


Kimi K2 is the most important model of the year [Breakdowns]
How Moonshot AI built the Better DeepSeek.

It takes time to create work that’s clear, independent, and genuinely useful. If you’ve found value in this newsletter, consider becoming a paid subscriber. It helps me dive deeper into research, reach more people, stay free from ads/hidden agendas, and supports my crippling chocolate milk addiction. We run on a “pay what you can” model—so if you believe in the mission, there’s likely a plan that fits (over here).
Every subscription helps me stay independent, avoid clickbait, and focus on depth over noise, and I deeply appreciate everyone who chooses to support our cult.
PS – Supporting this work doesn’t have to come out of your pocket. If you read this as part of your professional development, you can use this email template to request reimbursement for your subscription.
Every month, the Chocolate Milk Cult reaches over a million Builders, Investors, Policy Makers, Leaders, and more. If you’d like to meet other members of our community, please fill out this contact form here (I will never sell your data nor will I make intros w/o your explicit permission)- https://forms.gle/Pi1pGLuS1FmzXoLr6
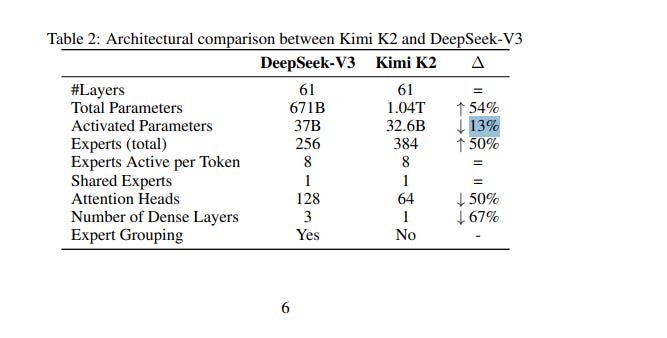
Generally, I ignore most AI Model releases. Beyond some interesting engineering decisions, there isn’t much for me to say. However, Kimi K2 is not that (FYI they released their technical report on Github not arXiv, which makes it harder for some people and AI Tools to find). Some of the core engineering decisions made by the Moonshot team carry moonumental consequences. For engineers, yes, but also for policy makers and investors.

Kimi is not 2008 Barca, but it is 1970s Dutch Team, bringing Total Football to the world. Kimi K2 is not Tom Aspinall, but it is Fedor w/ those beautifully terrifying baby blues. Kimi K2 is not Usyk, but it is Jack Dempsey and his boxing philosophy. It’s not the refined culmination stacked by optimizing the existing paradigm. Kimi K2 is the ground zero for a new way to build AI. Behind the technical details and math discussions is a powerful thesis on AI- where it is, where it’s struggling, and how we will break through to the next level.
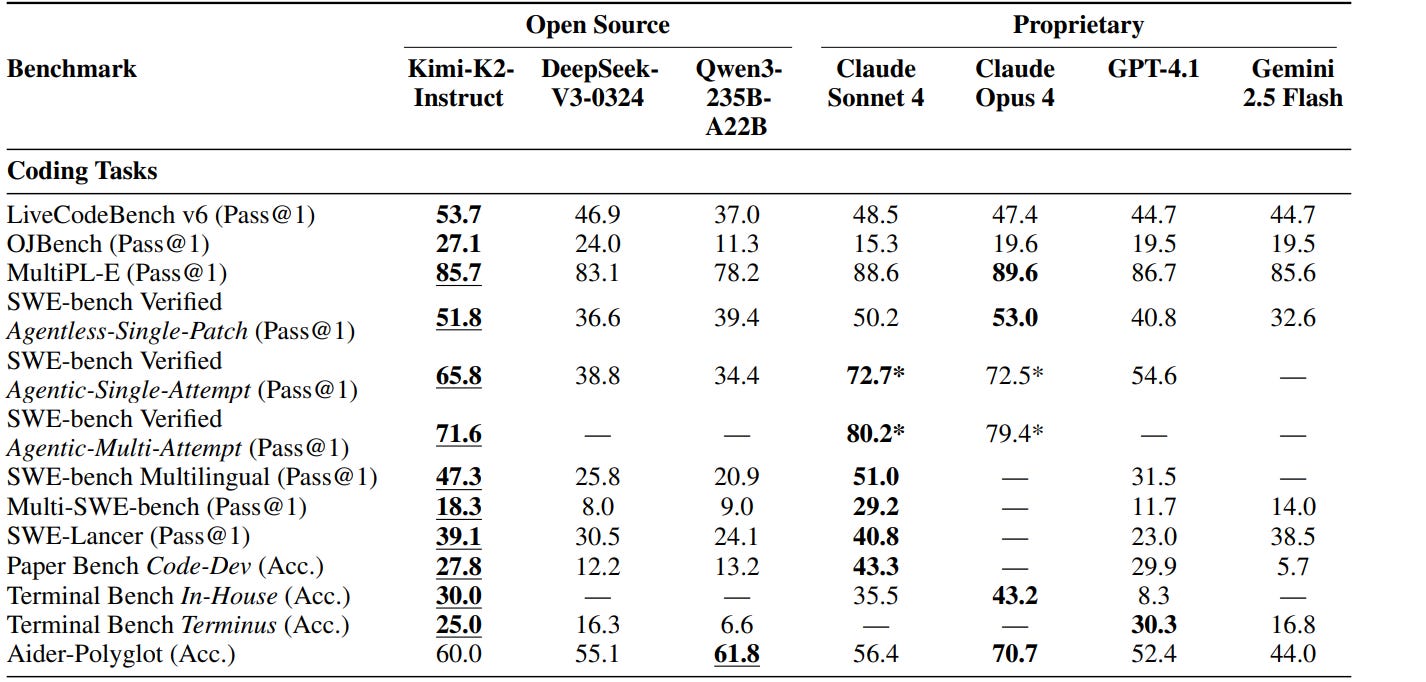
Kimi K2 is the most important AI Model released this year (Gemini 2.5 Flash is my other pick for this title, but there isn’t much information on it). By the end of this article, I will show you why. Our analysis will focus on 3 pillars:
Moonshot AI Loves Curves: Muon is bigger departure from Optimizers than people realize. The algorithm (primitively) accounts for the Geometry of the space, which requires more complex operations than our current GPUs/Infra are optimized for. We’ll break this down more.
An Industrial-Scale Skill Factory: Their agentic data generation protocol is an engine for manufacturing multi-step experience+ native tool use, with integrated verifiers serving as the non-negotiable quality control. This is the first industrial-scale proof that the Verifier Economy is the only path to reliable agents.
Reward Models in the Future: On the last note, an increase in verifiers also increases the appetite to blend them. While not addressed in the Kimi paper directly, we will discuss where their use of the reward models is limited and where things might progress as more attention is given here.
Below is our trustworthy table of impacts w/ more details on Kimi will impact the AI Ecosystem. Once you’re convinced of the importance, let’s get into the piece.
