


Llama 4 Deep Dive: Why Meta’s Latest Models Change Everything [Breakdowns]
Exploring Multimodality, Mixture-of-Experts, and the Secret Sauce Behind Llama 4’s Record-Breaking Performance

Hey, it’s Devansh 👋👋
In my series Breakdowns, I go through complicated literature on Machine Learning to extract the most valuable insights. Expect concise, jargon-free, but still useful analysis aimed at helping you understand the intricacies of Cutting-Edge AI Research and the applications of Deep Learning at the highest level.
I put a lot of effort into creating work that is informative, useful, and independent from undue influence. If you’d like to support my writing, please consider becoming a paid subscriber to this newsletter. Doing so helps me put more effort into writing/research, reach more people, and supports my crippling chocolate milk addiction. Help me democratize the most important ideas in AI Research and Engineering to over 100K readers weekly. Many companies have a learning budget that you can expense this newsletter to. You can use the following for an email template to request reimbursement for your subscription.
PS- We follow a “pay what you can” model, which allows you to support within your means, and support my mission of providing high-quality technical education to everyone for less than the price of a cup of coffee. Check out this post for more details and to find a plan that works for you.
I’ll skip the customary intros- Meta just dropped Llama 4- with 3 very powerful model variants-
Scout -an efficient multimodal LLM with a 10 Million Token Context Window that can run on one GPU. Outperforms the cheap models in it’s weightclass.

Maverick- a more powerful model (still reasonably efficient) that stomps out the “intelligent models”- GPT 4.5, 4o, Claude 3.7, DeepSeek R1, Gemini 2.0 Flash etc. There were no comparisons against 2.5 Pro, which is understandable given how recent 2.5 Pro is.
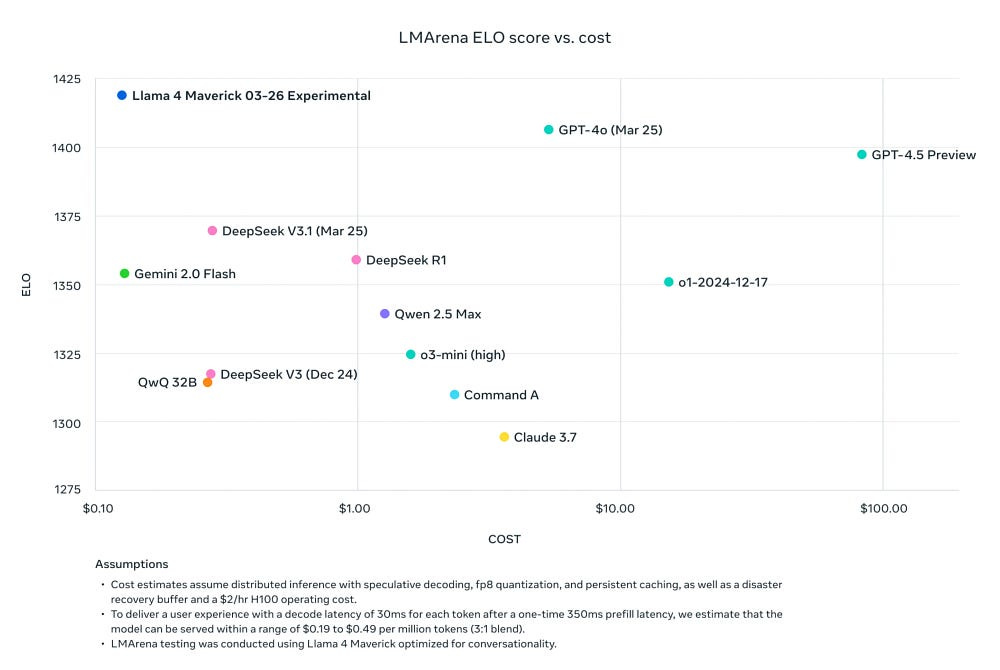
3. Behemoth- A 2 Trillion model that is being called best in class, but is not released yet b/c it’s still mid-training. This is used as the teacher model for the lighter ones. We’re able to access the preview model for a peek at the future capabilities.
There goes my Saturday plan of playing 5–7 hours of age of empires and watching some Psycho Pass (such an elite show, ong). Thank you, Zucky Chan. B/w this release 2.5 Pro, all the Chinese models, rumors of two extremely powerful models -“Nightwhisper” and Alpha Qasar, very cool breakthroughts in reasoning, and more I can’t imagine AI researchers having too much of a break over the next few months. This is how I view the entire industry right now-

In this article, I’m going to go over the release statement and the code base to analyze the most important insights to understand how they do it so that you don’t have to. The goal isn’t so much to summarize the release as it is to read b/w the lines and try to understand what this teaches us about the trends in building the next generation of systems.
Llama 4 Maverick, a 17 billion active parameter model with 128 experts, is the best multimodal model in its class, beating GPT-4o and Gemini 2.0 Flash across a broad range of widely reported benchmarks, while achieving comparable results to the new DeepSeek v3 on reasoning and coding — at less than half the active parameters. Llama 4 Maverick offers a best-in-class performance to cost ratio with an experimental chat version scoring ELO of 1417 on LMArena.
Given the extreme efficiency of both released variants on Llama 4, I feel it is only right to crack open our recent meme from this breakdown-


