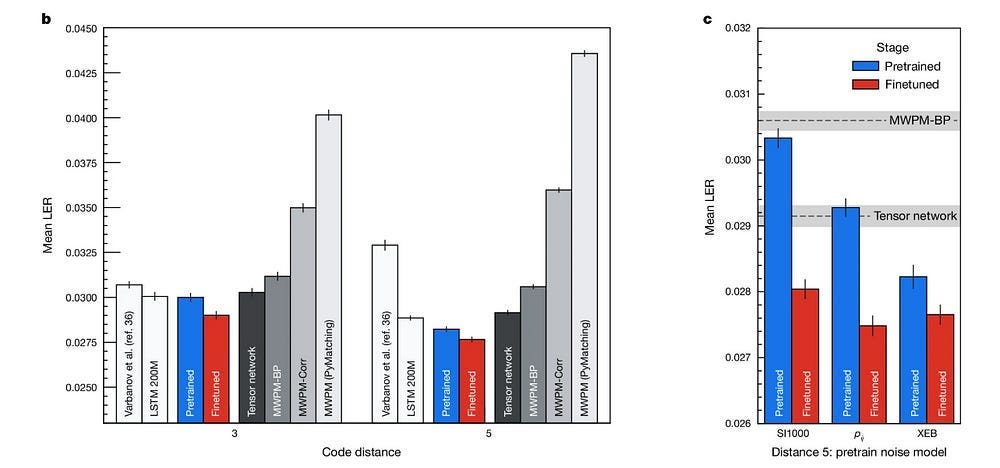
By generating unlimited amounts of synthetic data, organizations can overcome the common hurdles of data scarcity and expensive manual labeling, dramatically accelerating the development cycle while reducing costs compared to collecting and annotating real-world data. This was shown brilliantly in Google’s Research for Quantum Error correction (key to their Willow Chip). As you look at the chart below, I want you to notice the following- the Error for just pretraining matches state-of-the-art methods for error correction (lower LER is better). Interestingly- the pretraining for the chips was done entirely on synthetic data, since collecting Quantum Data IRL is very expensive. Only the fine-tuning was done on real-world chips (the error reduction FT isn’t massive, telling us that SD can bring us to 90% performance)-
Synthetic data offers precise control over demographic representation and edge cases, allowing teams to address bias and fairness concerns by ensuring training data includes balanced representation across different groups and scenarios that might be underrepresented in real-world datasets. To give a non-traditional but powerful example, we can refer to AlphaGeometry, DeepMind’s cutting-edge Math Solver that had a 2.5x improvement over previous AI systems in solving Math Geometry problems. AG uses synthetic data all the way through, and a key driver to their final performance is their use of varying proof lengths to allow their model to allow various complexities in solutions. The use of SD allows the researchers to play with their compositions of their proof lengths while maintaining overall data distributions (x% of style 1, y% of style of style/idea 2, …), which would not be possible with real world data.
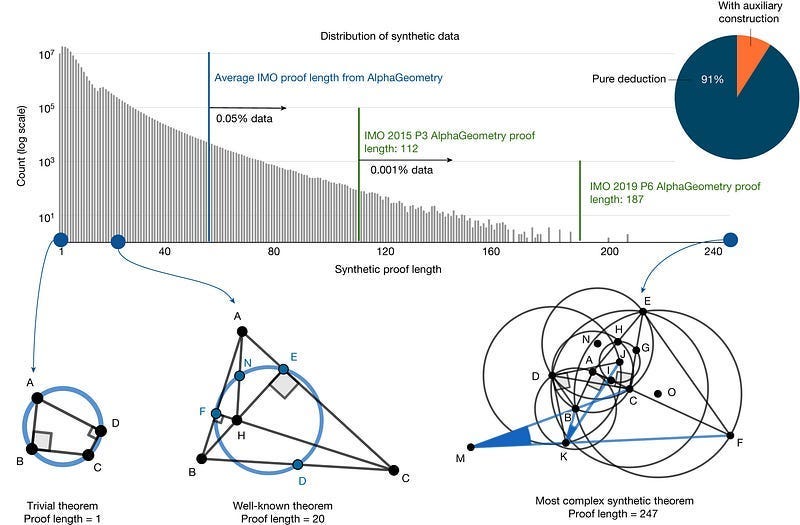
When dealing with sensitive information like medical records or financial transactions, synthetic data can preserve statistical properties while eliminating privacy concerns, enabling organizations to share and collaborate on data-driven projects without compromising individual privacy. This is especially important since we have to deal with regulations that would forbid cross-border sharing, hosting data publically etc- all of which would be key to leveraging the OpenSource movement to make meaningful strides in important problem statements.

