
How to Build Agentic AI[Agents]
Building on Anthropic AI’s “Building effective agents” to understand the best practices for building Agentic Systems (at this stage).

Hey, it’s Devansh 👋👋
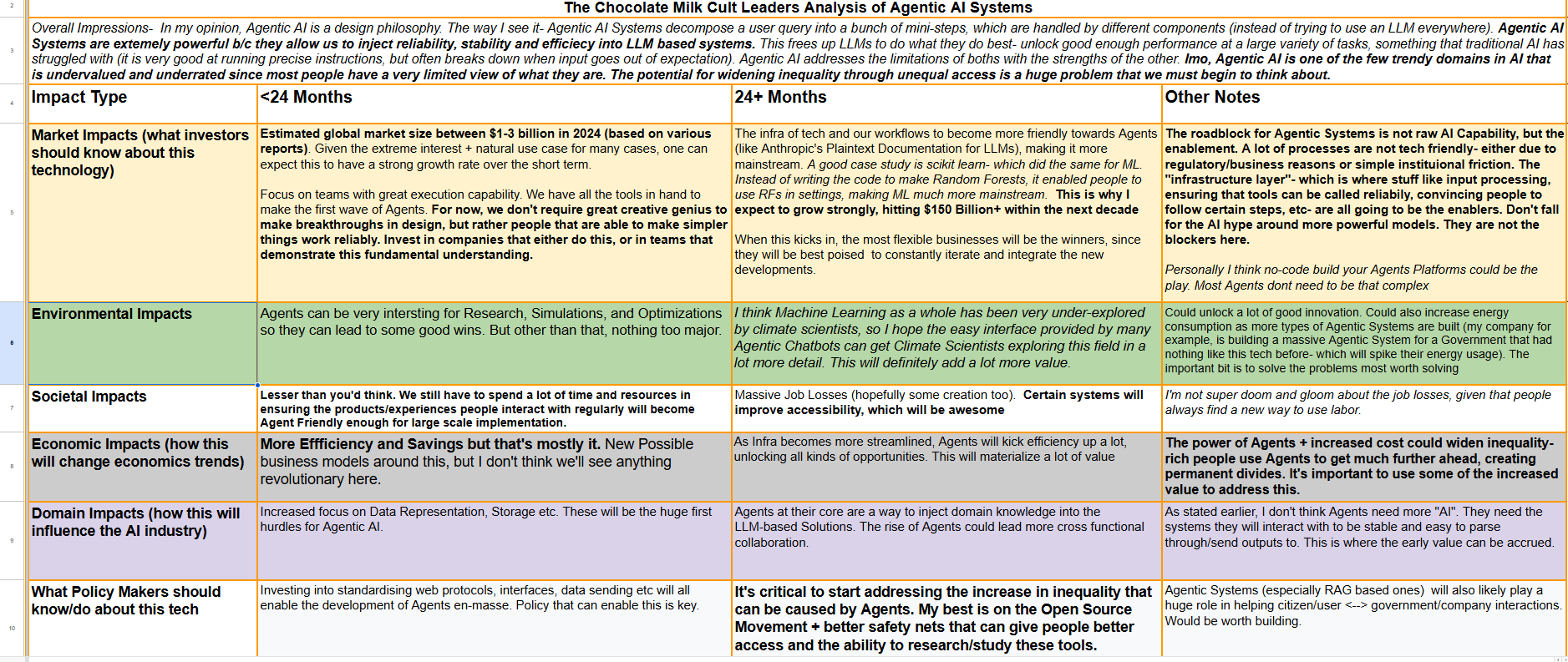
A lot of us are very excited about the future of Agentic AI. Agents is a series dedicated to exploring the research around Agents to facilitate the discussions that will create the new generation of Language Models/AI Systems. If you have any insights on Agents, reach out, since we need all the high-quality information we can get.
I put a lot of effort into creating work that is informative, useful, and independent from undue influence. If you’d like to support my writing, please consider becoming a paid subscriber to this newsletter. Doing so helps me put more effort into writing/research, reach more people, and supports my crippling chocolate milk addiction. Help me democratize the most important ideas in AI Research and Engineering to over 200K readers weekly. Many companies have a learning budget that you can expense this newsletter to. You can use the following for an email template to request reimbursement for your subscription.
PS- We follow a “pay what you can” model, which allows you to support within your means, and support my mission of providing high-quality technical education to everyone for less than the price of a cup of coffee. Check out this post for more details and to find a plan that works for you.
Recently, I came across Anthropic AI’s publication, “Building effective agents”. It summarizes their experience with building agents- both internally (with themselves) and externally (working with people). In this article, I want to build on their findings to communicate the best practices for building agentic systems. The aim is to build a timeless, first-principles guideline for building Agentic AI. To do so, I will combine my own research and reading with the hundreds (not an exaggeration) of conversations I’ve had with various people exploring the space in various capacities.
For this article, I would especially like to thank-
My coworkers at SVAM International, which has a very strong process automation and AI Agents Division, for sharing their insights/experiences with me. SVAM has been in the space for almost a decade (and in software solutions for more than 30 years), so hearing about their experiences helped me filter the lower and higher-impact research/techniques.
The team at IQIDIS, a leading Legal AI company built by lawyers for lawyers (I’m helping them build out their AI). IQIDIS leverages agents fairly extensively to help lawyers do the substantive work faster, and they’ve agreed to let me share some insights in how they accomplish this in this and future pieces (if you’re interested in the work- email info@iqidis.ai or fill out this short contact form)
I’m always looking for more collaborators, so please reach out either through my social media links (later in the article) or my email (devansh@svam.com) to talk. Our cult can provide the most actionable insights only because I can learn from all of you, and I’m deeply appreciative to all of you who take the time to talk to me.