If you want to dig into what makes Llama 4 special, keep reading.
Executive Highlights (TL;DR of the article)
Llama 4 has 4 notable developments-
Mixture-of-Experts (MoE) Adoption:
MoEs are networks composed of “expert” sub-networks and a “gating” network that dynamically routes inputs to the appropriate experts. This allows for conditional computation, making large networks more efficient-
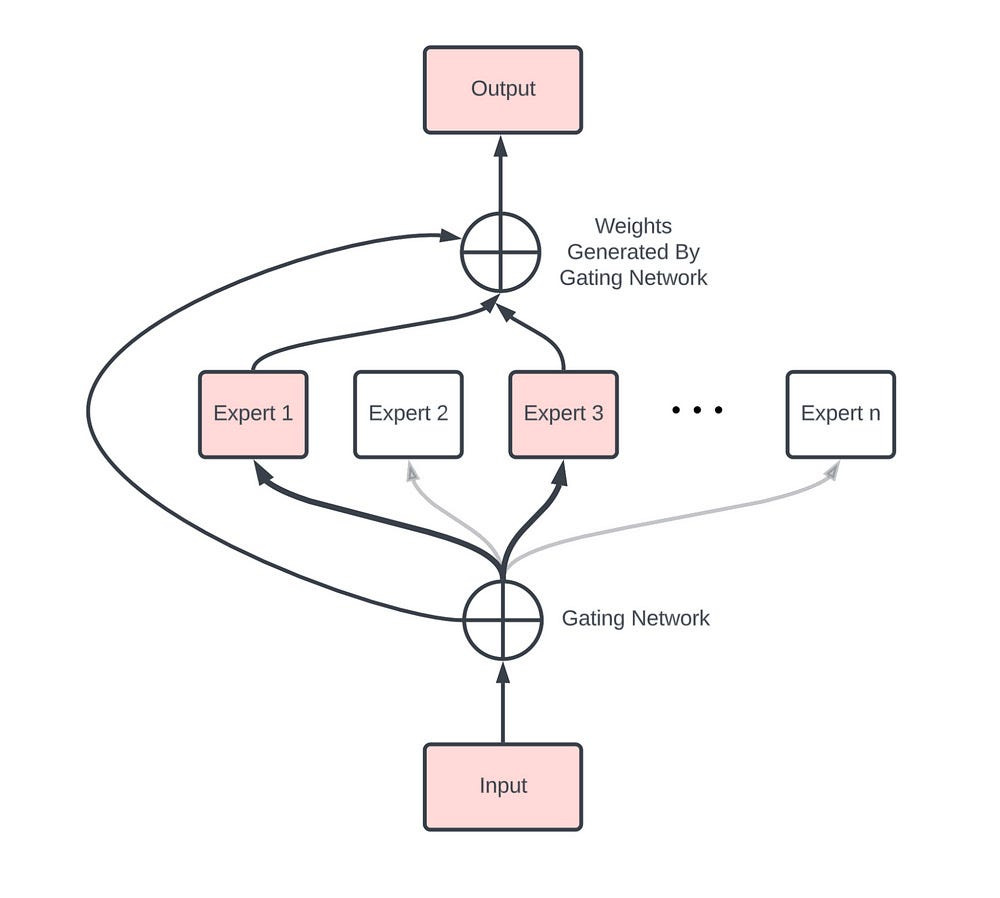
Their power and efficiency are why everyone expects cutting-edge LLMs like GPT 4 and Gemini, and their future versions to heavily leverage this technology.
Meta replaces some dense FFN layers with multiple smaller “expert” FFNs (using high-performance SwiGLU activation) and a router. Maverick, in particular, uses a unique hybrid “shared + routed” expert approach. We’ll break this down in the main section.
This is one of the biggest changes confirming MoE supremacy for modern Deep Learning (and making our coverage of DeepEP in the AI Market Research of March that much more important). AFAIK, Llama was the only major LLM not using MoE in its setup (which was surprising). If I were an AI-Infrastructure investor, I would immediately start surveying the markets to spot startups that make MoE easier, since this is a massive signal that this seems the only way forward.
Native Multimodality (Vision):
NM provides deeper integration than “bolted-on” vision leads to better cross-modal understanding and grounding.

Specifically, Meta uses Early Fusion. An enhanced MetaCLIP-based vision encoder (specifically trained with Llama) generates visual tokens that are processed jointly with text tokens within the same Transformer backbone, enabling direct cross-modal attention. Relies on joint pre-training on massive text/image/video datasets.
Ultra-Long Context (iRoPE in Scout):
Scout uses iRoPE, interleaving standard RoPE attention layers with NoPE (No Positional Encoding) layers. Complemented by “inference time temperature scaling” (dynamic attention sharpening based on position) and training on long sequences (256K).
The long context is cool, but Needle in a Haystack (the way we measure performance in Long Context tasks) isn’t a great benchmark for professional use. Most long context usage isn’t so much picking specific bits of information but rather the ability to merge multiple snippets of information and reason/draw links between them w/o losing the plot. This is a very different challenge and still needs a lot of work to be solved.
A good illustration of this is Gemini’s video capabilities. Here is a relatively chill sparring session that’s about 2 Minutes long (well under Gemini context window limits). It’s pretty slow-paced, it’s only striking (which is easier to decipher than grappling), and the techniques aren’t out of the norm. This should make analysis very easy- given Gemini’s amazing performance in Long Context video search. However, Gemini consistently fails to analyze this, creating weird hallucinations, missing moments, and generally tripping out on the video. For the analysis actual task- the model is at best functionally useless and at worse harmful.
It’s not that Gemini can’t understand what it’s looking at. When explicitly prompted about moments (or corrected about incorrect statements), it can course correct based on feedback. However, it fails to create a cohesive analysis that requires combining multiple moments b/c it can’t effectively figure out how to read the context and chain them together. This indicates an important distinction between needle in a haystack vs long context analysis. Increasing the context window doesn’t solve the integration issue.
I picked video b/c it’s easiest to demonstrate this principle with that, but it applies to everywhere. It’s why you have to reprompt language models multiple times to create a comprehensive work product- LLMs have the knowledge in there, but the explicit prompting and feedback is required to ensure it knows how to chain the various steps together.
Therefore, while Llama 4 Scout's 10 million token context window is a remarkable technical achievement that significantly expands the potential scope of information a model can access in one go, it's crucial to distinguish this capacity from the ability to perform deep, multi-step reasoning or synthesis across that entire context. Successfully retrieving isolated facts (the strength tested by NIHAS) is fundamentally different from integrating and analyzing complex interactions or narratives spanning long sequences. Mastering this deeper form of long-context understanding and integration, beyond simple retrieval, remains a key frontier and an ongoing challenge for the next generation of AI models and will require work that is orthogonal to the increasing max context window that our models can process.