As mentioned, Synthetic Data can be used to debias data inputs, allowing for more fair evaluations of candidates.
Leveraging SD Platforms can help organizations avoid issues like underpayment of data annotators, exposure of minors to disturbing content, and other problems that traditional data-labeling companies face-

Even speaking purely pragmatically, even if the SD company/its sub-contractors engage in similar practices- the purchaser of Synthetic Data adds another layer of responsibility between themselves and the shady practices- allowing them to duck legal responsibility.
Cross Collaboration- Not technically a benefit of the tech of SD itself, but SD platforms can easily tie up with data providers, becoming a one stop shop for high-quality data. The convenience aspect
Hopefully, the massive value that each of these cases can unlock becomes clear to you. I think in the long term, we will see the data labeling companies and SD platforms merge, and I think the latter has a better chance of absorbing the former (SD has the inherent control, cost, and regulation-related advantages that scale better than the pure labor arbitrage offered by data shops).
I spent a long time on this b/c I won’t touch upon this in the main sections of the article. I don’t want to focus this article on selling SD to you. I just wanted you have a core insight into why SD is worth your time- whether you’re a builder, policy maker, or an investor.
With the Prologue sorted, let’s vibe our way into the preview of the main act.
Why Model Collapse Happens
Simply put, we can summarize the root cause behind why synthetic data leads to model collapse as follows:
The usage of low quality synthetic data reduces the diversity of the data that a model will sample from.
Done over many iterations, this will create increasingly narrow outputs, effectively reducing its capacities as a foundation model.
This was a key finding of the viral, “The Curse of Recursion: Training on Generated Data Makes Models Forget” (which kick-started a lot of the worries wrt to Synthetic Data): the sampling process of training on LLM (which are trained to predict the next probable token) outputs will eventually lead to your dataset over-repping the probable outcomes- changing the distribution of your data. Iterate once more, and this becomes more severe, until your improbable events get bullied out of generations. This is the principle of AI reinforcing your dataset biases, applied to LLMs-

While I have no problems with this, I do take issue with the two takeaways people took from this research-
Synthetic Data necessarily leads to Collapse: extremely untrue.
Human Data is always needed: it depends on your use case. If you need truly new kinds of data (your user behavior has fluctuated a lot), then user behavior will be better. However, in many many cases, pre-existing technologies are good enough to act as foundations (LLMs have already encoded a good amount of human data into their system) and synthetic data will be more than sufficient. People dramatically underestimate how powerful pre-existing systems are (a lie perpetuated by Silicon Valley trying to chase myths like Super-Intelligence in order to not have to face the difficult challenges of building around the limitations of the said systems).
Both of these are right enough to just be convincing but miss key points that are worth discussing. We will discuss them in the main section.
For now let’s move on to the other part of our trailer.
How to Address Model Collapse with Synthetic Data
If you squint just hard enough, you will notice an important fact. The issue isn’t inherently with synthetic data itself, but rather with how it’s generated. The process of using a naked LLM to generate SD leads to a loss of diversity. Conversely, doing something to preserve the diversity of your samples can stave off your model's collapse.
As is common in research, a softish rebuttal to the Model Collapse paper-Is Model Collapse Inevitable? Breaking the Curse of Recursion by Accumulating Real and Synthetic Data- was published, but it didn’t gain the attention that the original critique got. Take a look at the finding-
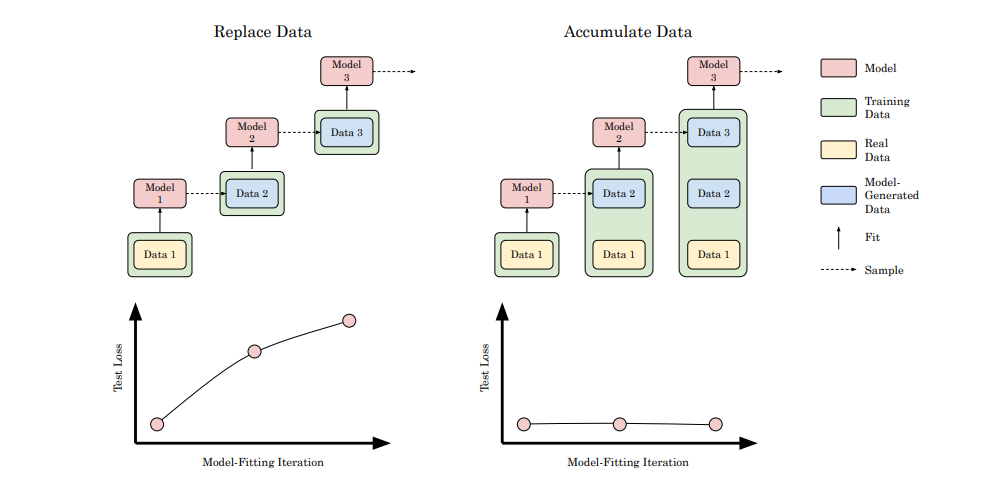
Keeping original data (which preserves data diversity) ensures that loss stays constant.
Read that again. If it was something inherent with SD, as many people think, then this phenomenon would not happen. Let’s look at some real numbers with real LLMs. Once again, replacement (reduction of diversity) causes the collapse, while accumulation (maintaining diversity) improves performance-