As always, before we get into the technical details of this piece, here is my analysis of Agentic AI, from various perspectives. I would especially direct your attention to the Investor and Policy Maker sections(a reminder- please use a big screen for the best reading experience)-
Executive Highlights (TL;DR of the article)
The folks at Anthropic were nice enough to give us a summary of their article, so I’m going to quote it as is.
“Success in the LLM space isn’t about building the most sophisticated system. It’s about building the right system for your needs. Start with simple prompts, optimize them with comprehensive evaluation, and add multi-step agentic systems only when simpler solutions fall short.
When implementing agents, we try to follow three core principles:
Maintain simplicity in your agent’s design.
Prioritize transparency by explicitly showing the agent’s planning steps.
Carefully craft your agent-computer interface (ACI) through thorough tool documentation and testing.
Frameworks can help you get started quickly, but don’t hesitate to reduce abstraction layers and build with basic components as you move to production. By following these principles, you can create agents that are not only powerful but also reliable, maintainable, and trusted by their users.”
Here are some of my extended notes on these principles-
Simplicity First: The Power of “Just Enough”
When it comes to ML Engineering, just as with love, the most effective I can probably give you is to lower your standards (if you were really worth your high standards, you wouldn’t need dating advice from internet strangers).
It’s tempting to start exploring multi-agent systems, given the marketing of how powerful these systems are expected to be. However, as with most complex software, this can lead to a mess of undebuggable code that does not work.

Instead of overengineering a system, keep your first LLM Agent extremely minimal by augmenting your base LLM with the following:
Retrieval: The ability to access external knowledge bases.
Tools: The capacity to interact with external services (APIs, databases, etc). A lot of people want to use LLMs for very simple tasks (such as arithmetic, chaining instructions, simpler ML/AI-based scoring, etc), which would be better left to external functions.
Memory: The skill to retain information across interactions.
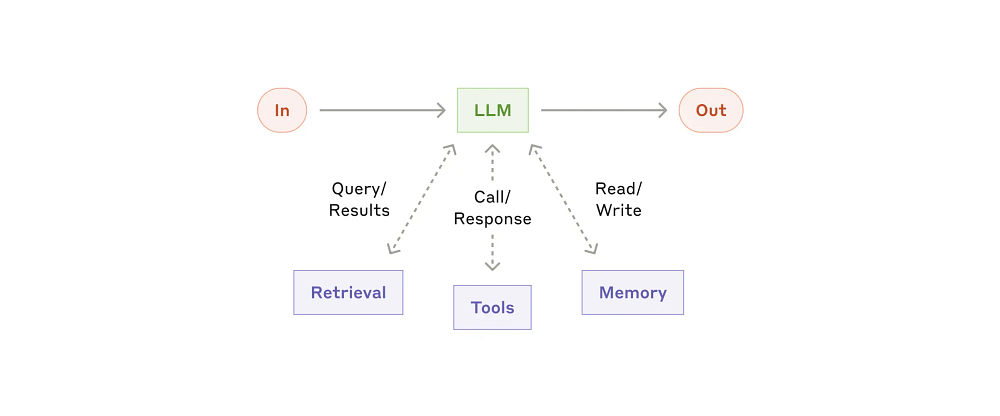
This will speed up the velocity of your iterations (always easier to build up than refit), drop your costs, and make debugging much easier. It’s also a good way to build more trust with your users (since they’ll be exposed to fewer errors). For a practical demonstration of this concept, take a look at this comparison of Devin and Cursor. Cursor does fewer things (it’s closer to the above architecture) but is still preferred since it has fewer errors, higher speed, and better user experience than Devin (based on a more powerful multi-agentic, A2-style architecture to enable more functionalities). Simplicity has many benefits, both external (with users) and internal (for your own teams)-
Within this research setting, we found that differences in architectural complexity could account for 50% drops in productivity, three-fold increases in defect density, and order-of-magnitude increases in staff turnover.
Don’t be scared to throw out a simple Agent system that handles a narrower scope. If you design the interactions well, it will still help your users solve their problems, which is ultimately why Tech is built.
Simplicity also helps us attain the next principle-
Transparency: Shedding Light on the AI’s Reasoning
Somewhat ironic that Anthropic put this as a principle, given how little LLM companies actually do for this, but I’m not going to throw shade here.
Trust is a critical factor in any AI application. If a system makes a decision without any explanation, users are unlikely to trust it, which means less usage, harder future improvements, etc. That is why transparency is a critical component of an effective agentic system.
Debuggability: When something goes wrong, a transparent system allows for quick diagnosis and course correction (a luxury not afforded to more black-box systems).
User Trust: Openly demonstrating the reasoning of an agent encourages adoption and reduces user skepticism.
Ethical Considerations: A transparent agent is also an ethical agent since it can be easily scrutinized and modified as necessary.