Advanced Post-Training Pipeline (SFT → RL → DPO):
This stage creates a better balance between reasoning/coding capabilities and conversational alignment compared to heavier SFT approaches.
Lightweight SFT focused on hard examples (heavy pruning of easy data).
Intensive Online RL focused on hard prompts using a dynamic curriculum and mixed-capability batches.
Lightweight DPO for final polishing/corner cases. Required significant infrastructure upgrades (asynchronous RL framework) for Behemoth (~10x efficiency gain).
Llama also proactively embraces quantization (FP8, INT4) using optimized libraries like FBGEMM, making high-performance inference feasible.
In the deep dive, we will touch thes following points-
Trend 1: Mixture of Experts — Llama 4’s Efficiency Leap
1.1 Understanding MoE: Moving beyond dense models to sparse activation with specialized experts and routers for computational efficiency.
1.2 Llama 4’s MoE Architecture: A detailed look at the interleaved MoE/dense layers, high-performance SwiGLU experts, Maverick’s unique shared + routed expert design, and the
scatter_addmethod for combining outputs.
Trend 2: Native Multimodality — Integrating Vision Natively
2.1 From “Bolted-On” to Built-In: Contrasting older multimodal approaches with Llama 4’s integrated design.
2.2 Llama 4’s Early Fusion Strategy: How text and visual tokens (from an enhanced, co-trained MetaCLIP encoder) are merged and processed jointly.
2.3 Enabling Deeper Understanding: The role of cross-modal attention and joint pre-training in grounding language and vision.
Trend 3: Ultra-Long Context — Pushing Sequence Length Boundaries
3.1 The Challenges of Long Sequences: Examining the computational, memory, and positional awareness hurdles.
3.2 RoPE as a Foundation: Understanding how Rotary Positional Embeddings encode relative positions.
3.3 iRoPE — Scout’s 10M Token Solution: Detailing the Interleaved RoPE approach combining RoPE and NoPE layers.
3.4 Key Supporting Technologies: The necessity of targeted long-context training, dynamic attention scaling, and optimized kernels.
Trend 4: Advanced Post-Training — Refining Reasoning and Alignment
4.1 A Revamped Recipe (SFT → RL → DPO): How Meta moved beyond standard fine-tuning to better preserve complex capabilities.
4.2 Innovations in RL at Scale: Detailing the focus on hard prompts, dynamic filtering, mixed-capability batches, and the asynchronous infrastructure built for models like Behemoth.
Concluding Thoughts and Embracing My Inner American.
PS- I wrote this breakdown jacked to the tits on decaf coffee (gifted by one of the cultists, thank you Chengpei you absolute gigachad) and my rage at having to run evals on all these new LLMs/Techniques while house-hunting in NYC (my lease expires April 30th, please help me find an apartment, I will worship you). If you think I got something wrong, missed something, or have other comments- don’t hesitate to share/reach out.
I put a lot of work into writing this newsletter. To do so, I rely on you for support. If a few more people choose to become paid subscribers, the Chocolate Milk Cult can continue to provide high-quality and accessible education and opportunities to anyone who needs it. If you think this mission is worth contributing to, please consider a premium subscription. You can do so for less than the cost of a Netflix Subscription (pay what you want here).

I provide various consulting and advisory services. If you‘d like to explore how we can work together, reach out to me through any of my socials over here or reply to this email.
Trend 1: Llama finally adopts Mixture of Experts
Our new Llama 4 models are our first models that use a mixture of experts (MoE) architecture. In MoE models, a single token activates only a fraction of the total parameters. MoE architectures are more compute efficient for training and inference and, given a fixed training FLOPs budget, delivers higher quality compared to a dense model…
As an example, Llama 4 Maverick models have 17B active parameters and 400B total parameters. We use alternating dense and mixture-of-experts (MoE) layers for inference efficiency. MoE layers use 128 routed experts and a shared expert. Each token is sent to the shared expert and also to one of the 128 routed experts. As a result, while all parameters are stored in memory, only a subset of the total parameters are activated while serving these models. This improves inference efficiency by lowering model serving costs and latency — Llama 4 Maverick can be run on a single NVIDIA H100 DGX host for easy deployment, or with distributed inference for maximum efficiency.
1. The Problem with “Dense” Models and an Introduction to MoE
Traditional Deep Learning models are “dense.” When processing information, every single piece of input data flows through every single parameter of the model in each layer. This works well when we’re dealing with peanut models, but as models get bigger to learn more knowledge (like Llama 4 Behemoth with ~2 trillion parameters!), processing every input through every parameter becomes incredibly computationally expensive.
MoE offers a smarter, sparse alternative. Instead of one massive processing unit (like the Feed-Forward Network or FFN in a standard Transformer layer).

Typically, an MoE layer has:
Multiple “Experts”: A collection of smaller, specialized processing units that handle different tasks.
A “Router”: A small, efficient decision-maker. Its job is to look at each incoming piece of data (a token representing part of the input text or image) and quickly decide which expert(s) are best suited to handle it.
Selective Processing: Based on the router’s decision, the data is sent only to the chosen expert(s). The other experts remain inactive for that specific piece of data, ensuring efficiency.
Combining Insights: The results from the active experts are then combined to form the final output for that piece of data.
The routing mechanism (which experts are selected) and how their outputs are combined have some interesting implications. For example, you might choose Hard MoE (where the router makes discrete choices, sending each token to one or a few specific experts) or Soft MoE (where experts might be activated partially or their outputs blended based on learned weights). There’s a whole discussion around this that is worth studying for MoE, but we won’t touch upon that here. I’m simply flagging it since understanding these routing strategies is important further reading for anyone more serious about implementing MoE architectures.
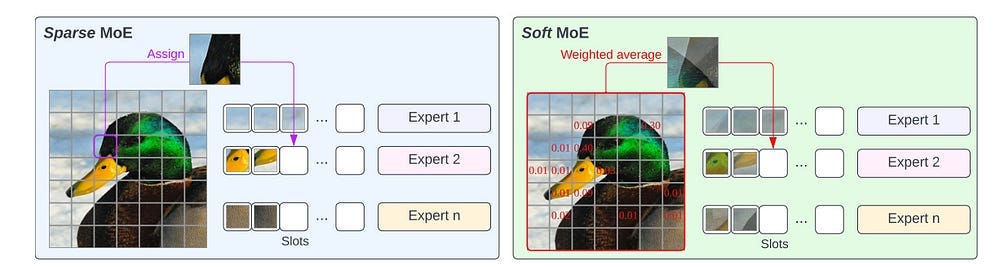
Whatever you pick, MoEs end up with the same result. The model can have a vast total number of parameters (its “potential knowledge” stored across all experts), but for any given input, only a small fraction is actively used. This drastically reduces the computation needed for inference (running the model), making huge models practical.
MoEs also tend to work well with Distillation and Compression, which is a big positive for efficient training and inference. A huge consideration for a company looking to deploy GenAI for billions of users across perhaps trillions of interactions.
With this introduction, let’s do a look at Llama 4’s special way of inference-
How Llama 4 Implements MoE: A Closer Look
Interleaved Layers: MoE layers aren’t used everywhere. They replace the standard FFN block in some layers, likely alternating with dense FFN layers. This mix probably helps balance performance and stability.