So instead of the sensationalist, “AI Training on AI will Collapse,” we get the much more boring “Diversity is key in maintaining and improving AI performance.” FYI- this is not a new finding. Meta showed this wonderfully, in their publication “Beyond neural scaling laws: beating power law scaling via data pruning” where they use intelligent sample selection to overcome power-law scaling (big Neural Network needs BIG data to get 1% performance improvement) by picking data samples that add “information” to the existing sample- “Such vastly superior scaling would mean that we could go from 3% to 2% error by only adding a few carefully chosen training examples, rather than collecting 10x more random ones”

If you want to go back earlier, Google’s “Self-training with Noisy Student improves ImageNet classification” dropped conceived, believed, and achieved their way into becoming the top model on ImageNet using 12 times fewer images (3.5 Billion Additional Labeled images for their competitors vs 300 Million Unlabeled images for the big G; notice the savings in labeled vs unlabeled as well) by injecting noise to create a more diverse training dataset/model representation.

I believe in your ability to big-brain your way into spotting a few trends here. But just because I’m in the mood to beat a dead horse, let me remind you off AlphaGo Zero, which surpassed every previous Go Player, including AlphaGo, using only self play (synthetic data). Synthetic Data wasn’t an issue for it since it was able to develop the required data diversity by playing against itself-

If you aren’t that interested in the details, you can peace out here (make sure you share this with some people who still believe in the model collapse before you go). Otherwise, here is the plan for the rest of the article-
We will first confirm that relying on Synthetic Data will, in fact, reduce diversity, looking both at the math of LLM generations and some interesting examples that demonstrate that LLMs tend to oversample from popular cases in their dataset.
Diversity is in fact an important driver of performance in Machine Learning Systems.
A closing note on stopping synthetic data collapse.
It’s Morbin time.

I put a lot of work into writing this newsletter. To do so, I rely on you for support. If a few more people choose to become paid subscribers, the Chocolate Milk Cult can continue to provide high-quality and accessible education and opportunities to anyone who needs it. If you think this mission is worth contributing to, please consider a premium subscription. You can do so for less than the cost of a Netflix Subscription (pay what you want here).
I provide various consulting and advisory services. If you‘d like to explore how we can work together, reach out to me through any of my socials over here or reply to this email.
Why LLMs Reduce Diversity
Here’s your Temu overview of how Large Language Models work and why that causes them to bias towards the probable-
At their core, Large Language Models operate on a foundation of vector representations (embeddings) that capture semantic relationships between tokens in high-dimensional space.
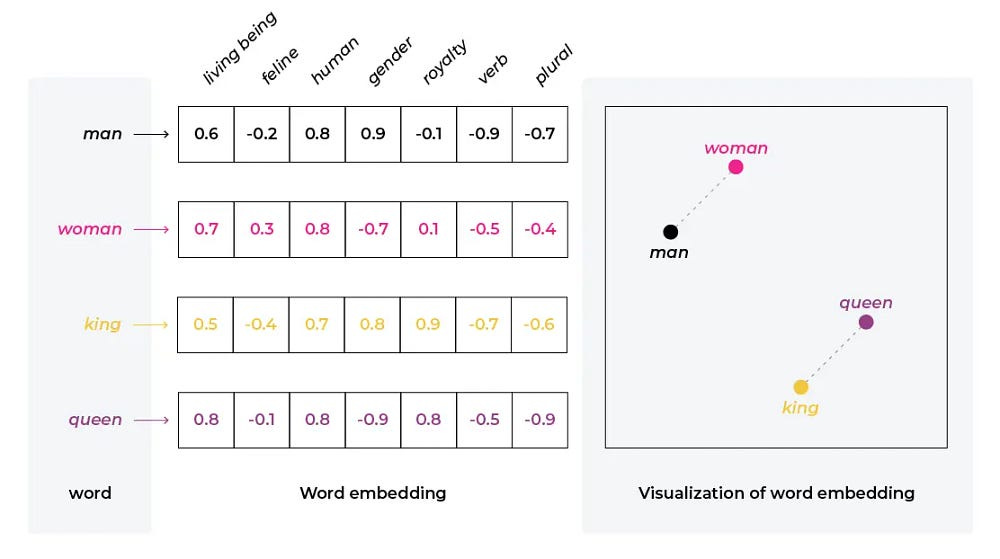
These models process input through multiple transformer layers, ultimately producing probability distributions over possible next tokens.
The critical aspect of this architecture lies in how these probabilities are sampled during generation. Most LLM implementations use sampling techniques like top-k or nucleus sampling (top-p) to select the next token, fundamentally biasing outputs toward high-probability events. In top-k sampling, only the k most likely tokens are considered for selection-