The trust aspect is one of the underappreciated why RAG systems have picked up so much steam and toppled more black box techniques like Fine Tuning and Prompt Engineering as the primary approach (another prediction that aged extremely well)-
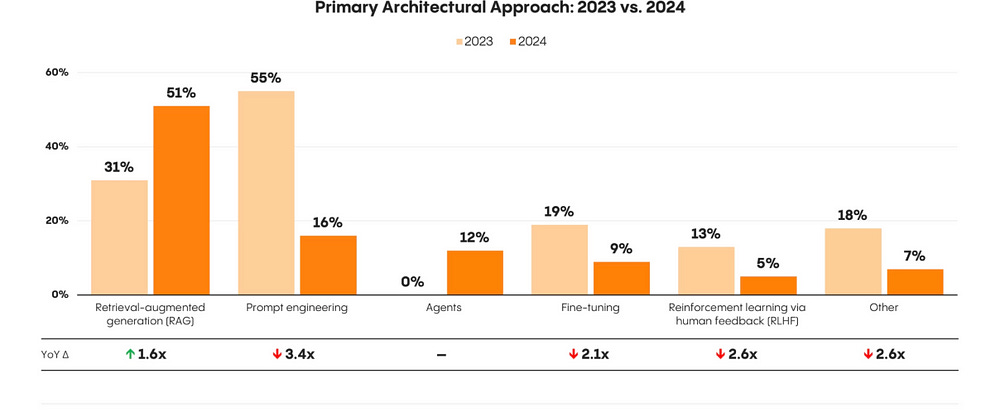
For a practical example of transparency being a good sell- the users of IQIDIS have loved the document citing functionality, which allows them to easily verify any claims/arguments-
Certain users also get access to the underlying embeddings and representations to allow them to see how the AI views the relationships between various entities in a given set of case documents. Below is an example for the Fannie Mae Regulations, showing how our AI understands the relationship between Desktop Underwriter and Form 1003 (the users are able to edit the connections/relationships, allowing their AI to customize it’s outputs based on their unique knowledge).
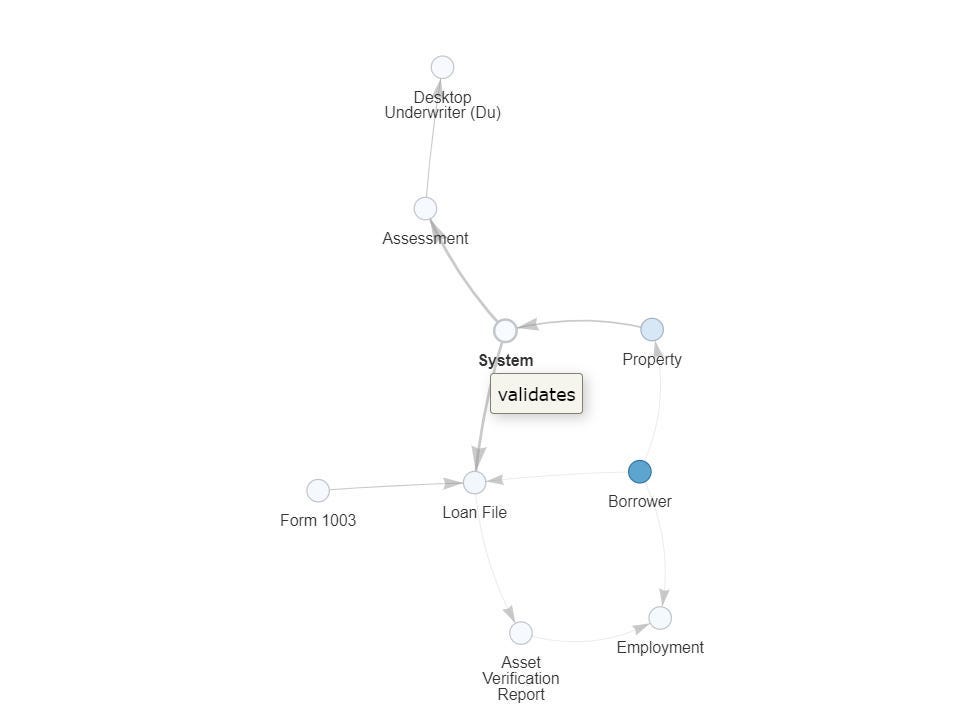
Both these features have been huge sellers for IQIDIS, since this allows our users to understand why the AI came up with a certain argument/claim, letting them trust the product more (a lot of the productivity gains from Gen AI are wiped out because the users spend more time verifying/debugging outputs).
All of this is tied together by the final principle: good design.
3. The Agent-Computer Interface (ACI): The Unsung Hero
Human-computer interfaces (HCIs) are an essential component of software. It’s important to apply the same degree of attention to how the AI agent interacts with its tools. It’s not enough for an agent to be capable; the agent needs to use those capabilities reliably. We call the design of systems that ensure that AI Agents can effectively interact with their environments ACI.
Tools are Critical: Tools are not a “nice to have” but a core aspect of effective systems.
Well-Defined Tools: Tool definitions should be as comprehensive as possible, clearly specifying input and output formats, edge cases, and boundaries, and have clear examples of use. This guides the AI to better neighborhoods, leading to fewer errors.
Thorough Documentation: Same point as above, documentation helps your Agents pick tools better. It also provides great feedback for future improvements.
Iterative Testing: Your tools can get caught up in huge loops. It’s important to test this both to ensure it works when it should and doesn’t when it shouldn’t.
Poka-Yoke your tools: The article’s suggestion of “poka-yoke” (mistake-proofing by adding constraints) your tools is fantastic. Tools should be designed so that the agent cannot easily misuse them.
Since the authors mentioned SWE-Bench, I think it’s good to use that as an example of this principle. The main section of ACI will cover how ACI enables high performance on SWE-Bench.