Expert Design: Each expert isn’t just a basic network; it uses the sophisticated SwiGLU (Sigmoid-Weighted Linear Unit) activation function, carried over from previous Llama models.
What SwiGLU does: Instead of just transforming data through an activation function (Activation(W1(x))), SwiGLU uses two paths. One path (W1(x)) goes through an activation (SiLU), while a parallel path (W3(x)) learns a gate — essentially deciding how much of the activated signal should pass through for each element.
These paths are multiplied, allowing the network to dynamically control information flow much more effectively than simpler activations. A final projection (W2) brings it back to the required dimension.
Why it matters: Using SwiGLU ensures each expert can perform complex, nuanced computations, contributing to the overall quality of the MoE layer.

The Router (Making the Choice):
The Mechanism: The router is implemented as a Linear Layer (self.router_DE). A linear layer is a fundamental neural network component that performs a weighted sum of its inputs. Here, it takes the token’s representation and calculates a “score” for each expert, essentially predicting how suitable each expert is for this specific token. It learns this prediction ability during training.
Selection: The model then uses a torch.topk operation to pick the expert(s) with the highest scores.
The Maverick model uses a Hybrid Expert model. This is a key detail that is worth talking about
Shared Expert: Maverick includes a standard FFN block (self.shared_expert) that every single token passes through.
Routed Expert(s): In addition to the shared expert, each token is also sent to the one expert chosen by the router (since Maverick likely uses top-k=1).
This is a zoomed in version of the earlier illustration to focus on this approach

I can’t remember seeing an explanation for this, but I can speculate. This design seems to be a way to bring in “cross-domain collaboration” (from the shared expert, which is likely going to link ideas across areas) while also getting specialized processing from the best-suited routed expert. This should bring similar benefits as Soft MoE (since the Shared Expert could be seen as the blended expert) while ensuring the expert(s) still gets the “loudest voice”.
Combining the Outputs (Scatter Add): How do you merge the output from the shared expert (which processed all tokens) and the routed expert (which only processed some tokens at specific original positions)? Simple addition won’t work correctly. This is where the scatter_add comes in. An overview of the process is given below-

To get more detailed, here’s how it works-
The scatter_add_ Operation: This specialized operation takes the outputs calculated by the routed experts and intelligently adds them back to the main tensor containing the shared expert’s output, but only at the correct positions. It uses the router_indices (which remembers which original token position was sent to which expert) to ensure expert X’s output is added only to the slot corresponding to the token it processed. Some real precision sniping going on here. The snippet (from moe.py is given below)-

shared_expert and stored in out_aD. Separately, the outputs for the sparsely activated routed experts are calculated (routed_out_egg_D). The key operation is scatter_add_, which precisely adds the routed expert outputs back into the out_aD tensor. This uses router_indices (reshaped into router_indices_EG_D) to map each routed expert output back to its original token's position, ensuring correct aggregation. Finally, the result is potentially reduced across model parallel groups before being returned in the expected sequence shape.This approach aggregates the sparse computations back into the dense sequence representation without mixing up outputs for different tokens.
I would imagine all of this was much more difficult to track and load-balance effectively, but the results seem to justify the effort. Meta had to really deliver big after Mistral, DeepSeek, and Qwen models had thrown down the gauntlet, especially as Q1 is coming to an end. And they really delivered
Let’s move on to the next section. Another huge hint for the future of AI systems.
Inside Llama 4’s Native Multimodality
Multimodality might not turn too many heads anymore, since everyone is transitioning to it. However, what makes L4’s variant important to study is how it’s done: Llama 4 is natively multimodal. Let’s take a second to understand this and the implications it has.
Native vs Bolted On MultiModality
Historically, adding vision to powerful language models often involved a “bolted-on” approach. You might take an excellent text AI and pair it with a separate image-understanding AI. The image model would analyze a picture and pass a summary or numerical representation (an embedding) to the text model. The text model, in turn, would reason based only on that second-hand report, never having truly “seen” the image itself. This approach is still common with Audio and Video, since the embedding models for these two modalities aren’t as well established yet.
While functional, this approach is a lot like following a sport by reading after-match reports on OneFootball and watching the YouTubers- details always get lost in translation. Stats and analysis might show you that Manchester United is a generational shitshow, but it is only when you watch them play that you can appreciate just how masterfully they’ve turned self-sabotage into an art form.
As a slight, but very tangent, now that Antony, our Messiah, has started to hit some fiendish numbers, we must ask a very important question-
I look forward to hearing your responses.
Back to AI things. Let’s understand Native MultiModality. FYI, this is the same principle used by Gemini, which is what enabled them to become more multimodal than anyone else. Other LLMs (such as 4o) copied this once they saw how elite Gemini’s multi-modality was. So it’s very important to study it.
Llama 4’s Built-In Vision
Llama 4 models are designed with native multimodality, incorporating early fusion to seamlessly integrate text and vision tokens into a unified model backbone. Early fusion is a major step forward, since it enables us to jointly pre-train the model with large amounts of unlabeled text, image, and video data. We also improved the vision encoder in Llama 4. This is based on MetaCLIP but trained separately in conjunction with a frozen Llama model to better adapt the encoder to the LLM.
Its ability to process images isn’t an add-on; it’s woven into the core fabric of the model’s architecture right from the start. This “native” approach is achieved through a technique called Early Fusion.
Here’s how it works:
Parallel Processing: When you provide Llama 4 with both text and an image, it processes them simultaneously. Text is broken down into familiar tokens by the tokenizer.
The Eyes of Llama 4: Images are fed into a sophisticated Vision Encoder. Meta didn’t just grab an off-the-shelf component; they used an enhanced encoder based on their previous MetaCLIP work. Crucially, this vision encoder was specifically trained in conjunction with a Llama language model. This ensures the visual information is translated into a format — a sequence of “visual tokens” — that the language part of the model can readily understand and integrate.
Merging Streams: The sequence of text tokens and the sequence of visual tokens are then combined into a single, unified stream of information. Special marker tokens likely signal where image information begins and ends within this stream.
Unified Reasoning: This combined sequence flows through the Llama 4 Transformer backbone — the same powerful attention mechanisms and MoE layers process both text and visual tokens together.