while nucleus sampling selects from tokens comprising the top p% of the probability mass.
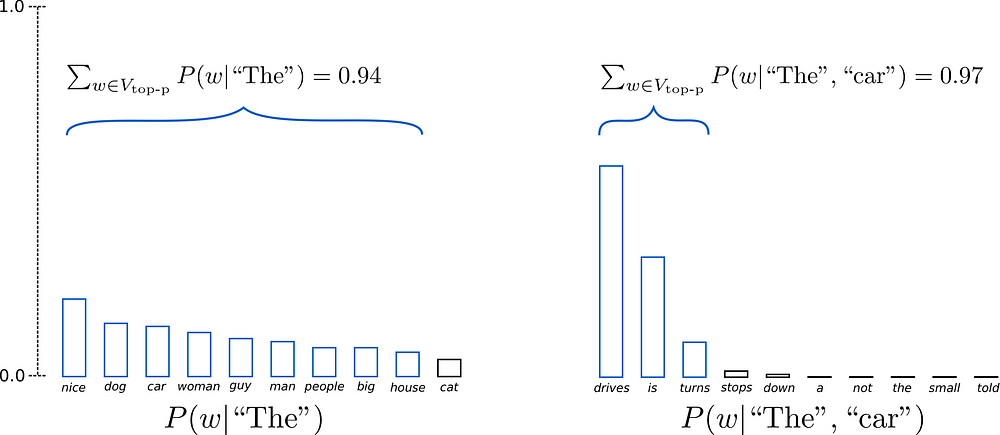
While these approaches help generate coherent and plausible outputs, they systematically exclude tokens with lower probabilities — often the very ones that represent edge cases and rare events.
This is why when asked to choose a number between 1 and 100, GPT picks 42 with overwhelming favoritism-

Or why Modern LLMs struggle to generate images of Clocks at specific times, since the training set overwhelmingly contains clocks with time at 10:10