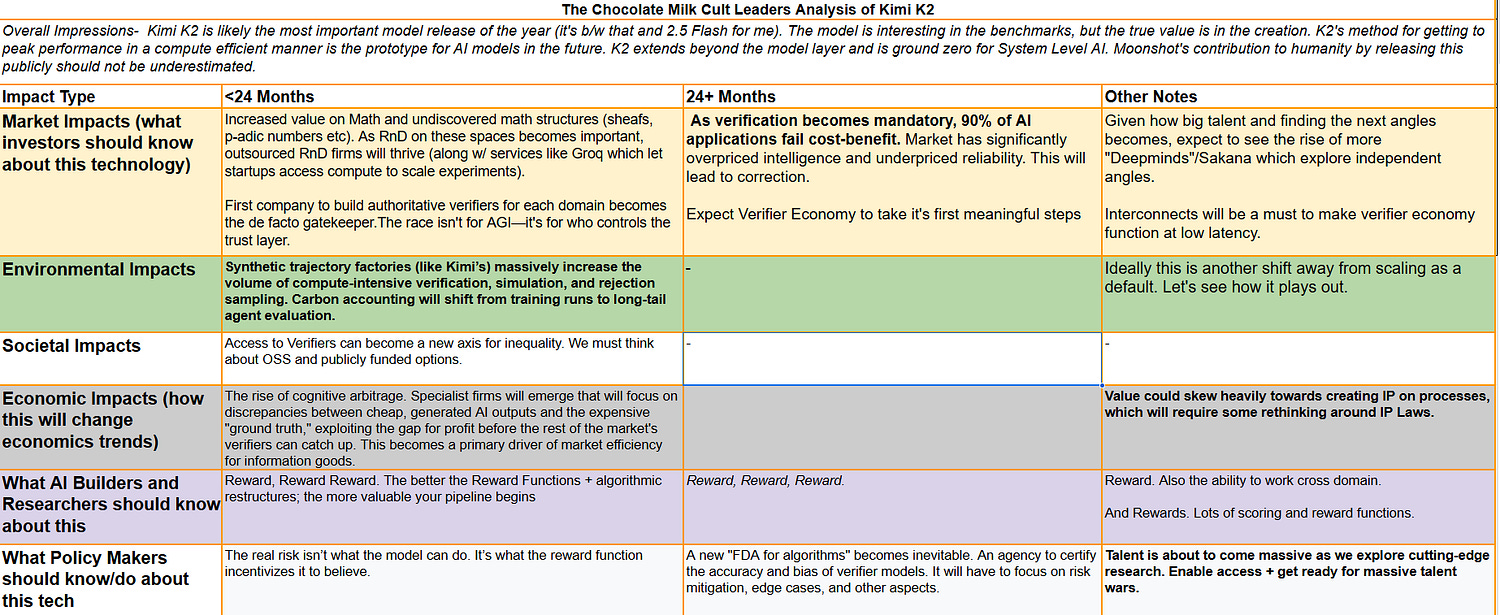
Executive Highlights (TL;DR of the Article)
1. A New Class of Optimizer
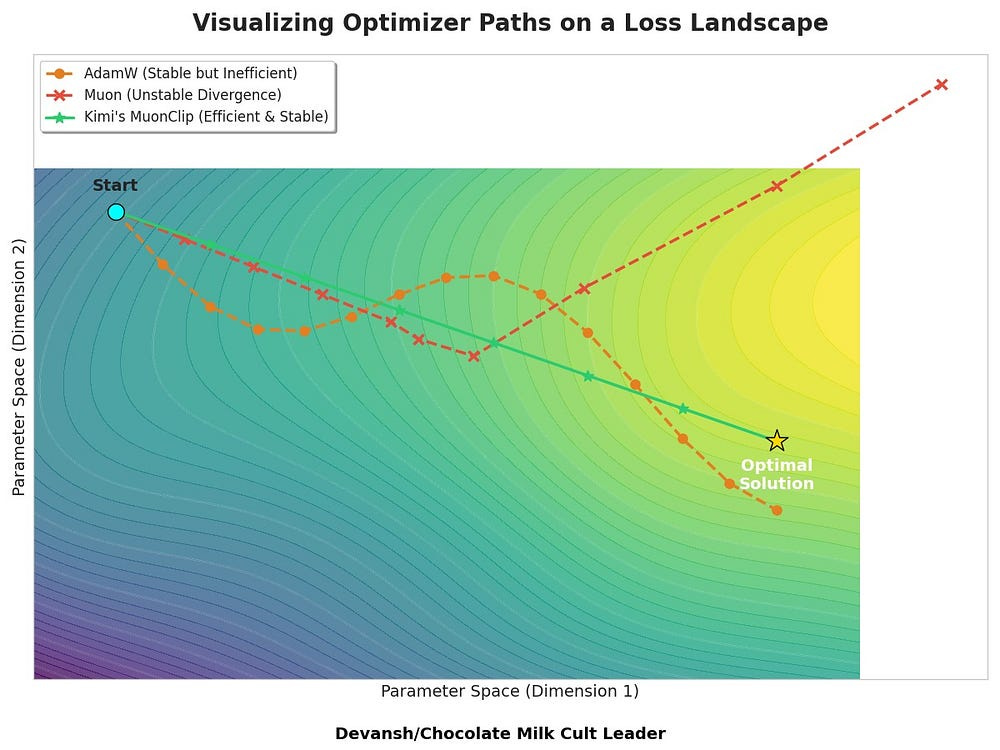
Kimi used Muon, a second-order–inspired optimizer with high-rank updates that adapt to the geometry of the loss surface. But Muon is unstable — it causes weight matrices to grow in ways that break attention. Kimi solved this with MuonClip, a per-head negative feedback mechanism that tracks logit growth and scales down projections before they explode. This allowed them to train on 15.5T tokens with zero loss spikes — unlocking convergence rates far beyond what AdamW can achieve.
2. An Industrial-Scale Agentic Skill Factory
Kimi built a system that generates verifiably correct tool-use trajectories at scale. This includes:
Thousands of real and synthetic tools
Tasks defined by machine-readable rubrics
Tool simulators to generate noisy, realistic interaction logs
LLM-based verifiers to judge whether a task was completed correctly
This is a strong signal for the arrival of the Verifier Economy: a modular structure where agent behavior is generated, filtered, and reinforced via a system of specialized, composable verifiers.
3. A Recursive Alignment Loop That Hardens Over Time
Kimi doesn’t use static reward models. Their critic is trained alongside the model, and only allowed to judge subjective outputs (like helpfulness or tone) after it demonstrates competence on objective tasks (like code correctness or tool success). This prevents reward hacking and aligns the system around verifiable truth.
PTX loss keeps the model from forgetting foundational skills. Budget control and temperature decay prevent verbosity, drift, and instability during RL. These make this protocol stable at scale.
I put a lot of work into writing this newsletter. To do so, I rely on you for support. If a few more people choose to become paid subscribers, the Chocolate Milk Cult can continue to provide high-quality and accessible education and opportunities to anyone who needs it. If you think this mission is worth contributing to, please consider a premium subscription. You can do so for less than the cost of a Netflix Subscription (pay what you want here).
I provide various consulting and advisory services. If you‘d like to explore how we can work together, reach out to me through any of my socials over here or reply to this email.
Part 1: Moonshot AI likes them Curvy
1.1 Why Adam became the Default Optimzer in Deep Learning
The choice of optimizer in deep learning is not trivial. The industry standard, AdamW, has been adopted widely because it provides stable convergence across diverse architectures and minimal risk of catastrophic divergence. Yet stability comes at the cost of efficiency — AdamW is token-hungry, slowly adapting to the geometry of the loss surface due to its reliance on first-order gradient information.

Muon, the optimizer adopted by Kimi, presents a stark alternative. It leverages second-order-like updates through a method called momentum-aligned sign updates (“msign”), achieving dramatically higher token efficiency. However, this efficiency introduces intrinsic instability. High-dimensional uniform updates cause rapid, unchecked growth in model parameters, specifically within attention mechanisms, leading to exploding attention logits and training divergence.

Kimi bet on themselves to overcome the instability posed by relying on Muon. Their method, MuonClip integrates Muon with weight decay, consistent RMS matching, and QK-Clip into a single optimizer. This maximizes performance while giving the model gymnast stability. “Using MuonClip, we successfully pre-trained Kimi K2 on 15.5 trillion tokens without a single loss spike”.
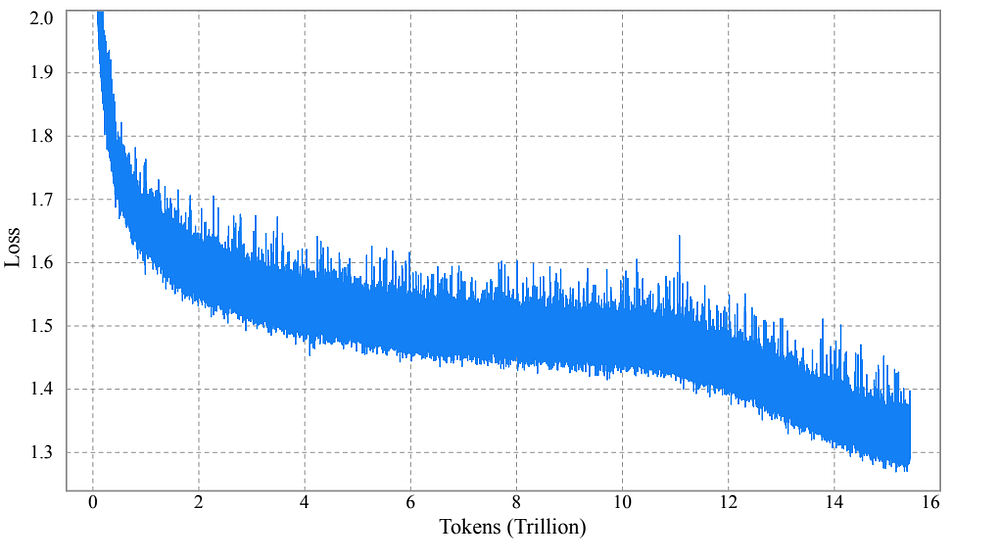
The consequences of this are much bigger than a simple “different optimizer”. We’re going to break down the math before talking about the market gap that this change signals.
To get into this, let’s first understand why Geometry matters.
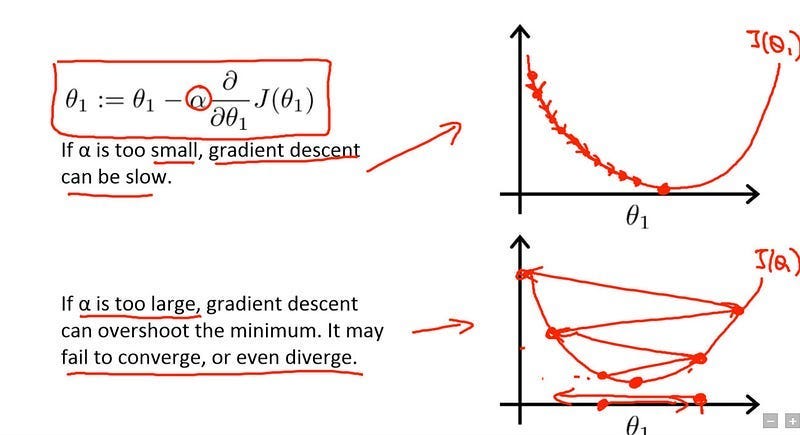
1.2 The Physics of Learning: Why Geometry Changes AI Convergence
AdamW is the Kant of AI optimizers — efficient, stable, and incredibly dull. Let’s break that down.