Enabling this requires a true heavyweight, a technique that will feed families for generations to come.
A Brief Introduction to Cross-Modal Attention
We trained both of our models on a wide variety of image and video frame stills in order to give them broad visual understanding, including of temporal activities and related images. This enables effortless interaction on multi-image inputs alongside text prompts for visual reasoning and understanding tasks. The models were pre-trained on up to 48 images, and we’ve tested in post-training with good results up to eight images.
-The use of video frame stills probably captures “dynamic” pictures as opposed to stills, which will expand the range of multi-modality.
The magic of early fusion happens within the attention mechanism. Because text and visual tokens are processed side-by-side, the model can learn direct relationships between them. The word “skateboard” in a prompt can directly “attend” to the visual tokens representing the skateboard in the image. Conversely, a striking visual feature can influence how the model interprets the accompanying text. This cross-modal attention allows for a much deeper level of grounding and reasoning than possible with separate models.
This integrated architecture is powered by Llama 4’s joint pre-training. It learned language and vision correlations from the ground up, trained on an enormous dataset (part of the 30 trillion+ token mix) containing vast amounts of text and images (and even video). It wasn’t taught text first and vision later; it learned to connect pixels and words simultaneously.

All in all this follows the same theme as the MoE section. We’re going with harder techniques to really maximize performance. I think Llama 4 is as much an engineering accomplishment as it is a research one, maybe even more so.
Next, the section that’s probably catching the most attention-
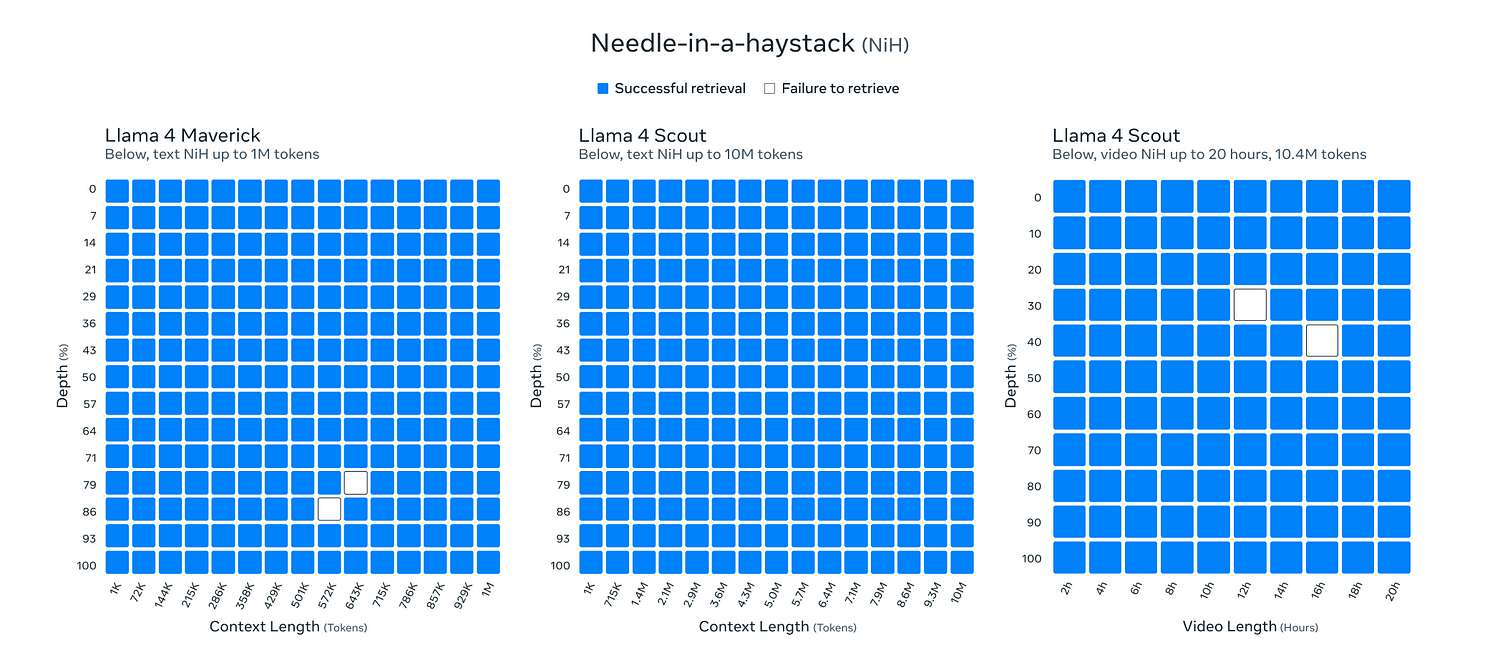
Llama 4’s Leap into Ultra-Long Context
If you’re reading my work, you likely don’t need the basics on what Context Windows are or why they’re important. So let’s skip the preludes and get into how Meta gets the long context performance down. To begin with
The Bottleneck: Why Long Context is Hard
Handling long sequences in standard Transformer models presents significant hurdles:
Computational Cost: The core self-attention mechanism, where every token looks at every other token, scales quadratically (O(N²)) with sequence length N. This rapidly becomes computationally infeasible for millions of tokens.
Positional Awareness: Transformers inherently don’t understand word order. They need explicit positional information. Simple methods struggle over vast distances, failing to capture relative positioning accurately.
Memory Usage: Attention requires storing intermediate Key and Value states (the KV cache) for all preceding tokens. This cache grows linearly with context length, demanding massive amounts of GPU memory.
Information Decay: Models can struggle to recall or utilize information from the middle of very long inputs, a phenomenon known as being “lost in the middle.”
Dealing with these problems and scaling Long Context has been the purview of one very special technique-