Another example is from our testing of o-1’s Medical Eval capabilities. It creates an identical probability score (70–20–10) for the three most likely diseases, even as it changes the specific disease it’s diagnosing (note this is all for the identical output)-
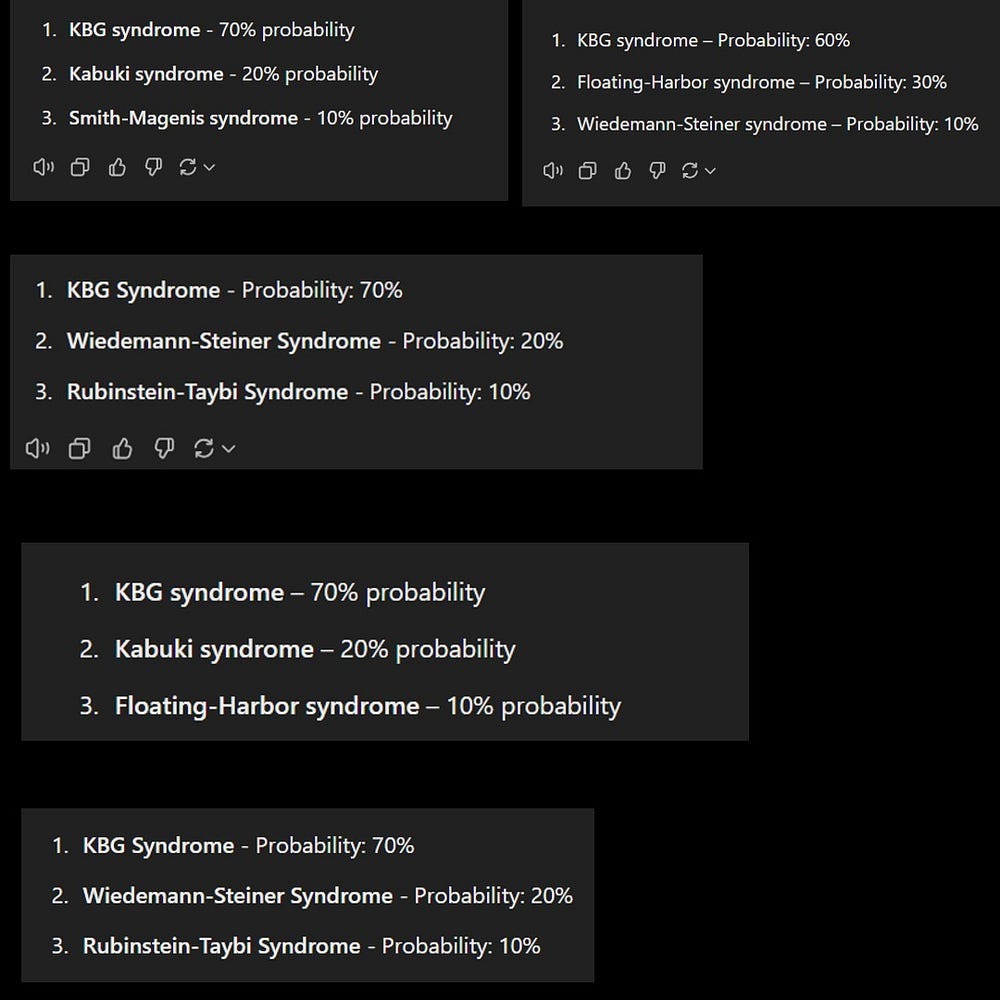
Even writing with aligned LLMs (most leading LLMs, and all the ones provided by major providers) reduces diversity-
“Large language models (LLMs) have led to a surge in collaborative writing with model assistance. As different users incorporate suggestions from the same model, there is a risk of decreased diversity in the produced content, potentially limiting diverse perspectives in public discourse.… This suggests that the recent improvement in generation quality from adapting models to human feedback might come at the cost of more homogeneous and less diverse content.”
- Does Writing with Language Models Reduce Content Diversity?
Speaking of alignment (which is literally telling what the model what to do, and what not to do) that has been shown to reduce LLM “creativity” (diversity of outputs). For instance, here is “Creativity Has Left the Chat: The Price of Debiasing Language Models”. It shows us that alignment limits the neighborhoods which the LLM samples from:

This is also shown here “The base model generates a wide range of nationalities, with American, British, and German being the top three. In contrast, the aligned model only generates three nationalities: American (highest percentage), Chinese, and a small percentage of Mexican.”

The most dramatic example of this is shown here:
“Finally, the distribution of customer gender (Figure 6) shows that the base model generates approximately 80% male and 20% female customers, while the aligned model generates nearly 100% female customers, with a negligible number of males.”