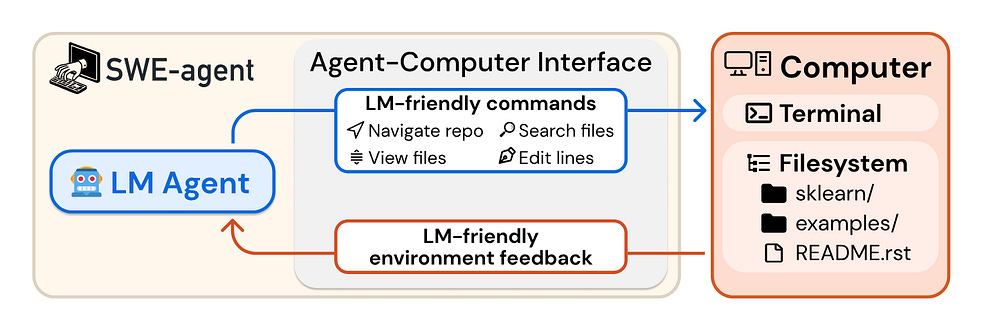
Besides this, another very important thing I found was the decomposition of Agentic AI Systems into different kinds of systems. Firstly, we have the workflow-based Agentic Systems, which send LLMs, their tools, and the other components of their systems through well-defined processes. Then we have Agent-Based Agentic AI Systems, which give LLMs a lot more freedom in when/how to call tools. These are good for different things-
When more complexity is warranted, workflows offer predictability and consistency for well-defined tasks, whereas agents are the better option when flexibility and model-driven decision-making are needed at scale. For many applications, however, optimizing single LLM calls with retrieval and in-context examples is usually enough.
Personally, I thought this was the most important idea they discussed. The article only gives a few sentences of attention to this concept, so we will start by exploring it in a lot more detail, with my thoughts on how these differing subtypes are better for different kinds of development. This is why the main section of our deep-dive will start here.
The main section will cover-
What is Agentic AI.
Building on workflow-based Agentic AI vs. agent-based Agentic AI.
A deeper dive on how to build better Agent Computer Interfaces + the case study mentioned. A very special shoutout to Mradul Kanugo, Chief AI officer at Softude for sharing his insights on this (Bro is an absolute AI Fiend, so if you want to learn more about the field- reach out to him on LinkedIn over here or follow his Twitter @MradulKanugo).
Practical Strategies for composing Agentic Systems (different kinds of architectures you can apply).
Keep reading if this interests you.
I put a lot of work into writing this newsletter. To do so, I rely on you for support. If a few more people choose to become paid subscribers, the Chocolate Milk Cult can continue to provide high-quality and accessible education and opportunities to anyone who needs it. If you think this mission is worth contributing to, please consider a premium subscription. You can do so for less than the cost of a Netflix Subscription (pay what you want here).
I provide various consulting and advisory services. If you‘d like to explore how we can work together, reach out to me through any of my socials over here or reply to this email.
So… what is Agentic AI
While a lot of people talk about agents in terms of memory, tools, etc., I find this view of agents very narrow. To quote our earlier exploration on my favorite model for AI Orchestration- “The way I see it- Agentic AI Systems decompose a user query into a bunch of mini-steps, which are handled by different components. Instead of relying on a main LLM (or another AI) to answer a complex user query in one shot, Agentic Systems would break down the query into simpler sub-routines that tackle problems better…
Agentic AI is a way to ensure your stuff works by making the AI take auditable steps that we can control and correct. This gives us better accuracy, fewer uncontrollable errors, and the ability to tack on more features.”
Anthropic further differentiates Agentic AI Systems into two subtypes of architectures-
Workflows are systems where LLMs and tools are orchestrated through predefined code paths.
Agents, on the other hand, are systems where LLMs dynamically direct their own processes and tool usage, maintaining control over how they accomplish tasks. I’m going to call this A2, to prevent confusion with Agentic AI the overarching design philosophy (which contains the workflow subtype as well).
Workflows are system teams like prime Barca (or any of Peps teams)- where the vision and plays are laid out meticously. Players do get creativity on the field, but it’s creativity to implement the vision already laid out for the team. At their best, they are operate with extreme dominance and efficiency, since their pre-defined vision allows them to optimize every detail of execution. However, they run the risk of becoming stale and robotic, and often fall apart if a key component collapses (see Man City and Rodri).
A2, on the other hand, is like Don Carlo’s Real Madrid. We add in a lot of high quality components, define the loose overarching goal, and then let the components figure it out through the magical power of Friendship and Vibes. At it’s best- you get an extremely flexible system which can handle a wide set of challenges, and will often surpass your expectations (how many times does Peak Madrid pull off comebacks when nothing seems to be working). However, these systems also tend to collapse spectacularly, at which point diagnosing issues and fixing them can be much harder w/o rebuilding significant components (see again Madrid and their difficulties on the Wing).
To me, most good agentic AI systems lie on a spectrum that borrows principles from both these subtypes. Personally, I have a strong bias towards defining most of the processing workflow manner as rigorously as possible (80–90% of the processing is done through defined protocols), with the dynamic tool calling and creativity only being applied for last-mile delivery. This allows me to build systems that are more reliable and precise, which comes from my background in building performant ML Systems in low-resource, high-noise, and high-scale environments. The additional reliability and precision allow me to control the outputs and account for errors, ensuring-
Users get the outputs they want in the way they want (traditional LLMs and A2 are horrible for precise tasks like Precise Formatting, building case argumentation by following an elaborate strategy, etc.).

Costs are kept very low.
The cost of failure can be minimized since checks are easier to build. Costs of A2 systems can spiral out of control if they get stuck in non-helpful loops or trigger a random error- a no-no in a consumer-facing SAAS platform.
Of course, this has its own drawbacks- mainly that you need a lot of domain knowledge to set up a workflow-oriented Agentic AI system effectively. IQIDIS pulls this off by being aggressively lawyer-led, where the CEO and advisors map out every possible decision/step taken by a lawyer in a case to identify the highest ROI steps. Some of our (SVAM’s) other clients do so by limiting their scope through constraining input, disclaimers, and other such practices.