How Language Models Know Where Tokens Are — Rotary Positional Embeddings (RoPE)
To understand Llama 4’s breakthrough, we first need to grasp how models like Llama typically handle position. Instead of just adding a fixed number representing position to each token’s embedding (absolute encoding), Llama models (since the first generation) use Rotary Positional Embeddings (RoPE).
The Problem RoPE Solves: We need a way to encode position such that the model understands not just where a token is (token #5 vs token #500), but also its position relative to other tokens (token #500 is 10 steps after token #490). Relative positioning is crucial for understanding syntax and dependencies. Furthermore, we want the encoding to potentially generalize to sequence lengths longer than those seen during training.
RoPE’s Elegant Idea: RoPE encodes positional information by rotating the token embeddings in a specific way within the attention mechanism. It doesn’t add positional information; it modifies the Query (Q) and Key (K) vectors used in attention based on their absolute position.
How it Works (Conceptual): Imagine each token’s embedding vector is partially divided into pairs of dimensions. RoPE treats each pair as coordinates on a 2D plane (like a complex number). Based on the token’s absolute position (m), it applies a rotation to these coordinates. The angle of rotation depends on the position m and the specific dimension pair (different pairs rotate at different frequencies theta_k). Mathematically, it’s equivalent to multiplying by e^(i * m * theta_k).

The Magic of Relative Position: When the model calculates the attention score between a Query at position m and a Key at position n, the dot product calculation naturally simplifies so that the resulting attention score depends only on the relative difference (m-n) and the content embeddings, not the absolute positions m and n separately. The rotations effectively cancel out the absolute position dependence in the score calculation.
Benefits: This approach elegantly encodes relative positions, has shown good performance, and possesses better extrapolation properties (generalizing to longer sequences) compared to some absolute or other relative encoding methods. Previous Llama models leveraged RoPE successfully for contexts up to 128K tokens (Llama 3.1 405B).
This is what sets the base for Scout’s breakthrough.
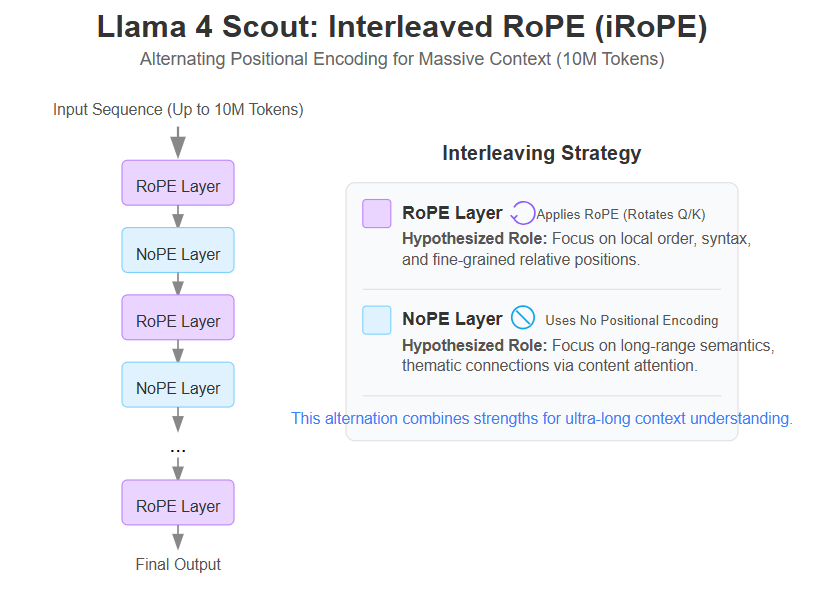
Llama 4 Scout’s Leap: Interleaved RoPE (iRoPE) for 10M Tokens
While standard RoPE is effective, reaching 10 million tokens required something special. Meta introduces iRoPE (Interleaved RoPE) as the core technology behind Scout’s massive context window.
Instead of applying RoPE consistently in every layer’s attention mechanism, iRoPE alternates layers:
Some layers utilize standard RoPE, presumably maintaining the fine-grained understanding of local token order and relative positioning that RoPE excels at.
Other layers employ NoPE (No Positional Encoding) within their attention calculation.
Why mix RoPE and NoPE layers? Meta hasn’t published the details, but a lack of knowledge has never stopped me from baselessly speculating with confidence:
RoPE Layers: Focus on precise local context, syntax, and relative ordering within shorter spans.
NoPE Layers: Better suited for aggregating semantic information or identifying long-range dependencies where exact relative position is less critical than thematic connection. They might avoid potential noise or complexities introduced by positional signals over vast distances by relying solely on content-based attention in these layers.

Interleaving allows the model to leverage both precise local ordering (via RoPE) and broad semantic aggregation (via NoPE), potentially creating a more robust and efficient representation for ultra-long sequences.
Do I have any grounds for saying this? Not really. But remember kids, never let silly things like scientific humility and “the truth” stand in the way of the truly important things like pretending to be smart to get some extra brownie points. If there is one piece of advice I would give to anyone for success, this would be it. There is no faster way to success than the magic words “Just Trust Me Bro”.