Hopefully, this convinces you that using LLM output as-is will reduce your data diversity. Onto the second act-
Why Diversity Matters Improves Machine Learning Systems
Diversity in different forms all leads to the same kind of result- the model is able to build richer representations of the input, improving the processing. Whether that’s on model side (using ensembles to explore more distributions and match them) or data side (using augmentation to stop overfitting and force generalization, the results are the same. Let’s look at the some practical use-cases.
Using Diverse Embeddings to Handle Chaotic Systems
“Interpretable predictions of chaotic dynamical systems using dynamical system deep learning” is a great example of how different kinds of representations can be combined to model very difficult problems.
As the authors observe, “the current dynamical methods can only provide short-term precise predictions, while prevailing deep learning techniques with better performances always suffer from model complexity and interpretability. Here, we propose a new dynamic-based deep learning method, namely the dynamical system deep learning (DSDL), to achieve interpretable long-term precise predictions by the combination of nonlinear dynamics theory and deep learning methods. As validated by four chaotic dynamical systems with different complexities, the DSDL framework significantly outperforms other dynamical and deep learning methods. Furthermore, the DSDL also reduces the model complexity and realizes the model transparency to make it more interpretable.”
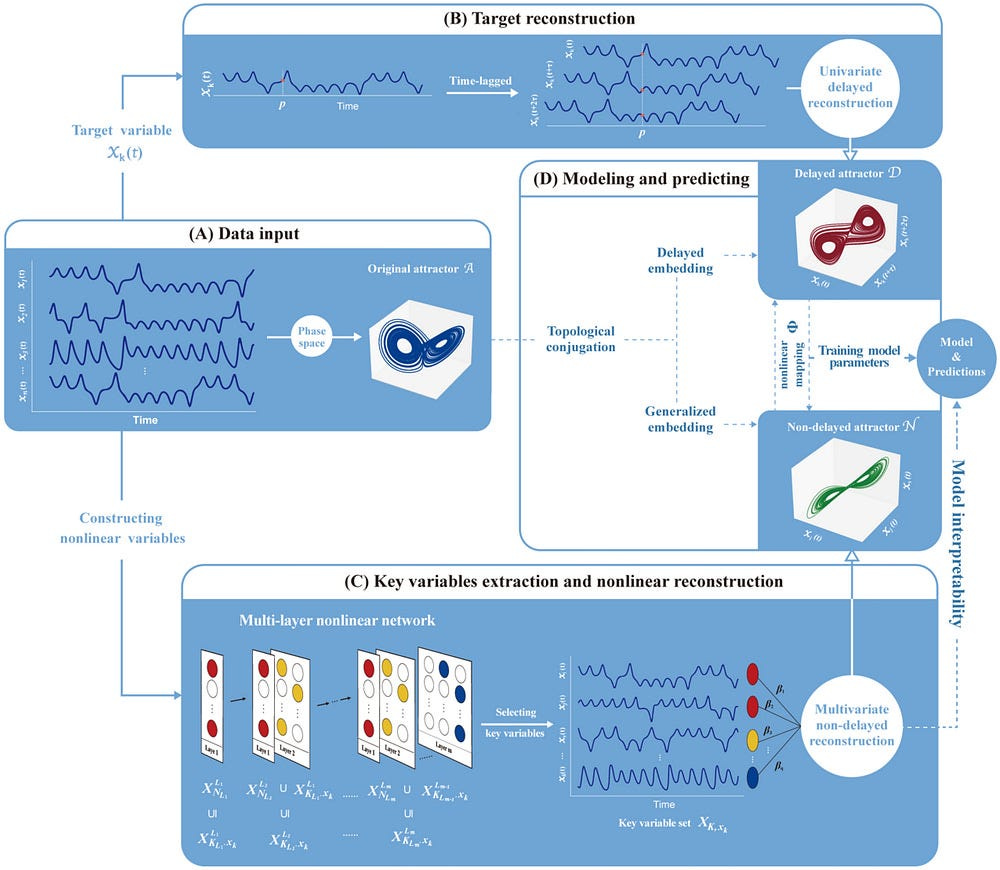