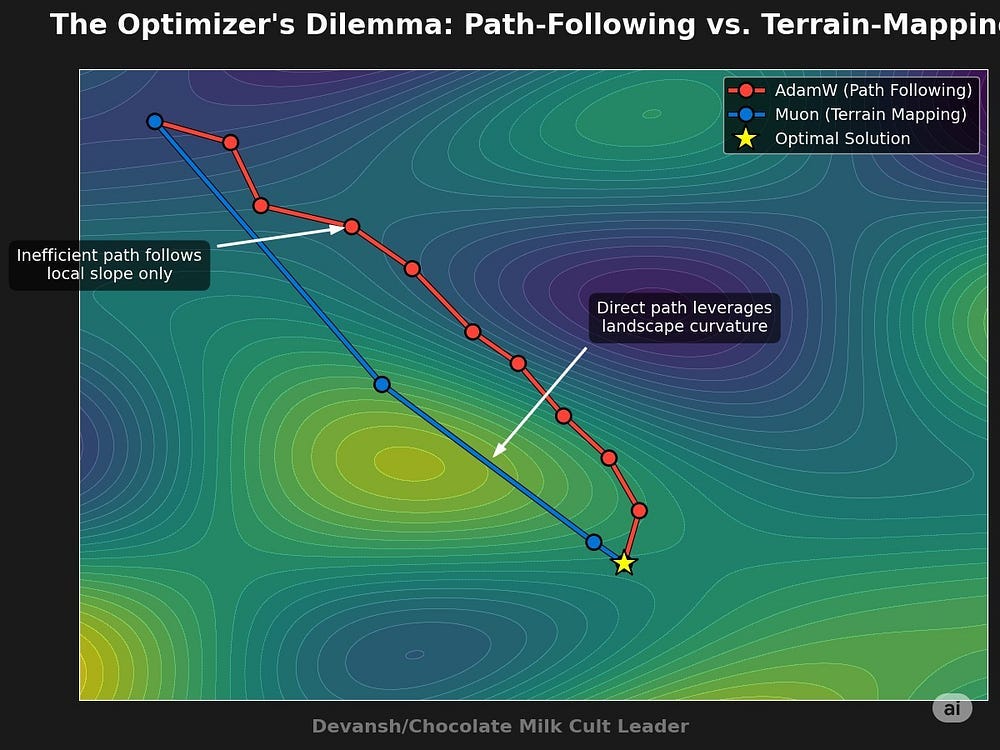
A first-order optimizer like AdamW uses only the local gradient to determine its next step. It knows the direction of steepest descent from its current position, but it is blind to the broader curvature of the loss landscape. This geometric ignorance leads to inefficient, zig-zagging convergence paths, wasting tokens and compute.
A theoretically optimal approach would use second-order information. It would compute the Hessian matrix (H), a collection of all second partial derivatives that perfectly describes the local curvature of the loss surface. Accounting for the Goemetry would allow our AI updates to account for how a specific update will impact training over time, allowing us to mitigate issues like Catastrophic forgetting (LLM updates overwriting old information) and improve multi-objective training.
However, for a model with trillions of parameters, computing, storing, and inverting the Hessian is computationally intractable. This has forced the field to rely on first-order methods. We covered all these points in more depth in our deep dive to natural gradient descent (a true second-order method), which you can find here —

Kimi’s protocol circumvents this. Muon does not compute the Hessian (making it a quasi-second order method). Instead, it employs a momentum-based sign update (msign) that produces a high-rank update matrix. Here lies the critical distinction:
AdamW’s updates are low-rank: They are sparse, pushing the model’s weights along a few dominant directions derived from momentum.
Muon’s updates are high-rank: The msign operation applies a uniform corrective pressure across all parameter dimensions simultaneously.
This high-rank update acts as a computationally cheap approximation of the update step. It allows the optimizer to make progress along many curvature directions at once, dramatically improving token efficiency. It is, in effect, a “poor man’s second-order method.”
I want you to pause here and really understand the distinctions we’re talking about. Because if you can understand the principles, then you won’t struggle with the math (which is what we’re going to be looking at next).
1.3 Deep Dive: The Mathematical Source of Muon’s Instability
To understand where and why Muon fails, let’s understand the algorithm in detail.

Here is your play by play —
Calculate the Gradient: The model first figures out how much each weight needs to change to reduce the error. This is the standard “gradient” calculation, telling us the direction and intensity of the necessary adjustment.
Update Momentum: Muon builds a “momentum” value by combining the current gradient with a smoothed average of previous ones. This helps the optimizer move more consistently and avoid getting stuck in local minima.
Shape the Update for Stability (Matrix Orthogonalization): This is Muon’s special trick. Instead of just using the raw momentum to update the weights, Muon “shapes” it to ensure more equal contributions in different directions. It uses a specific mathematical technique (like a “tuning process” called Newton-Schulz) to ensure that the overall adjustment is balanced and stable.
Weight Update: The weights are updated by subtracting the learning rate multiplied by this orthogonalized momentum matrix. The updates are structured in a way that respects the matrix nature of the weights, rather than treating them as flattened vectors.
This uniform update pressure creates a high-rank update — it pushes the weight matrices outwards across all dimensions, rather than along specific directions. When it works, it looks absolutely gorgeous —
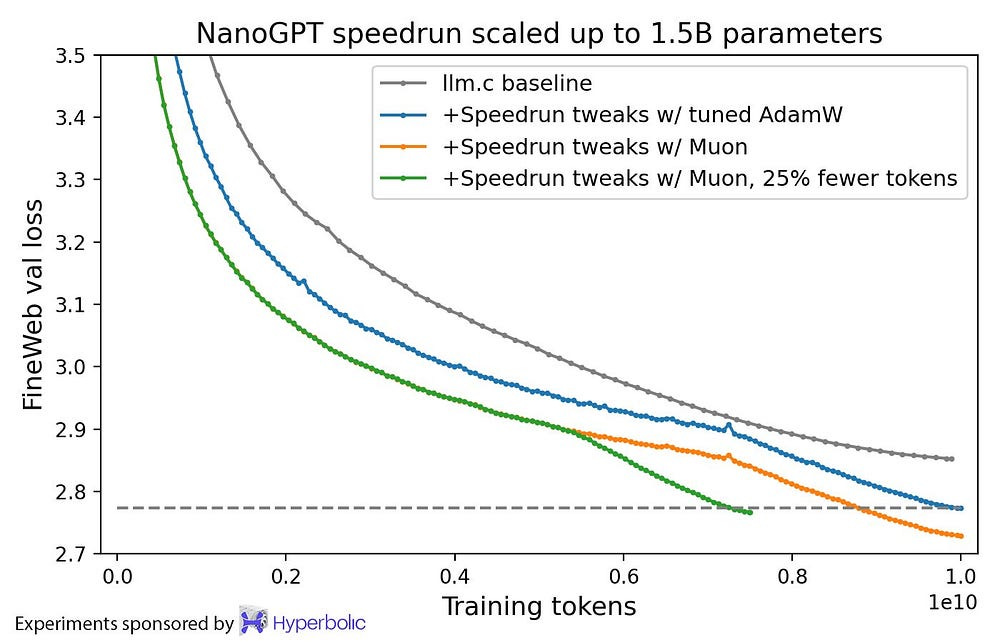
But unfortunately, it tends not to function well in most cases.
Lots of layers. Absolutely perfect when stable. Breaks down often. Remind you of anyone?
And unfortunately, no meds fix this mess. Because the dysfunction is baked into its very core.
Why Muon Falls Apart
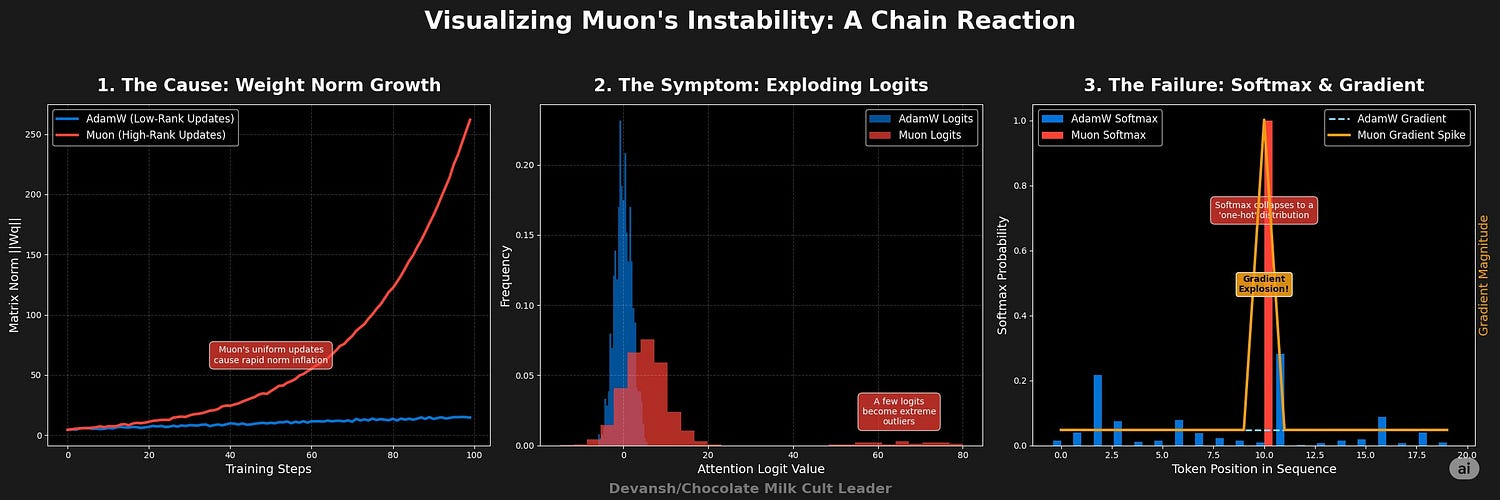
Muon’s instability emerges from how it modifies parameter updates. Unlike AdamW’s targeted low-rank updates (localized parameter adjustments), Muon applies uniform, high-rank pressure across parameters, increasing parameter magnitudes in many directions simultaneously.