While iRoPE is cool, every Bakugo needs a Kirishima to become the best sparkly boi he can be. Let’s note some important side characters to long context-
Supporting Technologies for Ultra-Long Context
Achieving 10 million tokens isn’t just about iRoPE; it’s a team effort:
Targeted Training: Llama 4 Scout was explicitly trained to handle long sequences. It underwent pre-training and post-training phases using context lengths up to 256,000 tokens. This large-scale training is essential for teaching the model to effectively utilize its architectural advantages and generalize to even longer inputs. Reminds me very of AlphaGeometry using very long proof steps to get the AI to think better.
Dynamic Attention Scaling: Meta mentions using “inference time temperature scaling of attention.” From what I understand, it dynamically adjusts the magnitude of the Query vectors based on their position in the sequence. Queries looking further back in the extremely long context get scaled up slightly more (based on a logarithmic function). This helps with very long sequences (like Scout’s 10M tokens). Standard attention mechanisms can struggle to maintain focus (“attention fading”). This scaling helps counteract that fading, essentially “sharpening” the attention scores derived from the Query vectors. It allows the NoPE layers, which lack direct positional cues, to still effectively prioritize and attend to important information even across vast distances within the context window.
Optimized Kernels: Underlying computations must rely on highly efficient attention implementations (like FlashAttention variants) to manage the memory and compute demands. Once again, note the emphasis on quantization. Also, why I rated a Clika, a model compression startup, very highly in my list of best early-stage startups. There is a lot of money to be made in doing this well-

The implications of long context
This has a lot of people hyped. Some even forecast the death of RAG and other related techniques.
While groundbreaking, using a 10M token context isn’t trivial. The memory requirements for the KV cache remain significant, and inference time naturally increases with input length. Additionally, long context scaling also has other struggles- transparency, testing, making meaningful improvements, etc, which significantly hold back potential in deployment. This will undeniably open a lot of doors, but it’s worth remembering that one-shot generation, no matter how powerful the model, has been much weaker than multi-generations for a reason. We’ll cover this in more detail in a separate article.
For now, let me reiterate that the nature of working over long contexts is very different from what needle in a haystack actually measures.

Don’t let this diminish the capability, though. This is undeniably a great accomplishment, and I can’t wait to see improvements on this.
Moving on, let’s cover the post-training (the training is mostly straightforward).

How Llama 4 was Post Trained
Post-training a model with two trillion parameters was a significant challenge too that required us to completely overhaul and revamp the recipe, starting from the scale of data. In order to maximize performance, we had to prune 95% of the SFT data, as opposed to 50% for smaller models, to achieve the necessary focus on quality and efficiency. We also found that doing lightweight SFT followed by large-scale reinforcement learning (RL) produced even more significant improvements in reasoning and coding abilities of the model. Our RL recipe focused on sampling hard prompts by doing pass@k analysis with the policy model and crafting a training curriculum of increasing prompt hardness. We also found that dynamically filtering out prompts with zero advantage during training and constructing training batches with mixed prompts from multiple capabilities were instrumental in providing a performance boost on math, reasoning, and coding. Finally, sampling from a variety of system instructions was crucial in ensuring that the model retained its instruction following ability for reasoning and coding and was able to perform well across a variety of tasks.
Pre-training imbues Large Language Models with vast knowledge, but it’s the post-training phase that transforms this raw potential into helpful, safe, and aligned AI assistants. For the Llama 4 family, Meta didn’t just scale up pre-training; they significantly revamped their post-training pipeline, deploying advanced techniques to sharpen reasoning, enhance conversational ability, and ensure responsible behavior, particularly for complex models like the multi-trillion parameter Llama 4 Behemoth.
Beyond Standard Fine-Tuning: A New Recipe
Meta identified that traditional post-training methods, especially heavy Supervised Fine-Tuning (SFT), could inadvertently stifle a model’s exploratory potential during Reinforcement Learning (RL), potentially leading to suboptimal performance in demanding domains like coding and math. To counteract this, Llama 4 employs a refined three-stage pipeline:
Lightweight, Quality-Focused SFT: The initial instruction-following stage uses a highly pruned dataset. By removing 50% (for Maverick) to 95% (for Behemoth) of “easy” examples (identified using model-based judges), Meta ensures SFT focuses only on challenging, high-signal data. This preserves the model’s core reasoning capabilities, preventing over-fitting to simple conversational patterns before the more exploratory RL phase. If you paid attention, this was an approach that Meta has been echoing for a few years-