DSDL deserves a dedicated deep-dive (both b/c of how cool the idea is and b/c I don’t fully understand the implication of every design choice). While you wait, here is a sparknotes summary of the technique.
What DSDL does: DSDL utilizes time series data to reconstruct the attractor. An attractor is just the set of states that your systems will converge towards, even across a wide set of initial conditions. The idea of attractors is crucial in chaotic systems since they are sensitive to starting inputs.
DSDL combines two pillars to reconstruct the original attractor (A): univariate and multivariate reconstructions. Each reconstruction has its benefits. The Univariate way captures the temporal information of the target variable. Meanwhile, the Multivariate way captures the spatial information among system variables. Let’s look at how.
Univariate Reconstruction (D): This method reconstructs the attractor using the time-lagged coordinates of a single variable. Time-lagged coordinates are created by taking multiple samples of the variable at different points in time. This allows the model to capture the history of the system, which is important for predicting its future behavior. Imagine you are studying temperature fluctuations over time. The univariate approach would consider the temperature at a specific time, then the temperature at a slightly later time, and so on. This creates a sequence that incorporates the history of the temperature changes.
Multivariate Reconstruction(N): This method reconstructs the attractor using multiple variables from the system. This allows the model to capture the relationships between the different variables, which can be important for understanding the system’s dynamics. In the weather example, this approach might include not just temperature, but also pressure and humidity. By considering these variables together, the model can capture how they influence each other and contribute to the overall weather patterns. DSDL employs a nonlinear network to capture the nonlinear interactions among variables.
Finally, a diffeomorphism map is used to relate the reconstructed attractors to the original attractor. From what I understand, a diffeomorphism is a function between manifolds (which are a generalization of curves and surfaces to higher dimensions) that is continuously differentiable in both directions. In simpler terms, it’s a smooth and invertible map between two spaces. This helps us preserve the topology of the spaces. Since both N and D are equivalent (‘topologically conjugate’ in the paper), we know there is a mapping to link them.
All of this allows DSDL to make predictions on the future states of the system.
Before we get into the results, I’d recommend that you take a look at this yourself for 2 reasons: 1- There is a lot I have to learn about Time Series Forecasting and (esp. about) dynamical systems; 2- I had to Google “diffeomorphism” for this. There’s a good chance that I’m missing some context or on some crucial detail. If you have any additions or amendments to my summary of this, I’d love to hear it. Your critique will only help me share better information (think of it as a contribution to open-sourcing the theoretical parts of AI Research).
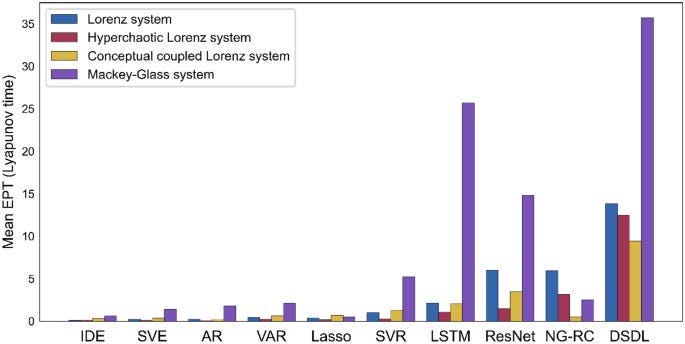
With that out of the way, let’s look at the numbers. DSDL clearly destroys the competition- doubling or even almost tripling the performance of the next best across tasks.
Why Ensembles Outperform Single Models4
Our results show that random initializations explore entirely different modes, while functions along an optimization trajectory or sampled from the subspace thereof cluster within a single mode predictions-wise, while often deviating significantly in the weight space. Developing the concept of the diversity — accuracy plane, we show that the decorrelation power of random initializations is unmatched by popular subspace sampling methods.
The paper “Deep Ensembles: A Loss Landscape Perspective” set out to prove why Ensembles outperformed Bayesian Neural Networks, even if they were all supposed to universally approximate. Their conclusion was simple- “popular scalable variational Bayesian methods tend to focus on a single mode, whereas deep ensembles tend to explore diverse modes in function space.”
When running a Bayesian Network at a single initialization it will reach one of the peaks and stop. Deep ensembles will explore different modes, therefore reducing error when put in practice. In picture form:
Depending on it’s hyperparameters, a single run of a bayesian network will find one of the paths (colors)and it’s mode. Therefore it won’t explore the set of parameters. On the other hand, a deep ensemble will explore all the paths, and therefore get a better understanding of the weight space (and solutions). To understand why this translates to better understanding consider the following illustration.

In the diagram, we have 3 possible solution spaces, corresponding to each of the trajectories. The optimized mode for each gives a performance gives us a score of 90% (for example). Each mode is unable to solve a certain kind of problem (highlighted in red). A Bayesian Network will get to either A, B, or C in a run while a Deep Ensemble will be able to train over all 3.
Diversity and Evolution
Another powerful vindication of the impact of diversity on foundation models comes from the paper, “Population-Based Evolution Optimizes a Meta-Learning Objective” where the authors note that implementing a simple evolution based Meta Learner that samples through different lineages so that it can develop adaptability (i.e the use of more diverse genomes directly improves performance):
“In evolutionary systems, genomes compete with each other to survive by increasing their fitness over generations. It is important that genomes with lower fitness are not immediately removed, so that competition for long-term fitness can emerge. Imagine a greedy evolutionary system where only a single high-fitness genome survives through each generation. Even if that genome’s mutation function had a high lethality rate, it would still remain. In comparison, in an evolutionary system where multiple lineages can survive, a genome with lower fitness but stronger learning ability can survive long enough for benefits to show”
Lastly, we can look the intersting research behind DataAugmentation policies and what they can teach us.