This creates a critical vulnerability within the Transformer’s attention mechanism. Attention logits are calculated from the product of weight matrices like Wq and Wk. The paper hypothesizes that Muon’s update style causes the singular values of these matrices to increase additively with each step.
The structure of the attention calculation, which involves the term WqWk⊤, then quadratically compounds this growth. An additive increase in the norms of Wq and Wk leads to a much faster, quadratic increase in the resulting attention logits. This rapid growth triggers logit explosion, causing the softmax function to yield degenerate, one-hot-like probability distributions. This, in turn, leads to vanishing or exploding gradients and numerical instability that halts effective training.
If you’re looking for something more formal, the snippet from the paper might interest you —


Thus, Muon’s superior geometric efficiency inherently risks catastrophic divergence due to how it propagates parameter growth through critical attention computations.
So how did Kimi fix this? As wise people tell you, sometimes no amount of self-love, fashion, and confidence can hide that your existence is a monument to ugliness. Your option is let the knife cut all of it out. This is the approach taken to create MuonClip
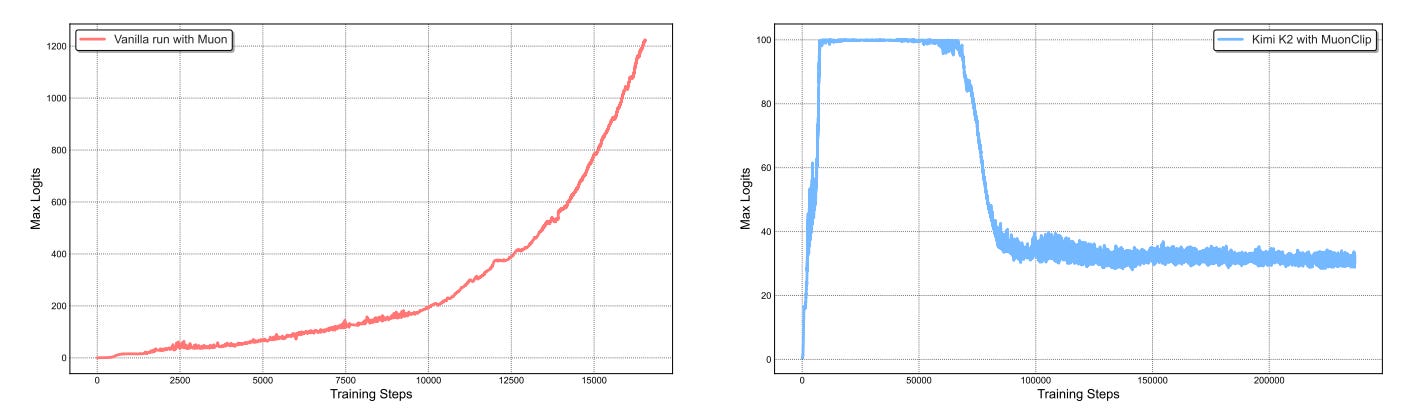
1.4 MuonClip: How Muon got a Makeover
Kimi’s solution, MuonClip, is not a blunt instrument. It is an elegant, minimalist negative feedback controller designed to counteract the specific failure mode of Muon. It targets the cause (the weight matrix norms) while being triggered by an early symptom (the max attention logit). It is a higher-level process that runs alongside the optimizer.

Part 1 is relatively straightforward (we discussed Muon in the last section; this is the same but different symbols). The change is in multiplication by 0.2* sqrt (n,m). The sqrt is a common scaling factor in deep learning, particularly for initialization or normalization, and is used to account for the increasing variance as dimensions grow. The 0.2 is a emperical constant.
The Clip part of Muon Clip comes from the part 2 (line 8 onwards).
It uses a conditional clipping mechanism that targets instabilities often seen in the Transformer’s attention layers after the general Muon update. It does the following-
Monitors attention scores (logits)
If they become dangerously large (crossing a threshold) it scales down the relevant Query and Key weight matrices.
If you pay attention, you will see that MuonClip computes how much each matrix needs to be shrunk based on how far the logit is above the safe range. It then applies the exact amount needed — nothing more.
This prevents overcorrection, preserves training quality, and ensures smooth convergence. It’s a form of negative feedback: if something gets out of bounds, gently push it back in. If it behaves, leave it alone. All while preventing spikes.
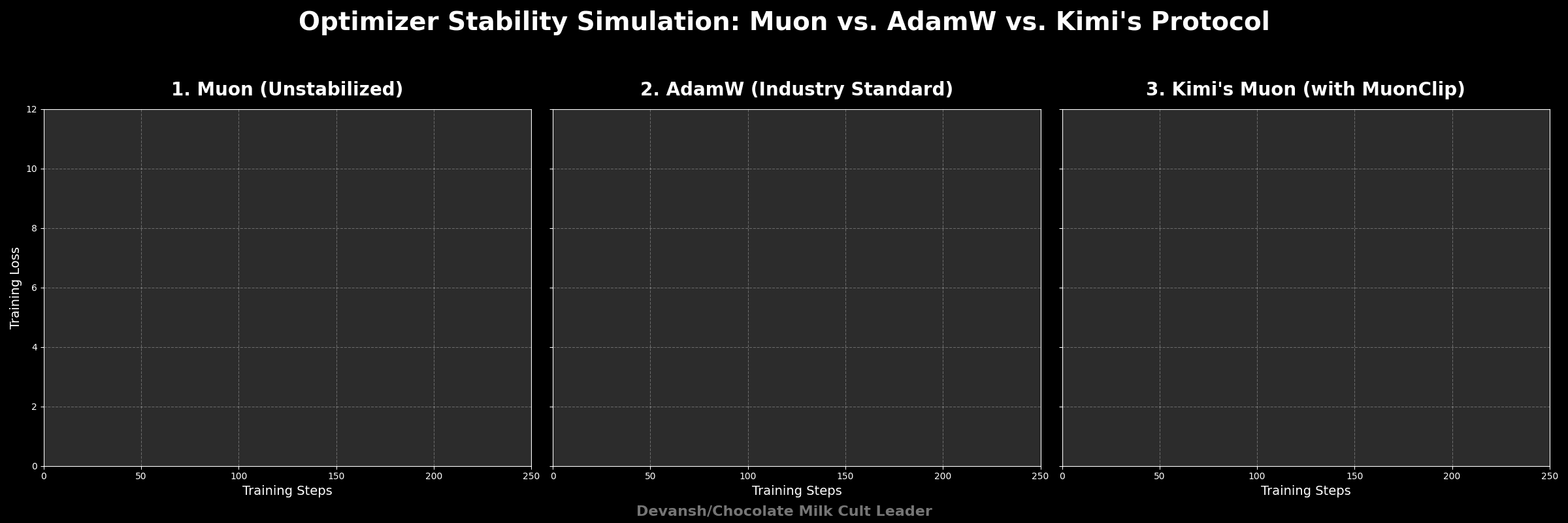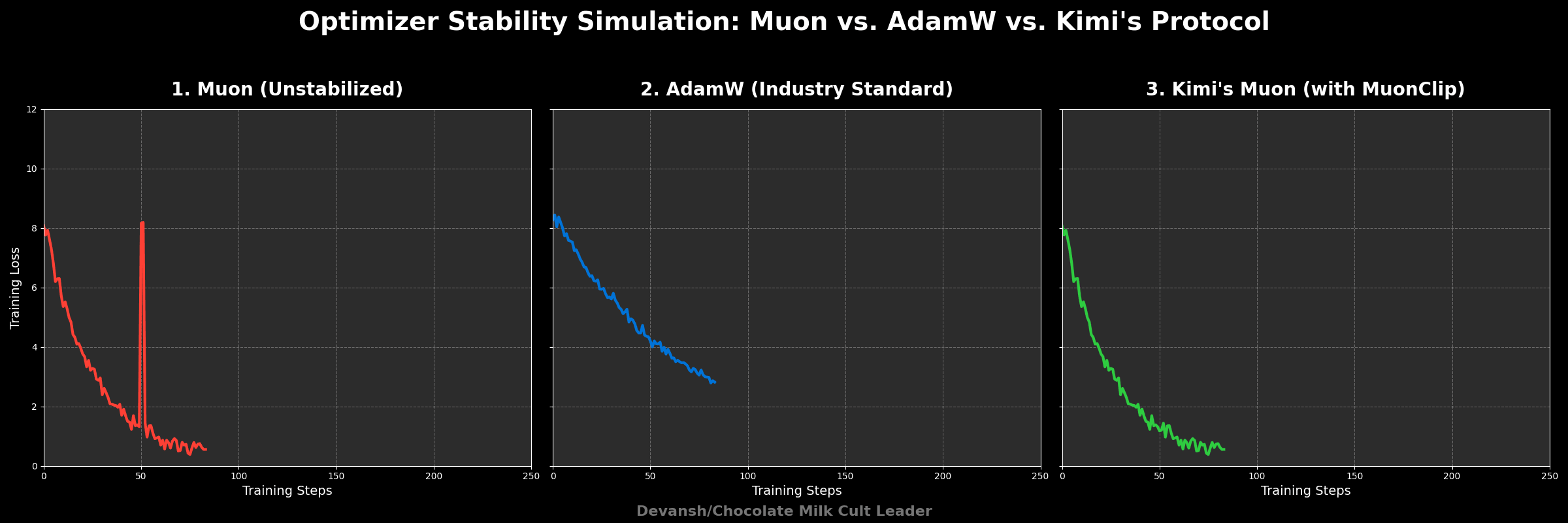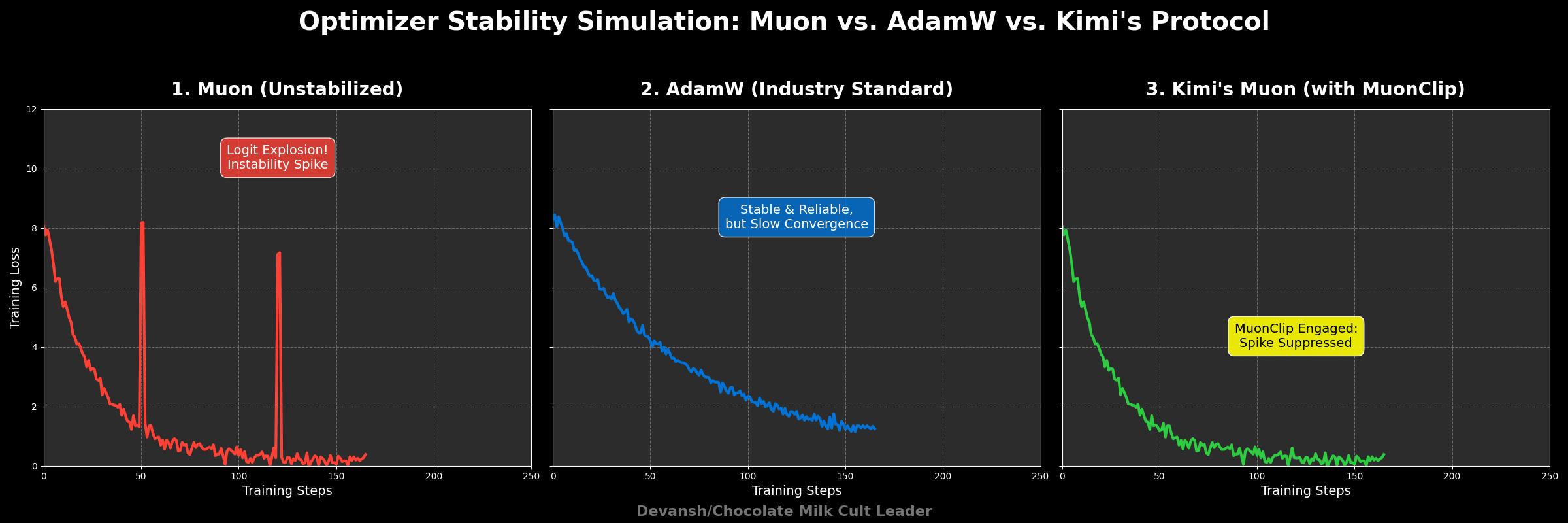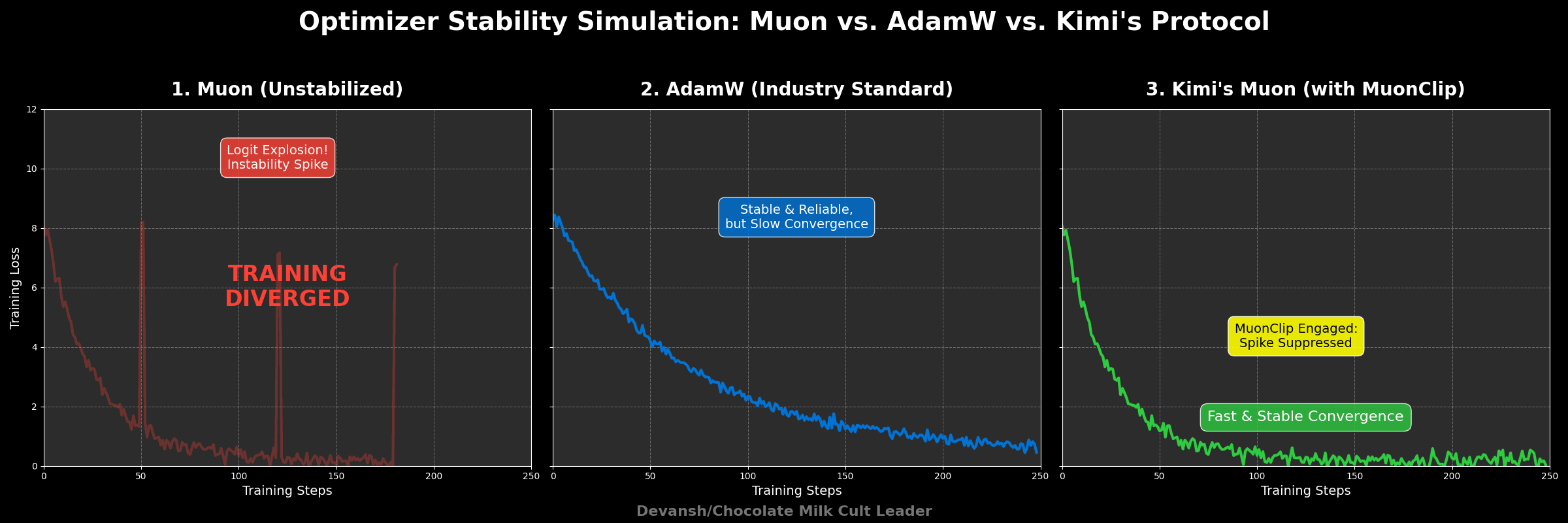
During Kimi K2’s training:
Only about 13% of attention heads ever triggered MuonClip.
After the early phases, all heads stabilized.