From a solution development perspective, workflow-heavy agentic systems are best for vertical plays since they can pass on cost savings to their users while maintaining high performance. A2-based systems are better for horizontal plays since they are inherently more flexible. It’s not a coincidence that most frontier AI Research is biased towards A2 since it’s done by tech people, not domain experts, and thus focuses more on general applicability. By itself, this is fine, but too many AI teams building Vertical AI Products (AI for X) blindly copy the process of frontier AI Labs, not appreciating that they are playing a very different game.
Going back to Legal AI (a field I’m studying a lot now)- this is why we haven’t had a great new Legal AI product despite the billions of Dollars raised by startups (and incumbents). Based on my testing, the players seem to be following the wrong playbook for improving results, which leads to mediocre outputs and much higher cloud computing bills-
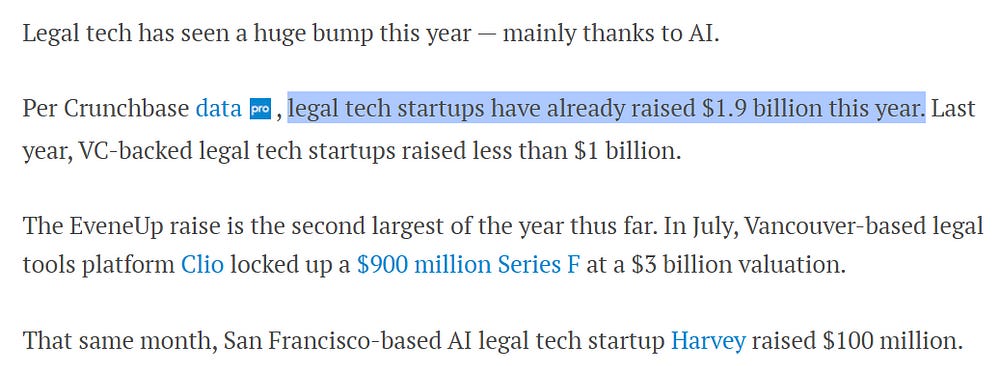
This is likely also true for other fields like Finance and Medicine, but would love to hear your experiences with this.
We have multiple deep-dives and discussions on simplicity and the importance of transparency. So I’m going to skip those sections here to not bore you too much. Let’s discuss ACI, which is not something I touch on much.
How to Build Effective ACI?
When it comes to building effective interfaces for agents, here are some key properties to consider:
Simplicity and clarity in actions: ACIs should prioritize actions that are straightforward and easy to understand. Rather than overwhelming agents with a plethora of options and complex documentation, commands should be concise and intuitive. This approach minimizes the need for extensive demonstrations or fine-tuning, enabling agents to utilize the interface effectively with ease.
Efficiency in operations: ACIs should aim to consolidate essential operations, such as file navigation and editing, into as few actions as possible. By designing efficient actions, agents can make significant progress toward their goals in a single step. It is crucial to avoid a design that requires composing multiple simple actions across several turns, as this can hinder the streamlining of higher-order operations. If you see a long composition consistently, write a routine that runs it one command.
Informative environment feedback: High-quality feedback is vital for ACIs to provide agents with meaningful information about the current state of the environment and the effects of their recent actions. The feedback should be relevant and concise, avoiding unnecessary details. For instance, when an agent edits a file, updating them on the revised contents is beneficial for understanding the impact of their changes.
Guardrails to mitigate error propagation: Just like humans, language models can make mistakes when editing or searching. However, they often struggle to recover from these errors (going into unproductive loops is surprisingly common for LLM based systems). Implementing guardrails, such as a code syntax checker that automatically detects mistakes, can help prevent error propagation and assist agents in identifying and correcting issues promptly.
Let’s look at a case study to see how these principles can implemented IRL-
How SWE-Agent Uses Effective ACIs to Get Things Done
SWE-Agent provides an intuitive interface for language models to act as software engineering agents, enabling them to efficiently search, navigate, edit, and execute code commands. The system is built on top of the Linux shell, granting access to common Linux commands and utilities. Let’s take a closer look at the components of the SWE-Agent interface.

Search and Navigation
In the typical Shell-only environment, language models often face challenges in finding the information they need. They may resort to using a series of “cd,” “ls,” and “cat” commands to explore the codebase, which can be highly inefficient and time-consuming. Even when they employ commands like “grep” or “find” to search for specific terms, they sometimes encounter an overwhelming amount of irrelevant results, making it difficult to locate the desired information.
SWE-Agent addresses this issue by introducing special commands such as “find file,” “search file,” and “search dir.” These commands are designed to provide concise summaries of search results, greatly simplifying the process of locating the necessary files and content. The “find file” command assists in searching for filenames within the repository, while “search file” and “search dir” allow for searching specific strings within a file or a subdirectory. To keep the search results manageable, SWE-Agent limits them to a maximum of 50 per query. If a search yields more than 50 results, the agent receives a friendly prompt to refine their query and be more specific. This approach prevents the language model from being overwhelmed with excessive information and enables it to identify the relevant content quickly.
The above is particularly important when we look at research like Diff Transformer, which explores how often Transformers overemphasize useless information.