Trivial Augment vs Sophisticated Policies
In the beginning, there was only Brahman…. Oops, too far back.
Early Data Augmentation research would develop sophisticated policies that would process your dataset and try to create custom samples to fill up your dataset by applying a bunch of simpler policies to it (look in the image above for examples). This was/is expensive and adds little value. Think of it as a McKinsey Consultant.
Then come policies like TrivialAugment. It correctly identified two things-
Most places applying DA were working on increasingly massive datasets and “saturated” models.
The value added from DA here was diversity, which could be done much more simply.
So we get TA, the simplest possible augmentation policy-
TA works as follows. It takes an image x and a set of augmentations A as input. It then simply samples an augmentation from A uniformly at random and applies this augmentation to the given image x with a strength m, sampled uniformly at random from the set of possible strengths {0, . . . , 30}, and returns the augmented image.
-No deceptive marketing in the name
The simplicity means it doesn’t reinforce biases like tailor-made policies would. This increases diversity, allowing it to outperform everyone else-
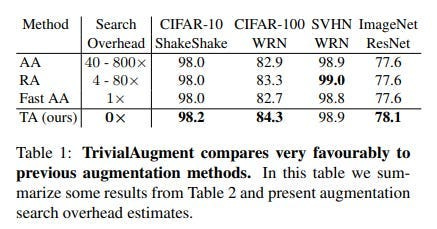
Part of the conclusion from the paper is worth stressing- Second, TA teaches us to never overlook the simplest solutions. There are a lot of complicated methods to automatically find augmentation policies, but the simplest method was so-far overlooked, even though it performs comparably or better.
Once again, I will leave it to your formidable pattern-matching skills to connect these dots.
Time to close this out.

How to Prevent Model Collapse in Generative AI
Large Language Models (LLM) are increasingly trained on data generated by other LLM, either because generated text and images become part of the pre-training corpus, or because synthetized data is used as a replacement for expensive human-annotation. This raises concerns about \emph{model collapse}, a drop in model performance when their training sets include generated data. Considering that it is easier for both humans and machines to tell between good and bad examples than to generate high-quality samples, we investigate the use of verification on synthesized data to prevent model collapse. We provide a theoretical characterization using Gaussian mixtures, linear classifiers, and linear verifiers to derive conditions with measurable proxies to assess whether the verifier can effectively select synthesized data that leads to optimal performance. We experiment with two practical tasks — computing matrix eigenvalues with transformers and news summarization with LLMs — which both exhibit model collapse when trained on generated data, and show that verifiers, even imperfect ones, can indeed be harnessed to prevent model collapse and that our proposed proxy measure strongly correlates with performance.
We’ve already touched upon some main ideas- ensembles, richer representations, and data augmentation to spike diversity. All of these are generally high ROI, conceptually simple ways to prevent Model Collapse. They’ll go a long way to help.
If you want to take it a step further, implementing multiple decoder pathways and adaptive sampling strategies helps maintain output diversity at the architectural level (the latter is something I’ve read but not really tried myself, so share your comments).

Our augmentation should be supported by implementing robust monitoring systems that track diversity metrics. When early signs of collapse are detected, the system can dynamically intervene by adjusting model parameters or triggering retraining on more diverse data subsets. Once again, this requires a good representation of your data (to accurately catch the loss of diversity), but this should be good for preventing the collapse.
Overall, I think the reports of model collapse are greatly overstated. While it is a concern, it’s not more of a function of a badl setup system than it is an inherently problematic element of Synthetic Data. As long as teams take the correct steps to account for the synthetic data and the possible loss of diversity from generative models, I believe the ROI of leveraging SD will be positive (assuming it is needed). SD might be a key to unlocking many future technologies (which is why I’ve been bullish on it for many years) and I think it’s worth investing into- especially for policy makers who want to promote transparent AI Research in sensitive domains.
What are your thoughts on this? Let me know.
Thank you for reading and I hope you have a wonderful day.
Your one and only,
Dev <3
If you liked this article and wish to share it, please refer to the following guidelines.
That is it for this piece. I appreciate your time. As always, if you’re interested in working with me or checking out my other work, my links will be at the end of this email/post. And if you found value in this write-up, I would appreciate you sharing it with more people. It is word-of-mouth referrals like yours that help me grow. You can share your testimonials over here.

Reach out to me
Use the links below to check out my other content, learn more about tutoring, reach out to me about projects, or just to say hi.
Small Snippets about Tech, AI and Machine Learning over here
AI Newsletter- https://artificialintelligencemadesimple.substack.com/
My grandma’s favorite Tech Newsletter- https://codinginterviewsmadesimple.substack.com/
My (imaginary) sister’s favorite MLOps Podcast-
Check out my other articles on Medium. : https://rb.gy/zn1aiu
My YouTube: https://rb.gy/88iwdd
Reach out to me on LinkedIn. Let’s connect: https://rb.gy/m5ok2y
My Instagram: https://rb.gy/gmvuy9
My Twitter: https://twitter.com/Machine01776819
🔥🔥🔥
👏👏