The system stopped triggering MuonClip entirely — but the control remained available, just in case.
This is rare. Most control systems interfere with training in heavy-handed ways. MuonClip intervenes only when necessary, and then disappears into the background.
I write these articles for Andrew Ng and Warren Buffett to help guide their investment thesis (this is not literal yet, but will be eventually). In ordinary circumstances, Buffett does not care about the math behind algorithms. So why did we spend all this time talking about it? B/c Muon Clip is a signal of a shift in the things to come.
1.5 Why MuonClip is more than just an Optimizer.
While MuonClip is a new invention, the idea around Geometry and exploiting it for more token-efficient training has been around for a while (see again our exploration of Natural Gradients and how it can solve many issues plaguing large-scale LLMs today).
But it’s still been extremely fringe. There are several reasons for this.
Hardware Mismatch: GPUs are optimized for simple, dense matrix operations. Geometry-aware methods require irregular operations that don’t map cleanly onto GPU cores or standard libraries. This is an idea we broke down in depth when exploring why the US Government has already started looking beyond GPUs here. Ideas like Natural Gradient (which account for curvature more explicitly) can be extremely expensive to handle on optimized systems.
Memory and Communication Overhead: Geometry-aware updates require tracking more state (like per-head logits or weight norms), putting more pressure on memory bandwidth and cross-node communication. Kimi’s team solved this with custom kernels, mixed-precision, and overlapping communication with computation.
Algorithmic and Talent Complexity: Second-order methods require deep understanding. Debugging a loss spike from exploding logits isn’t trivial. Designing a fix like MuonClip is even harder. This creates a talent moat that’s invisible on paper but real in practice.
Scaling was Political- As we covered in depth, scaling models provided a safe predictable return compared to more disruptive and unreliable strains of research. This pushed the industry away from actively looking into these strains.
1 and 2 create powerful investment opportunities (new kinds of chips and mixed rack interconnects to coordinate them), one that our lab is pricing very aggressively. GPUs were a convenient option that we could use when AI wasn’t the focus, but as AI becomes more complex, we can’t rely solely on them (additional reading for those interested in the technicals in more details: see Part 1 (here) and Part 2 (here) of our assessment of the new AI infra stack. 3 I have no comments on, and is becoming less and less true by the day.

The implications of this should not be ignored. We will do deep dives on some of these in the future (including specific AI Chip Designs etc), but for now let us move on the other pillar.
To maximize efficiency and to fully leverage the engineering trends of Sparsity, MoE, and Agents, we need an LLM w/ a diverse dataset, w/ underlying robustness to multi-turn conversations (a weakness of current LLMs), and natively trained on Tool Use. Which is what we will break down next.