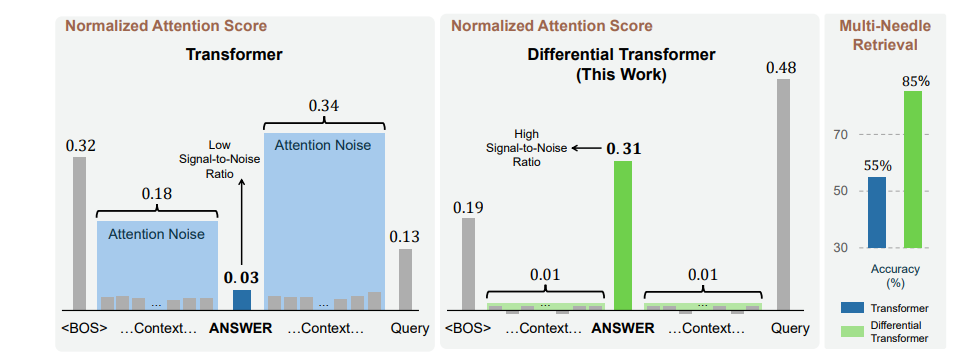
This is one of the reasons I don’t really put too much weight on an LLM’s context window since they often fall apart when we start to hit higher token counts (context corruption is a real problem). The best way to reduce inaccuracy and increase generation quality for LLMs is to reduce the amount of information they have to look at.
File Viewer
Once the models have located the desired file, they can view its contents using the interactive file viewer by invoking the “open” command with the appropriate file path. The file viewer displays a window of at most 100 lines of the file at a time. The agent can navigate this window using the “scroll down” and “scroll up” commands or jump to a specific line using the “goto” command. To facilitate in-file navigation and code localization, the full path of the open file, the total number of lines, the number of lines omitted before and after the current window, and the line numbers are displayed.
The File Viewer plays a crucial role in a language agent’s ability to comprehend file content and make appropriate edits. In a Terminal-only setting, commands like “cat” and “printf” can easily inundate a language agent’s context window with an excessive amount of file content, most of which is typically irrelevant to the issue at hand. SWE-Agent’s File Viewer allows the agent to filter out distractions and focus on pertinent code snippets, which is essential for generating effective edits.
File Editor
SWE-Agent offers commands that enable models to create and edit files. The “edit” command works in conjunction with the file viewer, allowing agents to replace a specific range of lines in the open file. The “edit” command requires three arguments: the start line, end line, and replacement text. In a single step, agents can replace all lines between the start and end lines with the replacement text. After edits are applied, the file viewer automatically displays the updated content, enabling the agent to observe the effects of their edit immediately without the need to invoke additional commands.
SWE-Agent’s file editor is designed to streamline the editing process into a single command that facilitates easy multi-line edits with consistent feedback. In the Shell-only setting, editing options are restrictive and prone to errors, such as replacing entire files through redirection and overwriting or using utilities like “sed” for single-line or search-and-replace edits. These methods have significant drawbacks, including inefficiency, error-proneness, and lack of immediate feedback. Without SWE-Agent’s file editor interface, performance drops significantly.
To assist models in identifying format errors when editing files, a code linter is integrated into the edit function, alerting the model of any mistakes introduced during the editing process. Invalid edits are discarded, and the model is prompted to attempt editing the file again. This intervention significantly improves performance compared to the Shell-only and no-linting alternatives.
Context Management
The SWE-Agent system employs informative prompts, error messages, and history processors to maintain the agent’s context concise and informative. Agents receive instructions, documentation, and demonstrations on the correct use of bash and ACI commands. At each step, agents are instructed to generate both a thought and an action. Malformed generations trigger an error response, prompting the model to try again until a valid generation is received. Once a valid generation is received, past error messages are omitted except for the first. The agent’s environment responses display computer output using a specific template, but if no output is generated, a message stating “Your command ran successfully and did not produce any output” is included to enhance clarity. To further improve context relevance, observations preceding the last five are each collapsed into a single line, preserving essential information about the plan and action history while reducing unnecessary content. This allows for more interaction cycles and avoids outdated file content.
To end this piece, let’s talk about some techniques that can allow your agents to handle more complex tasks.
Techniques for Building More Powerful AI Agents
Once you have the core building blocks (LLM, tools, retrieval, memory), you can explore patterns for greater sophistication. Anthropic’s article has very snappy summaries, so I’m going to leave them as is-
Prompt chaining
Decomposing a complex task into a sequence of prompts. A way of making it easier to handle and not start to identify where things are collapsing (seperation of concerns, but with prompts)
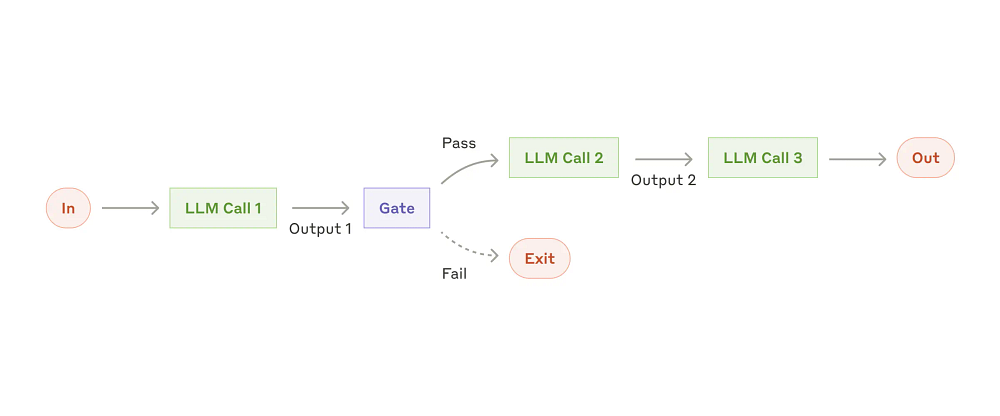
This is ideal for situations where the task can be cleanly decomposed into fixed subtasks.