Intensive Online Reinforcement Learning (RL): This is the core refinement stage. Llama 4’s RL focuses intensely on improving performance on hard prompts, identified using methods like pass@k analysis across coding, math, and reasoning tasks. Key innovations include:
Continuous Online Learning: An iterative cycle where the model trains on hard prompts, then generates new data, which is filtered for medium-to-hard difficulty, creating a dynamic learning curriculum.
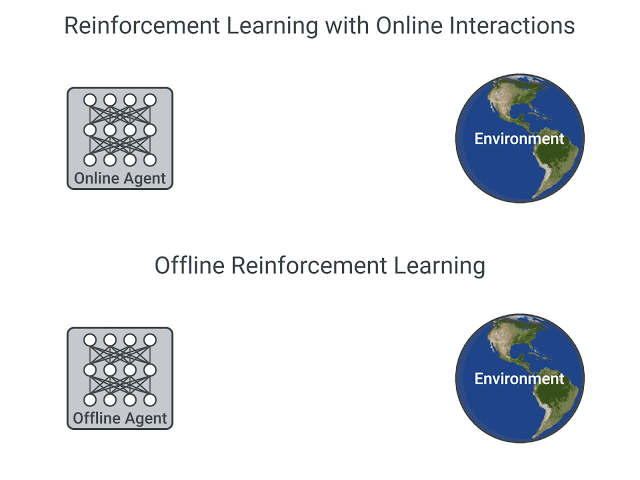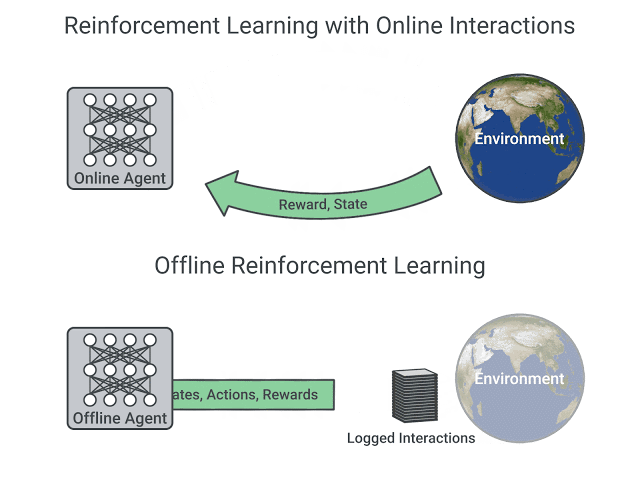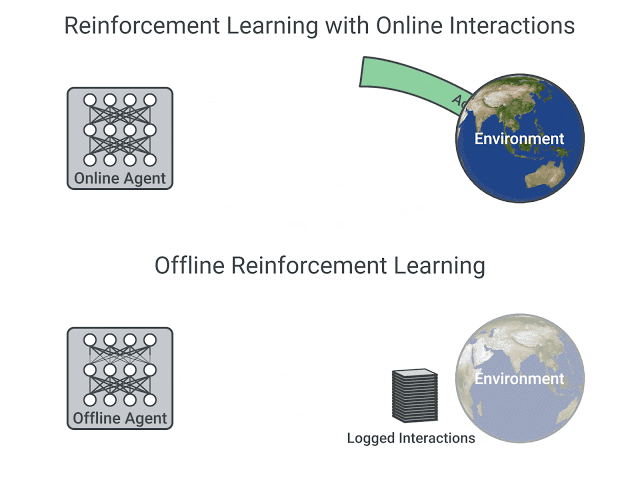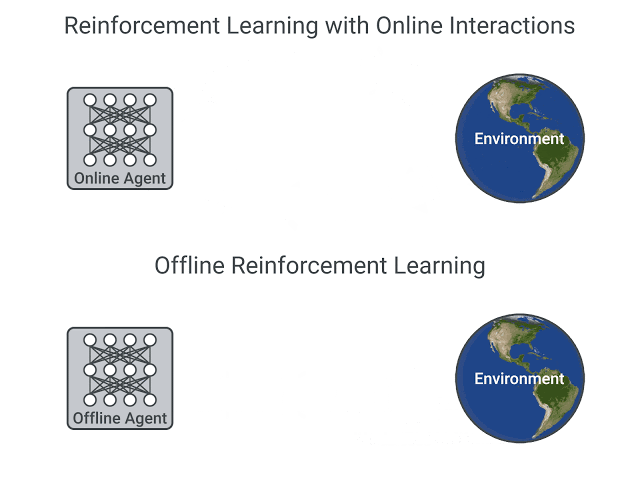
Targeted Filtering: Actively removing prompts where the model already performs well (“zero advantage”) to concentrate compute on areas needing improvement.
Mixed-Capability Batches: Training batches blend prompts targeting diverse skills to ensure balanced development across coding, reasoning, and conversation.
Diverse Instructions: Using varied system prompts maintains the model’s fundamental instruction-following flexibility.
Lightweight Direct Preference Optimization (DPO): Applied last, DPO provides a final polish. It’s used sparingly, likely to address specific stylistic preferences, response formatting, or safety-related corner cases without constraining the complex abilities developed during RL.
Scaling RL to Trillions of Parameters
Applying this advanced RL strategy to the massive Llama 4 Behemoth necessitated significant infrastructure innovation. Meta developed a fully asynchronous online RL training framework. This system decouples components like the policy and reward models, allowing flexible allocation across GPU resources based on computational demand, moving beyond traditional synchronous distributed training limits. Combined with optimized parallelization for MoE architectures, this yielded an impressive ~10x improvement in training efficiency, making sophisticated RL feasible at the frontier scale.
Unlike the previous Llama releases, which I personally felt were important but profoundly uninspiring (which is why we never covered them), Llama 4 is a fresh model that really pushes the boundaries of LLMs forward. Zucky Chan and the rest of the Meta crew have really channeled their inner Bald Eagles to snatch back the Open Source crown from the Europeans and Chinese. A feat of great historical importance. I’m going to get a cheeseburger to celebrate.
Your move, Commies.
Thank you for being here and I hope you have a wonderful day,
Stay classy, unlike United’s back four.
Dev <3
If you liked this article and wish to share it, please refer to the following guidelines.
That is it for this piece. I appreciate your time. As always, if you’re interested in working with me or checking out my other work, my links will be at the end of this email/post. And if you found value in this write-up, I would appreciate you sharing it with more people. It is word-of-mouth referrals like yours that help me grow. The best way to share testimonials is to share articles and tag me in your post so I can see/share it.

Reach out to me
Use the links below to check out my other content, learn more about tutoring, reach out to me about projects, or just to say hi.
Small Snippets about Tech, AI and Machine Learning over here
AI Newsletter- https://artificialintelligencemadesimple.substack.com/
My grandma’s favorite Tech Newsletter- https://codinginterviewsmadesimple.substack.com/
My (imaginary) sister’s favorite MLOps Podcast-
Check out my other articles on Medium. : https://rb.gy/zn1aiu
My YouTube: https://rb.gy/88iwdd
Reach out to me on LinkedIn. Let’s connect: https://rb.gy/m5ok2y
My Instagram: https://rb.gy/gmvuy9
My Twitter: https://twitter.com/Machine01776819
Brilliant Devanash!!!🥳🍾👏
Devansh, check out 2 Gold in FiDi. I’m on my third year here and recommend it highly. Great neighborhood, near all subways and plenty of services near by.