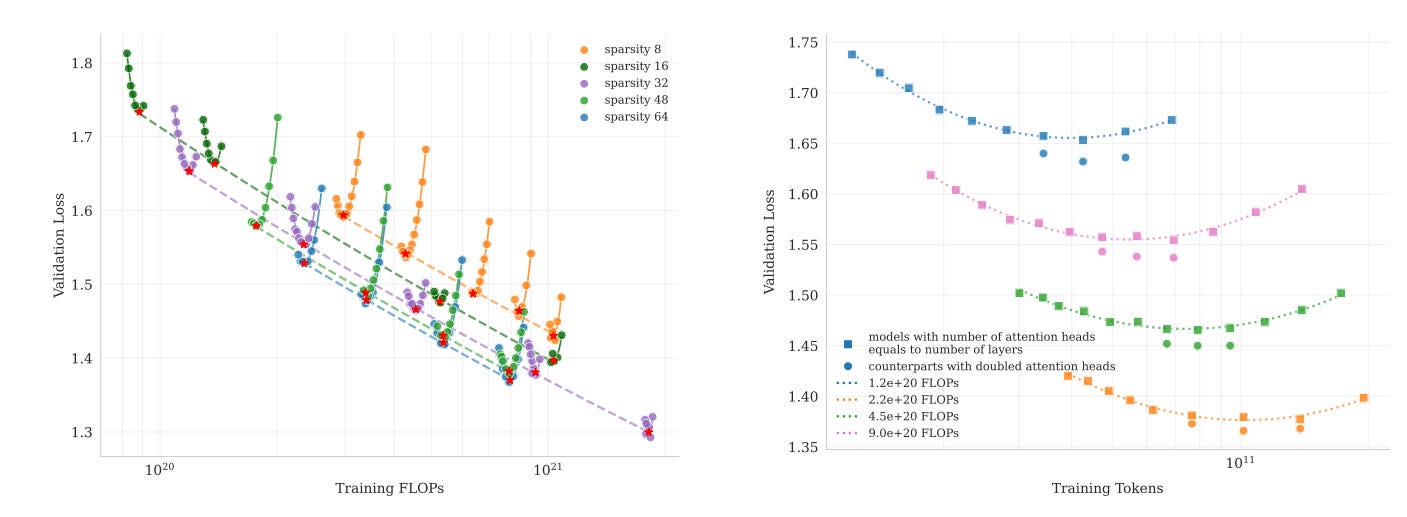
Part 2: The Industrial-Scale Skill Factory
2.1 The Agentic Scaling Problem
Here’s the dilemma: training an LLM to sound smart is easy. Training it to do things — use tools, follow plans, recover from errors, handle ambiguity…is a….. work in progress.
Because skill, unlike knowledge, is procedural. It requires:
A defined task
A working tool
An outcome you can measure
And the ability to retry until you get it right
And none of this scales with traditional data pipelines. You can’t scrape Reddit for multi-step trajectories. You can’t outsource 100,000 tool-use demos to contractors and hope for consistency. This gets murkier with enterprise tool use scenarios, where vendor relationships, company politics, and prior work add arbitrary constraints on what tools can be used, how to use them, etc.
The industry’s best bet until now was imitation — pretrain on Stack Overflow, fine-tune on GPT-style Q&A, and hope the model generalizes. But agentic behavior doesn’t emerge from static text. It emerges from interaction, feedback, and correction — at scale.
That’s the real challenge.
And it’s where Kimi’s second breakthrough comes in.
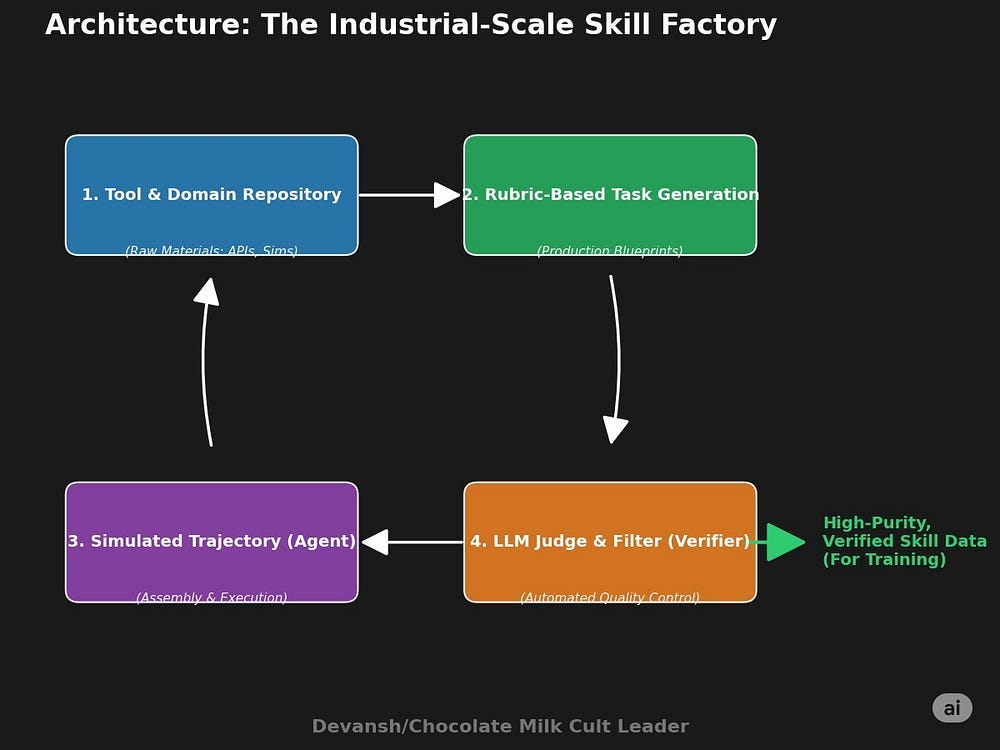
2.2 Manufacturing Skill with Rubric-Driven Automation
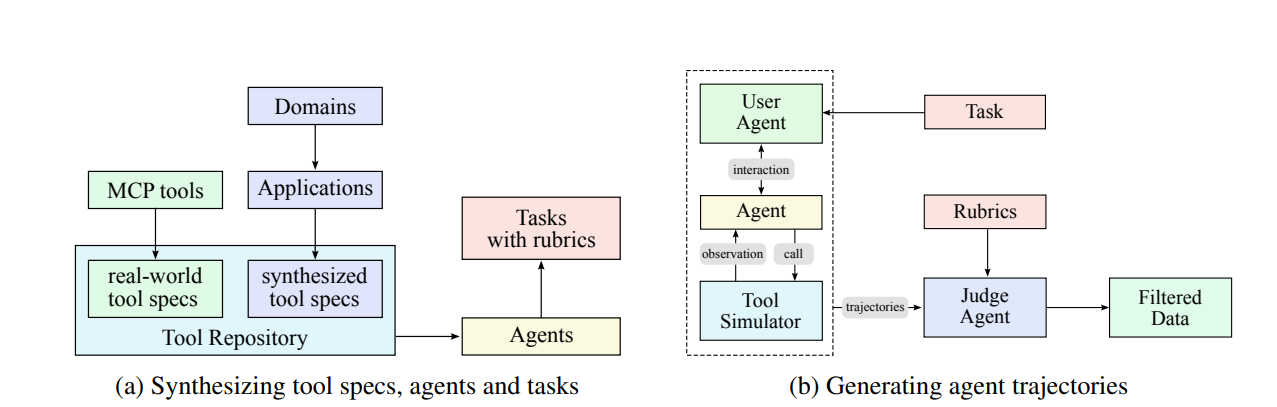
Kimi built a system. Not a dataset, not a few demos, but a machine that produces verifiably correct experience at an industrial scale. Let’s walk through it piece by piece.
1. A Tool Repository That Doesn’t Suck
First, they compiled thousands of tools across domains: APIs, command-line utilities, real services, synthetic sandbox environments. Some came from GitHub’s Model Context Protocol (MCP), others were generated in-house. These tools are:
Diverse in domain (finance, cloud, scheduling, shell, etc.) Diversity is key b/c it allows the model to sample from a wider search space, naturally bringing generalization and robustness. The oft-over sensationalized model collapse (LLMs getting worse when trained on LLM generated data) is not so much an inherent limitation due to Synthetic Data as it is a consequence of a very sterile dataset (more here).

Defined with clear specs and I/O behavior
Callable by the model through structured function calls
The repo includes both real tools (for realism) and synthetic ones (for breadth), and they’re organized with t-SNE embeddings to ensure coverage across functional space.