Examples where prompt chaining is useful:
Generating Marketing copy, then translating it into a different language.
Writing an outline of a document, checking that the outline meets certain criteria, then writing the document based on the outline.
Routing
Routing classifies an input and directs it to a specialized follow-up task. This workflow allows for the separation of concerns and the building of more specialized prompts or relying on other components like Classifiers, Rule Engines, etc. Without this workflow, optimizing for one kind of input can hurt performance on other inputs (as is often seen in AI safety settings).
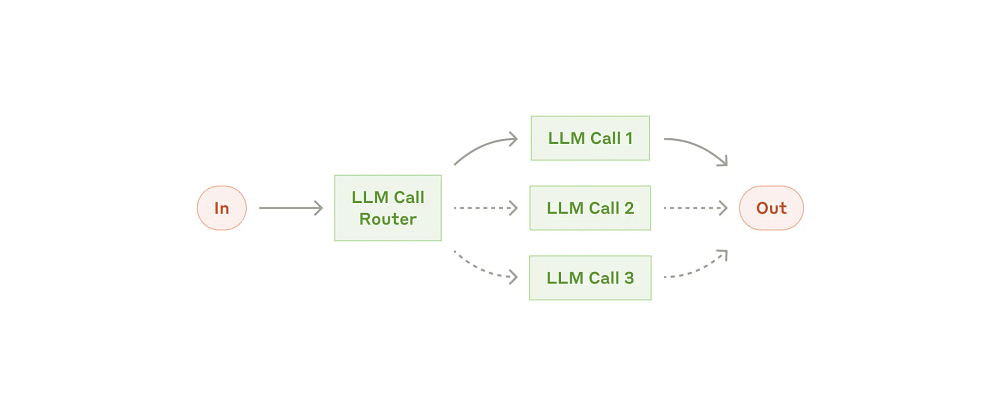
Below is an example of a more complex router, that one often sees in RevOps circles(my first real project in LLMs was something similar- taking English queries from non technical users and creating multi-dataset SQL queries based on them).
Parallelization
“LLMs can sometimes work simultaneously on a task and have their outputs aggregated programmatically. This workflow, parallelization, manifests in two key variations:
Sectioning: Breaking a task into independent subtasks run in parallel.
Voting: Running the same task multiple times to get diverse outputs.
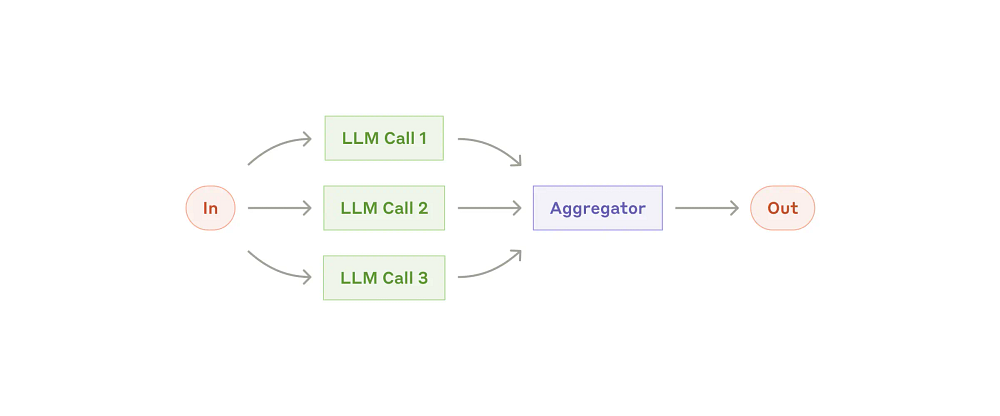
When to use this workflow: Parallelization is effective when the divided subtasks can be parallelized for speed, or when multiple perspectives or attempts are needed for higher confidence results. For complex tasks with multiple considerations, LLMs generally perform better when each consideration is handled by a separate LLM call, allowing focused attention on each specific aspect.
Examples where parallelization is useful:
Sectioning:
Implementing guardrails where one model instance processes user queries while another screens them for inappropriate content or requests. This tends to perform better than having the same LLM call handle both guardrails and the core response.
Automating evals for evaluating LLM performance, where each LLM call evaluates a different aspect of the model’s performance on a given prompt.
Voting:
Reviewing a piece of code for vulnerabilities, where several different prompts review and flag the code if they find a problem.
Evaluating whether a given piece of content is inappropriate, with multiple prompts evaluating different aspects or requiring different vote thresholds to balance false positives and negatives.”
I’m guessing a lot of the inference compute scaling (giving more compute budgets to inference tokens as opposed to training) will be leveraging this heavily. I’m a bit skeptical of this, given how expensive this is likely to get.