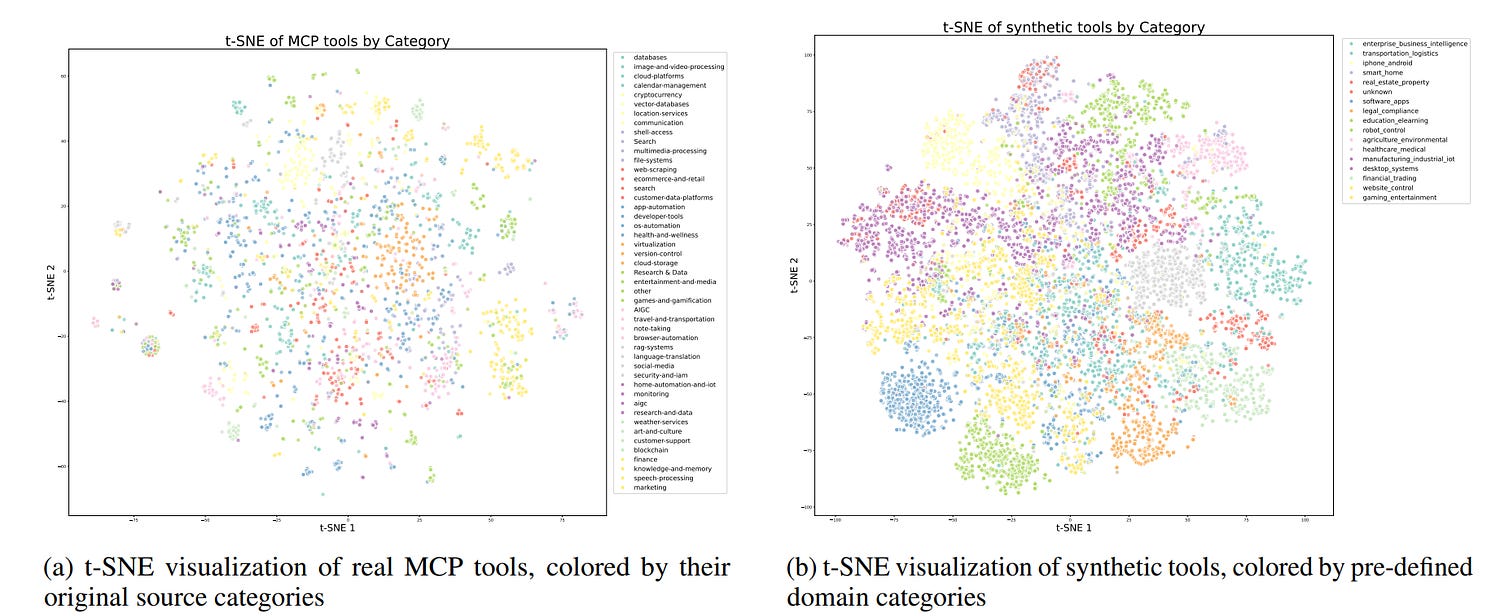
This gives the model enough Lego Blocks that it can learn to put together to create it’s mastapieces. Next, it starts building.
2. Task and Agent Synthesis Using Rubrics
“We generate thousands of distinct agents by synthesizing various system prompts and equipping them with different combinations of tools from our repository. This creates a diverse population of agents with varied capabilities, areas of expertise, and behavioral patterns, ensuring a broad coverage of potential use cases. Rubric-Based Task Generation. For each agent configuration, we generate tasks that range from simple to complex operations. Each task is paired with an explicit rubric that specifies success criteria, expected tool-use patterns, and evaluation checkpoints. This rubric-based approach ensures a consistent and objective evaluation of agent performance.” — From the paper
For each tool or toolset, Kimi generates tasks — automatically, using prompt templates — and couples them with rubrics that define what success looks like.
A task isn’t just “call this API.” It’s:
Use this tool to complete an outcome.
Follow specific constraints (e.g., don’t make more than 3 calls, or match user intent).
Be evaluated against a checklist.
The rubrics are machine-readable. This is critical to make quality control possible without human supervision.
Once this is set up, Kimi spawns synthetic “agents” — each with different system prompts, tool sets, and behavioral priors. These aren’t random personas. They’re designed to explore how tool-use behavior varies with setup — creating thousands of variations that generalize across domains.
3. Trajectory Generation in Simulated Environments

For every task, the model interacts with a tool simulator — a world model that mimics how the tool would behave:
If the agent makes a correct call, it returns success.
If the agent calls the wrong tool, uses the wrong parameters, or misreads the instruction, it returns partial failure, or state changes that create long-term problems.
This enables:
Multi-turn interaction
Retry and recovery patterns
Realistic, noisy environments that stress-test tool use
And it produces what we care about: interaction trajectories — logs of what the model tried, what the tool responded with, and what changed as a result.
4. Quality Control via Verifier Stack
Once a trajectory is complete, it passes through a LLM-based verifier — a judging model that reads the task + rubric + trajectory and decides: did this solve the problem?
This verifier checks:
Goal completion
Constraint adherence
Tool call correctness
Interaction quality
Only passing samples are kept.
This is rejection sampling at scale — filtered not by humans, but by rule-driven critics. Bad outputs are discarded. High-quality, verifiably correct interaction traces go into the training pipeline.
Interesting engineering? Absolutely. But is there anything beyond that? Think about what Moonshot just did with this ecosystem —
Generator proposes behavior.
Verifier judges behavior.
Only passing behavior survives.
That’s not a training pipeline. It’s a free market (the irony of a CCP based lab creating this should not be lost on you).
If you read our market report for most important updates in June, your bells are probably ringing. Our report called out the rising importance of reward models and “critics” to steer complex agentic systems. While at the nascent stage right now, these critic models will eventually spawn their own ecosystem to better handle the balance b/w latency, complexity, specific control vectors etc.
This verifier economy will become a crucial part of the AI Stack, especially as AI continues it’s consolidation towards Vertical Plays and Regulation drives an increased focus on Security and Control. The Verifier Economy will change some fundamental assumptions about AI —
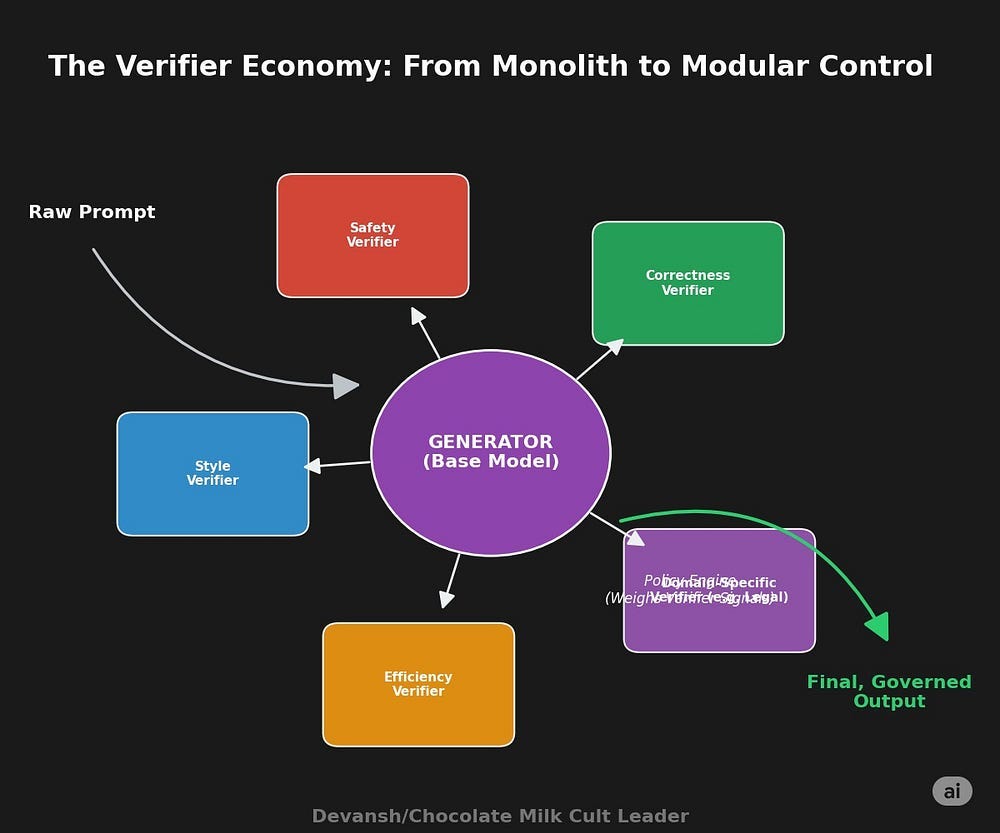
How the Verifier Economy changes the unit of intelligence.
In the LLM era, the unit of progress was the model. In the agent era, it’s the system:
The generator is the actor.
The verifier is the critic.
The task/rubric engine is the environment.
And the simulator is the “world” w/ tools/MCPs being a way to navigate them.
Each of these can be versioned, audited, and improved independently.
Another signal that screams the same trend we’ve been calling for a bit: we’re no longer in monolithic model territory. We’re in modular intelligence. And the leverage has shifted from model size to verifier quality.
This changes the economic layer.
If intelligence is filtered through verifiers, then whoever owns the verifier:
Controls what behavior is considered valid.
Controls what behavior is reinforced.
Controls what behavior becomes dominant across models.
Makes Intelligence composable. Just as APIs allowed developers to assemble complex applications from modular services, verifiers will allow them to assemble complex cognitive agents from modular judgment layers (which is one of the reasons I was interested here to begin with).
Verifiers become programmable incentives. Eventually becoming regulation-mandated standards.
If you wait for the Verifier Economy to show up in sitcoms, you’ll be late to catch the boat. The early players will be able to entrench themselves into the ecosystem, curry favor, and get a huge head start. And while LLMs commoditize aggressively, the Verifier Layer (atleast for more sensitive enterprises) is likely to stay relatively rigid.
Unlike the former signal/pillar, this is not going to be as CapEx intensive to get started in, making it a faster early investment w/ earlier ROIs. It’s also in-line with Model Architecture changes that we’re seeing in LLMs.
The final pillar is the glue that holds the system at scale.
Part 3: How Kimi handles Alignment and what comes next
3.1 Grounding Intelligence in Objective Reality
An agent that can act is powerful. An agent that can act without breaking is infrastructure.
The industry’s approach to alignment hasn’t produced the latter. It’s built on soft sand — a loose blend of annotator preference, reward modeling, and aesthetic coherence. It trains models to be plausible, not correct, persuasive without precision. Reward hacking becomes inevitable, drift unavoidable, and any system built on this foundation becomes unstable at scale.
Moonshot decided to go all in on the Verifiable Reward Trend w/ their Verifiable Rewards Gym (RLVR) — a training infrastructure that removes ambiguity from reward signals by designing tasks that produce binary, ground-truth feedback.
Does the tool call succeed?
Does the code pass all unit tests?
Does the math solution check out?
Yes or no. No partial credit. No human judgment. And because the verification is automated, it’s scalable. Kimi can generate a perpetual stream of high-signal, zero-noise feedback, across domains.
3.2 The Self-Hardening Critic: Recursive Alignment That Doesn’t Drift
RLVR handles what can be grounded in truth. But most of intelligence — style, helpfulness, nuance — requires subjective judgment.
This is where most alignment pipelines fail. They use a static reward model trained on noisy human preferences and hope it holds up. It never does.
Moonshot builds something fundamentally stronger: a critic — and more importantly, a process that keeps it honest.It has two components-
The actor: Kimi K2, generating responses.
The critic: a second model that scores the actor’s outputs against subjective rubrics — clarity, style, helpfulness, etc.
The Catch? The critic is not trusted until it proves itself on truth.
Before it is allowed to judge subjective qualities, it must pass objective tests from RLVR:
Can it tell which tool-use trajectory completed the task?
Can it distinguish between a functioning and broken code snippet?
If it can’t, its subjective outputs are ignored or down-weighted. This creates a closed loop:
The actor learns from the critic.
The critic is trained on verifiable outcomes.
The entire alignment system corrects itself as it scales.
Every RL iteration reinforces the critic. Every critic update stabilizes the actor.
To make this work, Moonshot leverages several engineering refinements.
3.3 Practical Refinements: The Infrastructure That Holds It Together
PTX Loss — Preventing Capability Collapse During RL
PTX (Pre-Training Cross-Entropy) loss is an auxiliary objective used during reinforcement learning to prevent the model from forgetting general skills learned during pretraining or supervised fine-tuning.
This (the forgetting) happens b/c RL optimization focuses only on what the reward model scores. Any skill not explicitly rewarded will degrade over time — including basic reasoning, factual answering, or response formatting. This is called catastrophic forgetting, and it’s common in RLHF pipelines.
PTX Loss is deceptively simple. During each RL step, the model is trained on two batches:
RL batch: Samples generated by the model, scored by a critic or verifier.
PTX batch: Curated supervised examples with known-good outputs.
PTX computes standard cross-entropy loss between the model’s predictions and the correct targets from the PTX batch.
The total loss is: RL Loss + b × PTX Loss
Where:
RL Loss pushes the model toward rewarded behavior.
PTX Loss keeps it anchored in foundational capabilities.
The b coefficient balances the two. It’s tuned to be strong enough to preserve competence, but not so strong it blocks RL progress.
Training this on High Quality Data allows the Setup to stay solid and not forget it’s roots.
Budget Control — Teaching Bounded Intelligence
RL-trained models often get verbose. Why? Because longer outputs mean more surface area to optimize reward. More detail. More style points.
But that verbosity is:
Expensive to serve
Fragile to evaluate
Often unnecessary
To counter this, Kimi enforces per-task token budgets. If a response is too long, it’s penalized. If it’s concise and correct, it’s rewarded. This isn’t revolutionary, and a few other people have done similar things, but it’s still worth noting.
Temperature Decay — From Chaos to Precision
At the start of training, you want diversity. High temperature, lots of exploration, weird edge cases, risky paths. But as the system converges, that same randomness becomes noise. Instability. Jitter. Drift.
Kimi uses a temperature decay schedule — high at the beginning, lower over time. It gradually shifts the model from exploration to exploitation, ensuring final outputs are not just diverse, but stable.
Same principle as Learning Rates.
The Look Ahead for Rewards
While I was complimentary on the Verifiable Rewards as a base, it’s a short-term solution. Apps like Cursor fail in enterprise coding settings precisely because they overindex on correctness but are not trained to account for fuzze aspects like accounting for pre-existing abstractions and control flows. This is why it’s likely to build it’s own authentication service instead of using a prebuilt one, ignoring security processes by doing so.
Even in hard fields like Math and Coding, there are better and worse ways to do things, which is a nuance that’s completely overlooked in the current system. Binary Rewards are an intelligent pragmatic engineering choice, but teams should be looking to move beyond them when possible. There is too much important data signal contained in data otherwise.
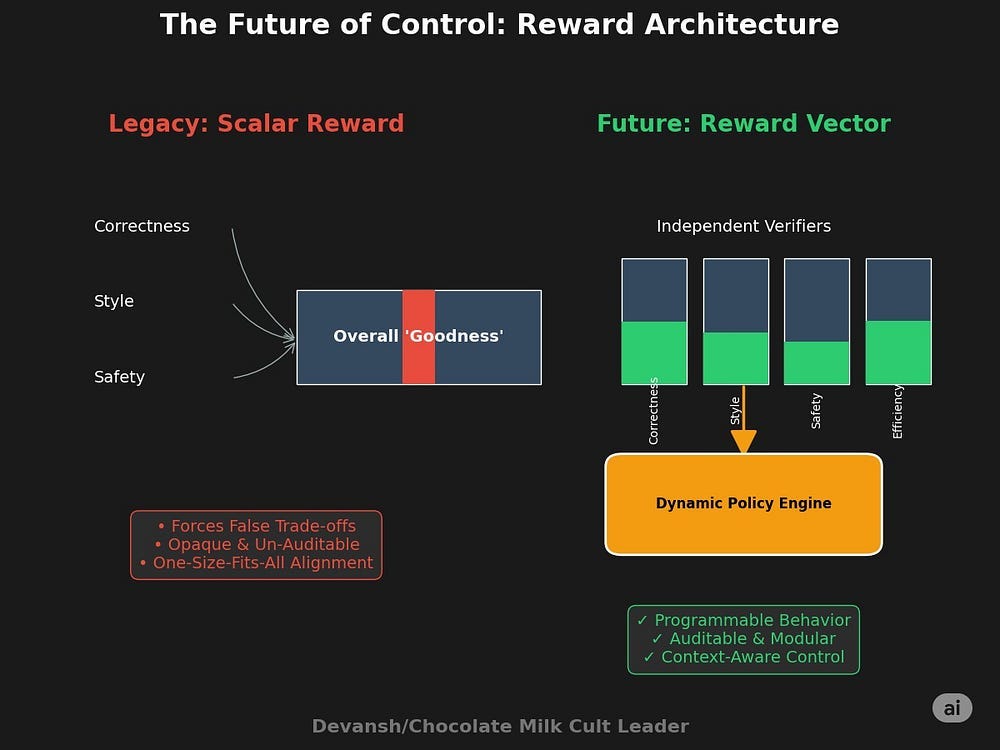
This and orthogonal rewards (where different rewards check for different things as opposed to the same critic scoring both flow and rigor and other attributes) will all be a must for training complex systems at scale. And will lay the ground for the Verifier Economy in doing so.
Conclusion: What Kimi K2 means for the Future
Kimi K2 should not be seen as another AI Model Release. It has something much deeper. It’s a reflection which we can use to understand the landscape as it is currently. Studying it w/ an informed perspective gives us a glimpse of how AI got here and what we should do next.
Kimi reflects the tension b/w research into new directions vs optimizing what we know (the ol’ exploration vs exploitation). It tries to figure out data in a world increasingly hostile to data scraping and where we’ve already taken large parts of the internet. It attempts to rethink AGI from model to system. All while being a part of the larger geo-political battle for AI Supremacy.
And perhaps most important, Kimi makes us rethink our priorities. Maybe the question is no longer if we can build powerful AI, but how we design the intelligence that builds it.
Thank you for being here, and I hope you have a wonderful day.
Dev <3
If you liked this article and wish to share it, please refer to the following guidelines.
That is it for this piece. I appreciate your time. As always, if you’re interested in working with me or checking out my other work, my links will be at the end of this email/post. And if you found value in this write-up, I would appreciate you sharing it with more people. It is word-of-mouth referrals like yours that help me grow. The best way to share testimonials is to share articles and tag me in your post so I can see/share it.
Reach out to me
Use the links below to check out my other content, learn more about tutoring, reach out to me about projects, or just to say hi.
Small Snippets about Tech, AI and Machine Learning over here
AI Newsletter- https://artificialintelligencemadesimple.substack.com/
My grandma’s favorite Tech Newsletter- https://codinginterviewsmadesimple.substack.com/
My (imaginary) sister’s favorite MLOps Podcast-
Check out my other articles on Medium. : https://rb.gy/zn1aiu
My YouTube: https://rb.gy/88iwdd
Reach out to me on LinkedIn. Let’s connect: https://rb.gy/m5ok2y
My Instagram: https://rb.gy/gmvuy9
My Twitter: https://twitter.com/Machine01776819
How do you feel about claims that Kimi K2 supports lossless long context? I've seen these in other articles about the model, but haven't seen anything official from Moonshot about it (just references to Chinese language interviews with Yang Zhilin where he doesn't seem to actually claim this).
I don't have the technical chops to fully investigate the claim, but Kimi K2 does seem to have some innovations that may help reduce cognitive dilution.
Thank you! I am new to Substack. Love the article!👏