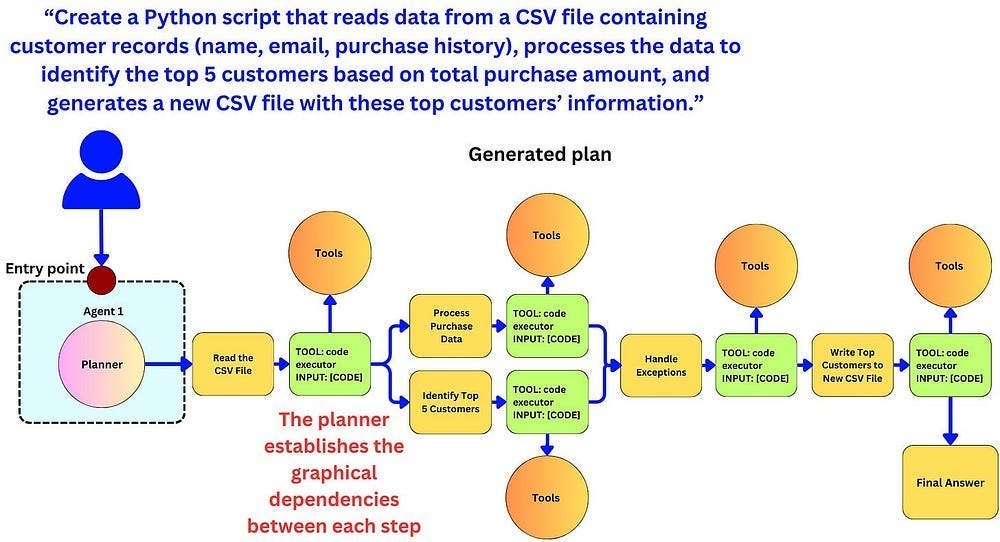
Orchestrator-workers
In the orchestrator-workers workflow, a central LLM dynamically breaks down tasks, delegates them to worker LLMs, and synthesizes their results.
As mentioned earlier, this is my favorite way of building more complex systems. I like the control this gives me. RAGs are a good example of orchestration (although they might not seem like it), especially if you involve Intent Classification and more complex kinds of retrieval. For example, at IQIDIS we have use specialized agents for user profiling and personalized output generations, context aware retrieval, and much more. Some details on how we do the latter are covered here.
Evaluator-optimizer
“In the evaluator-optimizer workflow, one LLM call generates a response while another provides evaluation and feedback in a loop.
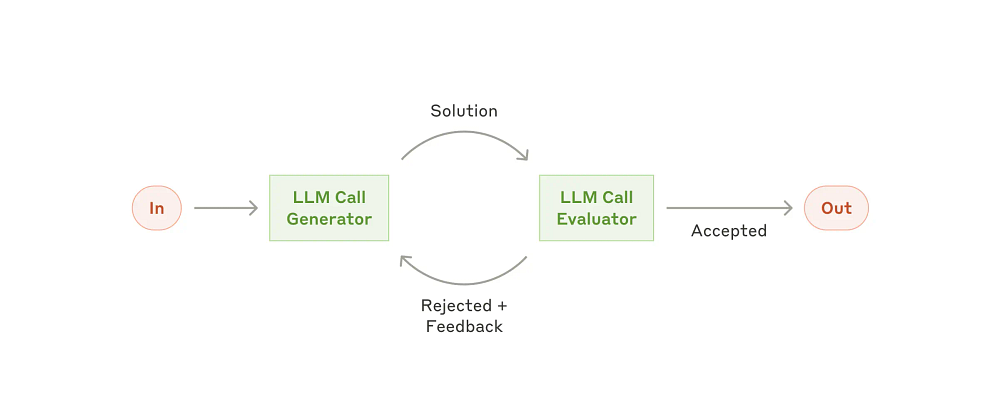
When to use this workflow: This workflow is particularly effective when we have clear evaluation criteria, and when iterative refinement provides measurable value. The two signs of good fit are, first, that LLM responses can be demonstrably improved when a human articulates their feedback; and second, that the LLM can provide such feedback. This is analogous to the iterative writing process a human writer might go through when producing a polished document.
Examples where evaluator-optimizer is useful:
Literary translation where there are nuances that the translator LLM might not capture initially, but where an evaluator LLM can provide useful critiques.
Complex search tasks that require multiple rounds of searching and analysis to gather comprehensive information, where the evaluator decides whether further searches are warranted.”
I like LLMs as judges, but it’s important to set things up well to avoid a lot of the problems mentioned earlier. It’s a delicate balancing act to pull off.
There’s also some interesting writing on Agents for more autonomous work, but personally I don’t buy it as a useful pattern. I think there is too much variance for me to recommend it to anyone. If you disagree, I’d love to hear your thoughts on it.
Thank you for reading and have a wonderful day.
Dev <3
If you liked this article and wish to share it, please refer to the following guidelines.
That is it for this piece. I appreciate your time. As always, if you’re interested in working with me or checking out my other work, my links will be at the end of this email/post. And if you found value in this write-up, I would appreciate you sharing it with more people. It is word-of-mouth referrals like yours that help me grow. You can share your testimonials over here.

Reach out to me
Use the links below to check out my other content, learn more about tutoring, reach out to me about projects, or just to say hi.
Small Snippets about Tech, AI and Machine Learning over here
AI Newsletter- https://artificialintelligencemadesimple.substack.com/
My grandma’s favorite Tech Newsletter- https://codinginterviewsmadesimple.substack.com/
My (imaginary) sister’s favorite MLOps Podcast (over here)-
Check out my other articles on Medium. : https://rb.gy/zn1aiu
My YouTube: https://rb.gy/88iwdd
Reach out to me on LinkedIn. Let’s connect: https://rb.gy/m5ok2y
My Instagram: https://rb.gy/gmvuy9
My Twitter: https://twitter.com/Machine01776819
I too prefer the planner/orchestrator subbing out to worker LLMs as required. Also… Zubimendi to City. Pep agrees with you.
Similar thinking as mine (in the end i was long time enterprise architect responsible for f500 infra/app stacks:)))) and the swarm idea is something i will explore more in detail, it kind of fits in my thinking of the future of ai (call it agentic or not) where we will have multiple actors negotiating who will do the task at hand, for what cost and with its own requirements......and output precision/forecast of the outcomes:))))))